GPT-4o lyd-API: En samlet /chat/completions endpoint-udvidelse, der accepterer Opus-kodet lyd (og tekst) input og returnerer syntetiseret tale eller transskriptioner med konfigurerbare parametre (model=gpt-4o-audio-preview-<date>, speed, temperature) til batch- og streaming-stemmeinteraktioner.
Grundlæggende information om GPT-4o Audio
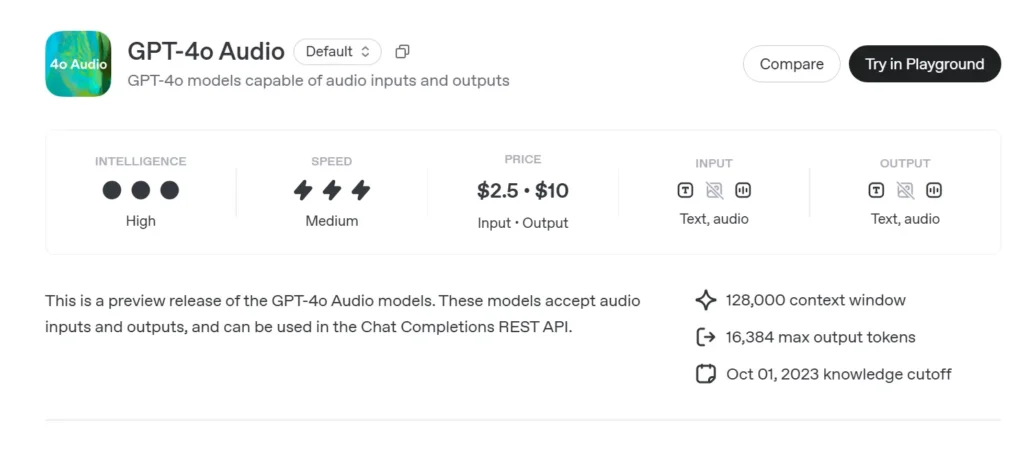
GPT-4o lydforhåndsvisning (gpt-4o-audio-preview-2025-06-03) er OpenAIs nyeste talecentreret stor sprogmodel gjort tilgængelig via standarden Chat Completions API snarere end realtidskanalen med ultralav latenstid. Bygget på det samme "omni"-fundament som GPT-4o, er denne variant specialiseret i højkvalitets taleinput og -output til turbaserede samtaler, indholdsoprettelse, tilgængelighedsværktøjer og agentiske arbejdsgange, der ikke kræver millisekundtiming. Den arver alle tekstræsonnementsstyrker fra GPT-4-klassemodeller, samtidig med at den tilføjer end-to-end tale-til-tale (S2S) rørledninger, deterministiske funktionskald, og den nye speed parameter til kontrol af stemmehastighed.
Kernefunktionssæt i GPT-4o Audio
• Samlet tale-til-tale-behandling – Lyd transformeres direkte til semantisk rige tokens, bearbejdes og syntetiseres igen uden eksterne STT/TTS-tjenester, hvilket giver konsistent stemmeklang, prosodi og kontekstbevarelse.
• Forbedret instruktionsfølelse – Levering af tuning i juni 2025 +19 point bestået ved 1. klasse på stemmekommandoopgaver i forhold til GPT-2024o-grundlinjen fra maj 4, hvilket reducerer hallucinationer inden for områder som kundesupport og udarbejdelse af indhold.
• Stabil værktøjsopkald – Modeloutputtene struktureret JSON der overholder OpenAI-funktionskaldsskemaet, hvilket muliggør udløsning af backend-API'er (søgning, booking, betalinger) med >95 % argumentnøjagtighed.
• speed Parameter (0.25–4×) – Udviklere kan modulere taleafspilning til langsomt læringstempo, normal fortælling eller hurtig "hørbar skimming"-tilstande, uden resyntetisering af tekst eksternt.
• Afbrydelsesbevidst turtagning – Selvom den ikke er lige så latenstidsdrevet som Realtime-varianten, understøtter forhåndsvisningen delvis streamingTokens udsendes, så snart de er beregnet, hvilket giver brugerne mulighed for at afbryde tidligt, hvis det er nødvendigt.
Teknisk arkitektur af GPT-4o
• Enkeltstabeltransformer – Ligesom alle GPT-4o-derivater anvender lydforhåndsvisningen en samlet encoder-dekoder hvor tekst og akustiske tokens passerer gennem identiske opmærksomhedsblokke, hvilket fremmer tværmodal jordforbindelse.
• Hierarkisk lydtokenisering – Rå 16 kHz PCM → log-mel patches → grove akustiske koder → semantiske tokensDenne flertrinskompression opnår 40–50× båndbreddereduktion samtidig med at nuancer bevares, hvilket muliggør klip på flere minutter pr. kontekstvindue.
• NF4 kvantiserede vægte – Konklusionen afgives kl. 4-bit Normal-Float præcision, halvering af GPU-hukommelse sammenlignet med fp16 og opretholdelse 70+ streaming RTF (realtidsfaktor) på A100-80 GB-noder.
• Streamingopmærksomhed og KV-caching – Roterende indlejringer med glidende vinduer opretholder kontekst i over ~30 sekunders tale, samtidig med at de bevarer O(L) hukommelsesforbrug, ideelt til podcast-editorer eller læsehjælpemidler.
Versionsstyring og navngivning — Forhåndsvisning af spor med datostemplede builds
| Identifier | Kanal | Formål | Slip Dato | Stabilitet |
|---|---|---|---|---|
| gpt-4o-lyd-forhåndsvisning-2025-06-03 | Chat Completions API | Turbaserede lydinteraktioner, agentopgaver | Juni 03 2025 | Eksempel (feedback er velkommen) |
Nøgleelementer i navnet:
- gpt-4o – Omni multimodal familie.
- lyd – Optimeret til talebrug.
- forhåndsvisning – API-kontrakten kan udvikle sig; ikke GA endnu.
- 2025-06-03 – Øjebliksbillede af træning og implementering for reproducerbarhed.
Sådan kalder du GPT-4o Audio API API fra CometAPI
GPT-4o Audio API API-priser i CometAPI:
- Input-tokens: $2 / M-tokens
- Output-tokens: $8 / M-tokens
Påkrævede trin
- Log ind på cometapi.com. Hvis du ikke er vores bruger endnu, bedes du registrere dig først
- Få adgangslegitimations-API-nøglen til grænsefladen. Klik på "Tilføj token" ved API-tokenet i det personlige center, få token-nøglen: sk-xxxxx og send.
- Hent url'en til dette websted: https://api.cometapi.com/
Brugsmetoder
- Vælg "
gpt-4o-audio-preview-2025-06-03"slutpunkt" til at sende anmodningen og angive anmodningsteksten. Anmodningsmetoden og anmodningsteksten er hentet fra vores hjemmesides API-dokumentation. Vores hjemmeside tilbyder også Apifox-tests for din bekvemmelighed. - Erstatte med din faktiske CometAPI-nøgle fra din konto.
- Indsæt dit spørgsmål eller din anmodning i indholdsfeltet – det er det, modellen vil reagere på.
- . Behandle API-svaret for at få det genererede svar.
For information om modeladgang i Comet API, se venligst API-dok.
For modelprisoplysninger i Comet API, se venligst https://api.cometapi.com/pricing.
API-arbejdsgang — Chat-fuldførelser med lyddele og funktionskroge
- Input Format -
audio/*MIME ellerbase64WAV-stykker indlejret imessages[].content. - Outputindstillinger -
•mode: "text"→ ren tekst til undertekster.
•mode: "audio"→ returnerer en streaming Opus- eller µ-law-nyttelast med tidsstempler. - Funktionskald - Tilføje
functions:skema; modellen udsenderrole: "function"med JSON-argumenter; udvikleren udfører værktøjskaldet og sender eventuelt resultatet tilbage i pipeform. - Rate Kontrol - Indstil
voice.speed=1.25for at accelerere afspilningen; sikre områder 0.25–4.0. - Token-/lydgrænser – 128 k kontekst (~4 min tale) ved opstart; 4096 lydtokens / 8192 teksttokens hvad end der først kommer.
Eksempelkode og API-integration
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Highlights:
- model:
"gpt-4o-audio-preview-2025-06-03" - lyd nøgle ind bruger besked til at sende binær strøm
- hastighed: Betjeningselementer stemmehastighed mellem langsom (0.5) og hurtig (2.0)
- temperatur: Vægt kreativitet vs konsistens
Tekniske indikatorer — Latens, kvalitet, nøjagtighed
| metric | Lydforhåndsvisning | GPT-4o (kun tekst) | Delta |
|---|---|---|---|
| Første token-forsinkelse (1-skud) | 1.2 s gns | 0.35 s | +0.85 sekunder |
| MOS (Taleens naturlighed, 5-point) | 4.43 | — | — |
| Instruktionsoverholdelse (stemme) | 92 % | 73 % | +19 pp |
| Funktionskald Arg Nøjagtighed | 95.8 % | 87 % | +8.8 pp |
| Ordfejlrate (implicit STT) | 5.2 % | n / a | — |
| GPU-hukommelse / stream (A100-80GB) | 7.1 DK | 14 GB (fp16) | -49 % |
Benchmarks udført via streaming af Chat Completions, batchstørrelse = 1.
Se også GPT-4o Realtids-API