

Den 17. juni 2025 udgav den Shanghai-baserede AI-leder MiniMax (også kendt som Xiyu Technology) officielt MiniMax-M1 (herefter "M1") - verdens første åbne, storskala hybrid-opmærksomhedsræsonnementsmodel. Ved at kombinere en Mixture-of-Experts (MoE)-arkitektur med en innovativ Lightning Attention-mekanisme opnår M1 brancheførende ydeevne i produktivitetsorienterede opgaver, der konkurrerer med de bedste closed source-systemer, samtidig med at den opretholder en uovertruffen omkostningseffektivitet. I denne dybdegående artikel undersøger vi, hvad M1 er, hvordan det fungerer, dets definerende funktioner og praktisk vejledning i adgang til og brug af modellen.
Hvad er MiniMax-M1?
MiniMax-M1 repræsenterer kulminationen af MiniMaxAI's forskning i skalerbare, effektive opmærksomhedsmekanismer. M01-iterationen bygger på MiniMax-Text-1-fundamentet og integrerer lynopmærksomhed med et MoE-framework for at opnå hidtil uset effektivitet under både træning og inferens. Denne kombination gør det muligt for modellen at opretholde høj ydeevne, selv når den behandler ekstremt lange sekvenser – et centralt krav til opgaver, der involverer omfattende kodebaser, juridiske dokumenter eller videnskabelig litteratur.
Kernearkitektur og parametrisering
I sin kerne udnytter MiniMax-M1 et hybrid MoE-system, der dynamisk ruter tokens gennem en delmængde af ekspert-undernetværk. Mens modellen omfatter i alt 456 milliarder parametre, aktiveres kun 45.9 milliarder for hver token, hvilket optimerer ressourceforbruget. Dette design er inspireret af tidligere MoE-implementeringer, men forfiner routinglogikken for at minimere kommunikationsoverhead mellem GPU'er under distribueret inferens.
Lynopmærksomhed og understøttelse af lang kontekst
Et definerende træk ved MiniMax-M1 er dens lynraske opmærksomhedsmekanisme, som drastisk reducerer den beregningsmæssige byrde af selvopmærksomhed for lange sekvenser. Ved at approksimere opmærksomhedsmatricer gennem en kombination af lokale og globale kerner, reducerer modellen FLOP'er med op til 75% sammenlignet med traditionelle transformere ved behandling af 100K token-sekvenser. Denne effektivitet accelererer ikke kun inferens, men åbner også døren for håndtering af kontekstvinduer på op til en million tokens uden uoverkommelige hardwarekrav.
Hvordan opnår MiniMax-M1 effektiv beregning?
MiniMax-M1's effektivitetsforbedringer stammer fra to primære innovationer: dens hybride Mixture-of-Experts-arkitektur og den nye CISPO-forstærkningslæringsalgoritme, der bruges under træning. Sammen reducerer disse elementer både træningstid og inferensomkostninger, hvilket muliggør hurtig eksperimentering og implementering.
Hybrid blanding af eksperter-ruting
MoE-komponenten anvender 32 ekspert-undernetværk, der hver især specialiserer sig i forskellige aspekter af ræsonnement eller domænespecifikke opgaver. Under inferens vælger en lært gating-mekanisme dynamisk de mest relevante eksperter for hver token og aktiverer kun de undernetværk, der er nødvendige for at behandle inputtet. Denne selektive aktivering reducerer redundante beregninger og reducerer kravene til hukommelsesbåndbredde, hvilket giver MiniMax-M1 en betydelig fordel i omkostningseffektivitet i forhold til monolitiske transformermodeller.
CISPO: En ny algoritme til forstærkningslæring
For yderligere at styrke træningseffektiviteten har MiniMaxAI udviklet CISPO (Clipped Importance Sampling with Partial Overrides), en RL-algoritme, der erstatter vægtopdateringer på tokenniveau med clipping baseret på vigtighedssampling. CISPO afhjælper problemer med vægteksplosioner, der er almindelige i store RL-opsætninger, accelererer konvergens og sikrer stabil forbedring af politikker på tværs af forskellige benchmarks. Som et resultat gennemføres MiniMax-M1's fulde RL-træning på 512 H800 GPU'er på bare tre uger og koster cirka $534,700 - en brøkdel af de rapporterede omkostninger for sammenlignelige GPT-4-træningskørsler.
Hvad er præstationsstandarderne for MiniMax-M1?
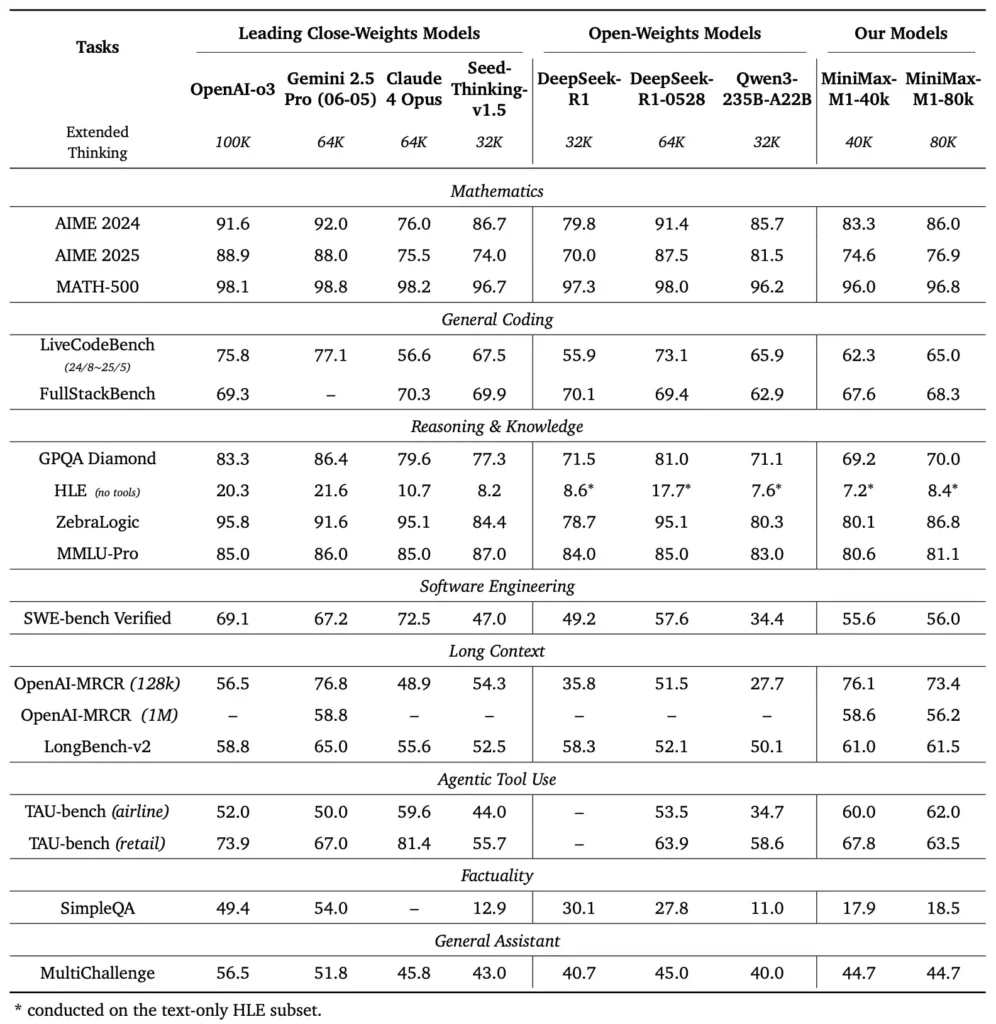
MiniMax-M1 udmærker sig på tværs af en række standard- og domænespecifikke benchmarks og demonstrerer dens dygtighed i håndtering af lang kontekstlogik, matematisk problemløsning og kodegenerering.
Langkontekst-ræsonnementsopgaver
I omfattende dokumentforståelsestests behandler MiniMax-M1 kontekstvinduer på op til 1,000,000 tokens, hvilket overgår DeepSeek-R1 med en faktor på otte i maksimal kontekstlængde og halverer beregningskravene for sekvenser på 100 tokens. På benchmarks som den udvidede kontekstevaluering af NarrativeQA opnår modellen avancerede forståelsesscorer, hvilket tilskrives dens lynraske opmærksomheds evne til effektivt at indfange både lokale og globale afhængigheder.
Softwareudvikling og værktøjsudnyttelse
MiniMax-M1 blev specifikt trænet i sandbox-baserede softwareudviklingsmiljøer ved hjælp af storstilet RL, hvilket gjorde det muligt at generere og debugge kode med bemærkelsesværdig nøjagtighed. I kodningsbenchmarks som HumanEval og MBPP opnår modellen beståelsesrater, der er sammenlignelige med eller overstiger Qwen3-235B og DeepSeek-R1, især i kodebaser med flere filer og opgaver, der kræver krydsreferencer af lange kodesegmenter. Desuden viser MiniMaxAI's tidlige demonstrationer modellens evne til at integrere med udviklerværktøjer, lige fra generering af CI/CD-pipelines til automatiske dokumentationsworkflows.
Hvordan kan udviklere få adgang til MiniMax-M1?
For at fremme udbredt anvendelse har MiniMaxAI gjort MiniMax-M1 frit tilgængelig som en open-weight-model. Udviklere kan få adgang til forudtrænede checkpoints, modelvægte og inferenskode via det officielle GitHub-arkiv.
Open-weight-udgivelse på GitHub
MiniMaxAI udgav MiniMax-M1's modelfiler og tilhørende scripts under en permissiv open source-licens på GitHub. Interesserede brugere kan klone repository'et på https://github.com/MiniMax-AI/MiniMax-M1, som indeholder checkpoints for både 40K og 80K token-budgetvarianterne, samt integrationseksempler for almindelige ML-frameworks som PyTorch og TensorFlow.
API-slutpunkter og cloudintegration
Ud over lokal implementering har MiniMaxAI indgået partnerskaber med store cloud-udbydere for at tilbyde administrerede API-tjenester. Gennem disse partnerskaber kan udviklere kalde MiniMax-M1 via RESTful-slutpunkter, med SDK'er tilgængelige for Python, JavaScript og Java. API'erne inkluderer konfigurerbare parametre for kontekstlængde, ekspertroutingtærskler og tokenbudgetter, hvilket giver brugerne mulighed for at skræddersy ydeevne til deres use cases, samtidig med at de overvåger computerforbruget i realtid.
Hvordan integrerer og bruger man MiniMax-M1 i virkelige applikationer?
At udnytte MiniMax-M1's funktioner kræver forståelse af dets API-mønstre, bedste praksis for lange kontekstprompter og strategier for værktøjsorkestrering.
Eksempel på grundlæggende API-brug
Et typisk API-kald involverer afsendelse af en JSON-nyttelast, der indeholder inputteksten og valgfrie konfigurationsoverrides. For eksempel:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Svaret returnerer en struktureret JSON med genereret tekst, statistikker over tokenbrug og routinglogfiler, hvilket muliggør finjusteret overvågning af ekspertaktiveringer.
Værktøjsbrug og MiniMax Agent
Udover kernemodellen har MiniMaxAI introduceret MiniMax Agent, et beta-agentframework, der kan kalde eksterne værktøjer – lige fra kodeudførelsesmiljøer til webscrapers – under motorhjelmen. Udviklere kan instantiere en agentsession, der kæder modelargumentation sammen med værktøjskald, for eksempel for at hente realtidsdata, udføre beregninger eller opdatere databaser. Dette agentparadigme forenkler end-to-end applikationsudvikling, hvilket gør det muligt for MiniMax-M1 at fungere som orkestrator i komplekse arbejdsgange.
Bedste praksis og faldgruber
- Hurtig konstruktion til lange konteksterOpdel input i sammenhængende segmenter, indlejr resuméer med logiske intervaller, og brug "opsummer, og ræsonnér"-strategier for at fastholde modelfokus.
- Afvejninger mellem beregning og ydeevneEksperimentér med lavere eksperttærskler eller reducerede tænkebudgetter (f.eks. 40K-varianten) til latenstidsfølsomme applikationer.
- Overvågning og styringBrug routinglogfiler og tokenstatistikker til at revidere ekspertudnyttelsen og sikre overholdelse af omkostningsbudgetter, især i produktionsmiljøer.
Ved at følge disse retningslinjer kan udviklere udnytte MiniMax-M1's styrker – omfattende konteksthåndtering og effektiv ræsonnement – samtidig med at de mindsker risici forbundet med storskala modelimplementeringer.
Hvordan bruger du MiniMax-M1?
Når M1 er installeret, kan den kaldes via simple Python-scripts eller interaktive notesbøger.
Hvordan ser et grundlæggende inferensscript ud?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Dette eksempel aktiverer varianten med et budget på 40 dollars; der skiftes til "MiniMax-AI/MiniMax-M1-80k" låser op for det fulde 80-budget ().
Hvordan håndterer du ultralange kontekster?
For input, der overstiger typiske bufferstørrelser, understøtter M1 streamingtokenisering. Brug stream=True flag i tokenizeren for at fodre tokens i bidder, og udnytte checkpoint-genstart-inferens til at opretholde ydeevne over sekvenser på millioner af tokens.
Hvordan kan du finjustere eller tilpasse M1?
Selvom de grundlæggende kontrolpunkter er tilstrækkelige til de fleste opgaver, kan forskere anvende RL-finjustering ved hjælp af CISPO-koden, der er inkluderet i repository'et. Ved at levere brugerdefinerede belønningsfunktioner - lige fra kodekorrekthed til semantisk nøjagtighed - kan praktikere tilpasse M1 til domænespecifikke arbejdsgange.
Konklusion
MiniMax-M1 skiller sig ud som en banebrydende AI-model, der flytter grænserne for forståelse og ræsonnement af sprog i lange kontekster. Med sin hybride MoE-arkitektur, lynopmærksomhedsmekanisme og CISPO-understøttede træningsprogram leverer modellen høj ydeevne på opgaver lige fra juridisk analyse til softwareudvikling, samtidig med at beregningsomkostningerne reduceres dramatisk. Takket være dens åbne version og cloud-API-tilbud er MiniMax-M1 tilgængelig for et bredt spektrum af udviklere og organisationer, der er ivrige efter at bygge næste generations AI-drevne applikationer. I takt med at AI-fællesskabet fortsætter med at udforske potentialet i modeller i store kontekster, er MiniMax-M1's innovationer klar til at påvirke fremtidig forskning og produktudvikling på tværs af branchen.
Kom godt i gang
CometAPI leverer en samlet REST-grænseflade, der samler hundredvis af AI-modeller – inklusive ChatGPT-familien – under et ensartet slutpunkt med indbygget API-nøglestyring, brugskvoter og faktureringsdashboards. I stedet for at jonglere med flere leverandør-URL'er og legitimationsoplysninger.
Til at begynde med, udforsk modellernes muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen.
Den seneste integration med MiniMax-M1 API vil snart blive vist på CometAPI, så følg med! Mens vi færdiggør upload af MiniMax-M1-modellen, kan du udforske vores andre modeller på Modeller side eller prøv dem i AI LegepladsMiniMax' seneste model i CometAPI er Minimax ABAB7-Preview API og MiniMax Video-01 API ,se til:
