Claude Haiku 4.5 er en formålsoptimeret sprogmodel i den mindre klasse fra Anthropic, udgivet i midten af oktober 2025. Den er positioneret som en hurtig, lavpris-mulighed i Claude-serien, der bevarer stærke evner til opgaver som kodning, agentorkestrering og interaktive “computer-use”-arbejdsgange, samtidig med at den muliggør langt højere gennemløb og lavere enhedsomkostning for virksomhedsudrulninger.
Nøglefunktioner
- Hastighed og omkostningseffektivitet: Haiku 4.5 beskrives som mere end dobbelt så hurtig som Sonnet 4 og omkring en tredjedel af prisen for Sonnet 4 (og meget billigere end Opus), hvilket gør den attraktiv til skaleret brug.
- Udvidet tænkning: Den første Haiku-model, der understøtter udvidet tænkning (opsummeret / indflettet tanke, konfigurerbare tænkningsbudgetter) for dybere flertrinsresonnering med afbalanceret latenstid.
- Værktøjer og computer use: Fuld understøttelse af Claude-værktøjer (bash, kodekørsel, teksteditor, websøgning og automation af “computer-use”). Designet til agentiske arbejdsgange og sub-agent-arkitekturer.
- Stort kontekstvindue: 200k token kontekstvindue (med 1M-kontekstmuligheder tilgængelige på større modeller som beta for andre modelklasser).
Tekniske detaljer
- Træningsdata og cutoff: Haiku 4.5 er trænet på en proprietær blanding af offentlige og licenserede data med en trænings-cutoff omkring februar 2025.
- Udvidet tænkning (en hybrid resonneringstilstand) understøttes, så modellen kan bytte latenstid for dybere resonnering efter behov.
- Kontekstvindue ved udgivelse er 200.000 tokens, og modellen er eksplicit kontekstbevidst (den sporer, hvor meget af vinduet der er brugt).
- Ydeevne / gennemløb: Tidlige community-rapporter og Anthropic-tests nævner meget høj OTPS (output-tokens/sek.) og anekdotiske hastigheder omkring ~200+ tokens/sek. i nogle interne/tidlige tests — langt hurtigere end mange sammenlignelige modeller i mellemklassen.
Benchmark-resultater
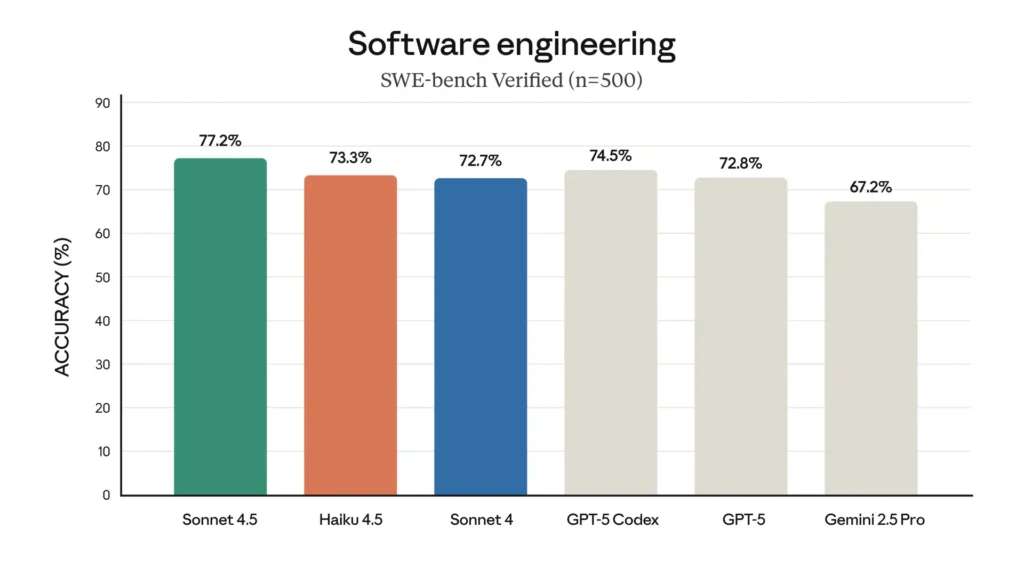
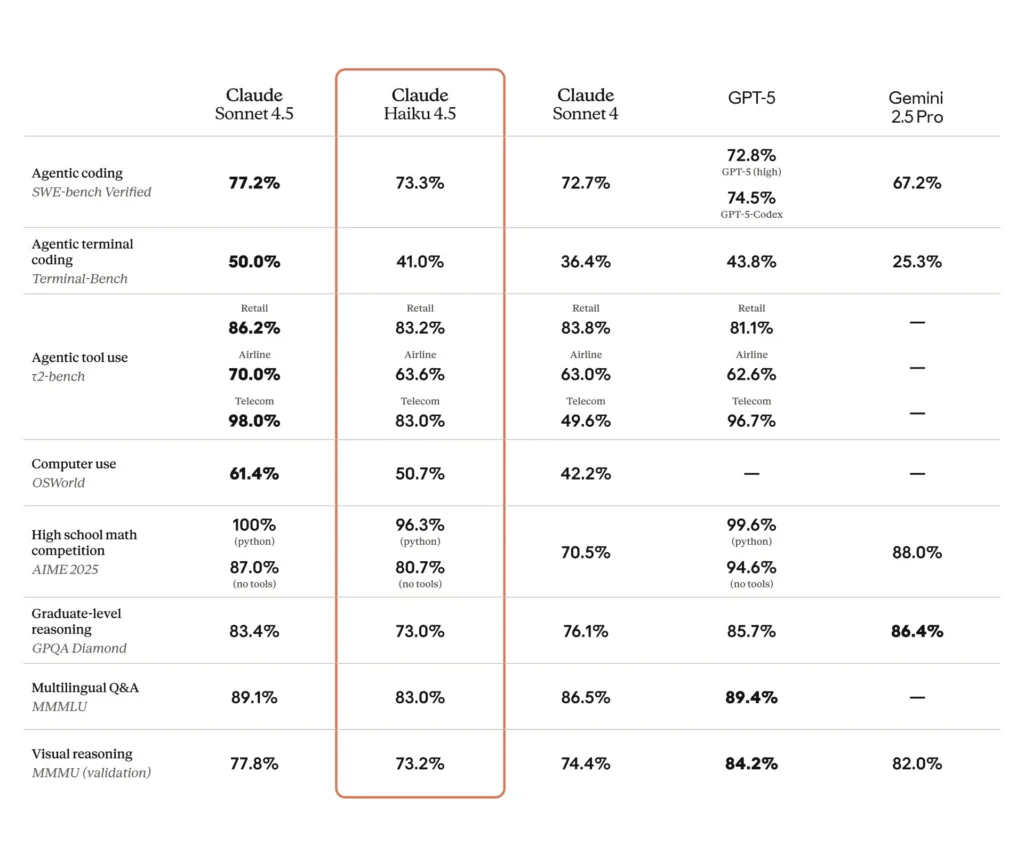
SWE-Bench (kodning): Haiku 4.5 opnåede ~73.3% på SWE-Bench Verified — et resultat, som Anthropic fremhæver som placerende Haiku 4.5 blandt verdens bedste kodningsmodeller i sin klasse.
Terminal / kommandolinje / værktøjstests: Anthropic rapporterede ~41% på Terminal-Bench (fokuseret på kommandolinjen) og sammenlignelige resultater med Sonnet 4 og flere konkurrerende mellemklasse-frontiermodeller på mange værktøjsbrugs-benchmarks.
Instruktionsfølgning og dias-tekst: interne eksempler fra Anthropic hævder, at Haiku 4.5 overgik tidligere modeller på nogle instruktionsfølgningstests (f.eks. generering af dias-tekst: 65% vs 44% for en tidligere premium-model i deres benchmark).
Automation i virkeligheden / agentopgaver: tredjepartsevalueringer og tidlige brugere rapporterer konkurrencedygtige succesrater på automatiserede UI/agent-opgaver (for eksempel OSWorld-lignende eller agent-benchmarks, der rapporterer ≈50% succes på kompleks automation i nogle tests), hvilket viser anvendelighed til skalerede arbejdsgange, omend med ikke-trivielle fejlfunktioner.
Begrænsninger og sikkerhedsnoter
- Ikke en frontier-model: Anthropic klassificerer eksplicit Haiku 4.5 som ikke grænsefremskydende; den er optimeret til effektivitet frem for at presse den absolutte state of the art. (Anthropic)
- Lejlighedsvis adfærd ved følsomme emner: i nogle videnskabelige/biosikkerhedsrelaterede prompts returnerer Haiku 4.5 til tider højniveauinformation med forbehold i stedet for strenge afslag; Anthropic markerer det som et område under løbende forbedring.
- Udvidet tænkning kan ændre adfærd (den øger sommetider asymmetri i svar).
Anbefalede anvendelsestilfælde
- Agentisk kodning og multi-agent-orkestrering: hurtige sub-agenter, iterativ koderefaktorering, autotests og patchgenerering. (Velegnet.)
- Realtids-, højvolumen-kundeprocesser: chatassistenter, intern automation hvor pris pr. forespørgsel betyder noget. (Velegnet.)
- Værktøjsaktiverede arbejdsgange og computerkontrol: automatisering af GUI/CLI-opgaver, dokumentarbejdsgange og toolchains, hvor lav latenstid hjælper. (Velegnet.)
- Ikke anbefalet (uden kontroller): selvstændige roller, der kræver frontierniveau videnskabeligt sekvensdesign eller høj-sikkerhed biosikkerhedsopgaver. (Udvis forsigtighed.)