

Am 17. Juni 2025 veröffentlichte der in Shanghai ansässige KI-Marktführer MiniMax (auch bekannt als Xiyu Technology) offiziell MiniMax-M1 (im Folgenden „M1“) – das weltweit erste offene, groß angelegte Hybrid-Attention-Reasoning-Modell. Durch die Kombination einer Mixture-of-Experts (MoE)-Architektur mit einem innovativen Lightning-Attention-Mechanismus erreicht M1 branchenführende Leistung bei produktivitätsorientierten Aufgaben und konkurriert mit führenden Closed-Source-Systemen bei gleichzeitig unübertroffener Kosteneffizienz. In diesem ausführlichen Artikel erläutern wir, was M1 ist, wie es funktioniert, welche Merkmale es bietet und geben praktische Hinweise zum Zugriff und zur Nutzung des Modells.
Was ist MiniMax-M1?
MiniMax-M1 stellt den Höhepunkt der Forschung von MiniMaxAI zu skalierbaren, effizienten Aufmerksamkeitsmechanismen dar. Aufbauend auf der Grundlage von MiniMax-Text-01 integriert die M1-Iteration Lightning Attention mit einem MoE-Framework, um eine beispiellose Effizienz sowohl beim Training als auch bei der Inferenz zu erreichen. Diese Kombination ermöglicht es dem Modell, auch bei der Verarbeitung extrem langer Sequenzen eine hohe Leistung aufrechtzuerhalten – eine wichtige Voraussetzung für Aufgaben mit umfangreichen Codebasen, juristischen Dokumenten oder wissenschaftlicher Literatur.
Kernarchitektur und Parametrisierung
Im Kern nutzt MiniMax-M1 ein hybrides MoE-System, das Token dynamisch durch eine Teilmenge von Experten-Subnetzwerken routet. Obwohl das Modell insgesamt 456 Milliarden Parameter umfasst, werden für jeden Token nur 45.9 Milliarden aktiviert, was die Ressourcennutzung optimiert. Dieses Design ist von früheren MoE-Implementierungen inspiriert, verfeinert jedoch die Routing-Logik, um den Kommunikationsaufwand zwischen GPUs während der verteilten Inferenz zu minimieren.
Blitzschnelle Aufmerksamkeit und Unterstützung im Langzeitkontext
Ein entscheidendes Merkmal von MiniMax-M1 ist sein Lightning-Attention-Mechanismus, der den Rechenaufwand der Selbstaufmerksamkeit bei langen Sequenzen drastisch reduziert. Durch die Approximation von Aufmerksamkeitsmatrizen durch eine Kombination aus lokalen und globalen Kerneln reduziert das Modell die FLOPs bei der Verarbeitung von 75 Token-Sequenzen um bis zu 100 % im Vergleich zu herkömmlichen Transformatoren. Diese Effizienz beschleunigt nicht nur die Inferenz, sondern ermöglicht auch die Verarbeitung von Kontextfenstern mit bis zu einer Million Token ohne übermäßige Hardwareanforderungen.
Wie erreicht MiniMax-M1 Rechenleistung?
Die Effizienzsteigerungen von MiniMax-M1 beruhen auf zwei wesentlichen Innovationen: der hybriden Mixture-of-Experts-Architektur und dem neuartigen CISPO-Reinforcement-Learning-Algorithmus, der während des Trainings verwendet wird. Zusammen reduzieren diese Elemente sowohl die Trainingszeit als auch die Inferenzkosten und ermöglichen so schnelles Experimentieren und Implementieren.
Hybrides Experten-Mix-Routing
Die MoE-Komponente nutzt 32 Experten-Subnetze, die jeweils auf unterschiedliche Aspekte des Schlussfolgerungsprozesses oder domänenspezifische Aufgaben spezialisiert sind. Während der Inferenz wählt ein erlernter Gating-Mechanismus dynamisch die relevantesten Experten für jedes Token aus und aktiviert nur die Subnetze, die zur Verarbeitung der Eingabe benötigt werden. Diese selektive Aktivierung reduziert redundante Berechnungen und den Bedarf an Speicherbandbreite, wodurch MiniMax-M1 einen erheblichen Kostenvorteil gegenüber monolithischen Transformer-Modellen bietet.
CISPO: Ein neuartiger Algorithmus für bestärkendes Lernen
Um die Trainingseffizienz weiter zu steigern, hat MiniMaxAI CISPO (Clipped Importance Sampling with Partial Overrides) entwickelt, einen RL-Algorithmus, der Gewichtsaktualisierungen auf Token-Ebene durch Clipping auf Basis von Importance Sampling ersetzt. CISPO mildert die in großen RL-Setups häufig auftretenden Gewichtsexplosionen, beschleunigt die Konvergenz und gewährleistet eine stabile Richtlinienverbesserung über verschiedene Benchmarks hinweg. Dadurch ist das vollständige RL-Training von MiniMax-M1 auf 512 H800-GPUs in nur drei Wochen abgeschlossen und kostet rund 534,700 US-Dollar – ein Bruchteil der Kosten für vergleichbare GPT-4-Trainingsläufe.
Was sind die Leistungsbenchmarks von MiniMax-M1?
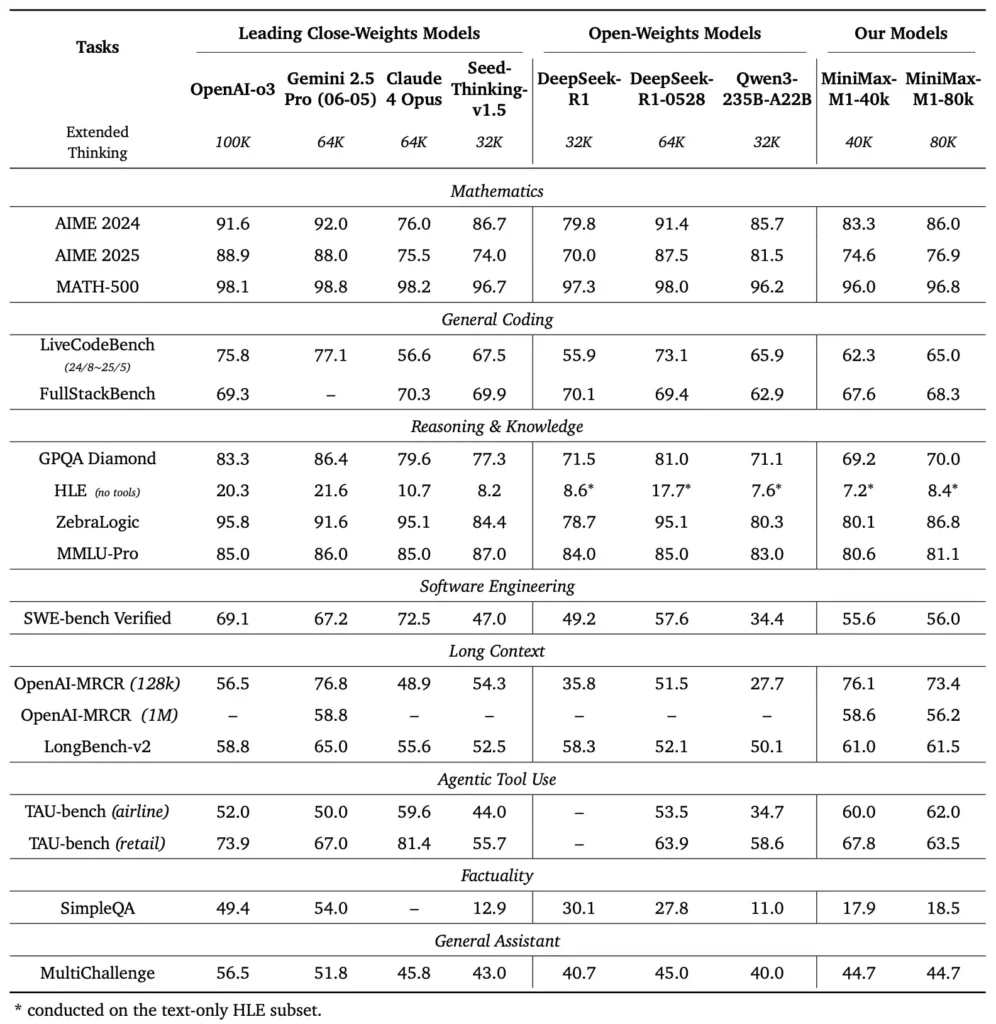
MiniMax-M1 schneidet bei einer Vielzahl von standardmäßigen und domänenspezifischen Benchmarks hervorragend ab und stellt seine Leistungsfähigkeit bei der Verarbeitung von Argumenten im langen Kontext, der Lösung mathematischer Probleme und der Codegenerierung unter Beweis.
Aufgaben zum langfristigen Denken
In umfangreichen Dokumentenverständnistests verarbeitet MiniMax-M1 Kontextfenster mit bis zu 1,000,000 Token und übertrifft DeepSeek-R1 in der maximalen Kontextlänge um das Achtfache. Der Rechenaufwand für Sequenzen mit 100 Token wird dabei halbiert. Bei Benchmarks wie der erweiterten Kontextbewertung von NarrativeQA erreicht das Modell modernste Verständniswerte, was auf die Fähigkeit seiner Lightning Attention zurückzuführen ist, sowohl lokale als auch globale Abhängigkeiten effizient zu erfassen.
Softwareentwicklung und Toolnutzung
MiniMax-M1 wurde speziell in Sandbox-Softwareentwicklungsumgebungen mit groß angelegtem RL trainiert, wodurch es Code mit bemerkenswerter Genauigkeit generieren und debuggen kann. In Code-Benchmarks wie HumanEval und MBPP erreicht das Modell Erfolgsquoten, die mit denen von Qwen3-235B und DeepSeek-R1 vergleichbar oder sogar besser sind, insbesondere bei Codebasen mit mehreren Dateien und Aufgaben, die Querverweise auf lange Codesegmente erfordern. Darüber hinaus demonstrieren die ersten Demonstrationen von MiniMaxAI die Integrationsfähigkeit des Modells in Entwicklertools, von der Generierung von CI/CD-Pipelines bis hin zu automatischen Dokumentations-Workflows.
Wie können Entwickler auf MiniMax-M1 zugreifen?
Um eine breite Akzeptanz zu fördern, hat MiniMaxAI MiniMax-M1 als Open-Weight-Modell kostenlos verfügbar gemacht. Entwickler können über das offizielle GitHub-Repository auf vortrainierte Checkpoints, Modellgewichte und Inferenzcode zugreifen.
Offene Version auf GitHub
MiniMaxAI hat die Modelldateien und die zugehörigen Skripte von MiniMax-M1 unter einer freizügigen Open-Source-Lizenz auf GitHub veröffentlicht. Interessierte Nutzer können das Repository unter https://github.com/MiniMax-AI/MiniMax-M1 klonen. Es enthält Checkpoints für die Token-Budgetvarianten mit 40 und 80 Token sowie Integrationsbeispiele für gängige ML-Frameworks wie PyTorch und TensorFlow.
API-Endpunkte und Cloud-Integration
Über die lokale Bereitstellung hinaus arbeitet MiniMaxAI mit großen Cloud-Anbietern zusammen, um verwaltete API-Dienste anzubieten. Dank dieser Partnerschaften können Entwickler MiniMax-M1 über RESTful-Endpunkte aufrufen. SDKs für Python, JavaScript und Java sind verfügbar. Die APIs enthalten konfigurierbare Parameter für Kontextlänge, Experten-Routing-Schwellenwerte und Token-Budgets. So können Benutzer die Leistung an ihre Anwendungsfälle anpassen und gleichzeitig den Rechenverbrauch in Echtzeit überwachen.
Wie kann MiniMax-M1 in reale Anwendungen integriert und verwendet werden?
Um die Funktionen von MiniMax-M1 optimal nutzen zu können, müssen Sie dessen API-Muster, Best Practices für Eingabeaufforderungen mit langem Kontext und Strategien zur Tool-Orchestrierung verstehen.
Grundlegendes API-Verwendungsbeispiel
Ein typischer API-Aufruf beinhaltet das Senden einer JSON-Nutzlast mit dem Eingabetext und optionalen Konfigurationsüberschreibungen. Beispiel:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Die Antwort gibt ein strukturiertes JSON mit generiertem Text, Token-Nutzungsstatistiken und Routing-Protokollen zurück, wodurch eine detaillierte Überwachung der Expertenaktivierungen ermöglicht wird.
Werkzeugnutzung und MiniMax Agent
Neben dem Kernmodell hat MiniMaxAI den MiniMax Agent eingeführt, ein Beta-Agenten-Framework, das externe Tools – von Code-Ausführungsumgebungen bis hin zu Web-Scrapern – im Hintergrund aufrufen kann. Entwickler können eine Agentensitzung instanziieren, die Modellbegründung mit Toolaufrufen verknüpft, um beispielsweise Echtzeitdaten abzurufen, Berechnungen durchzuführen oder Datenbanken zu aktualisieren. Dieses Agentenparadigma vereinfacht die durchgängige Anwendungsentwicklung und ermöglicht MiniMax-M1 die Koordination komplexer Workflows.
Bewährte Vorgehensweisen und Fallstricke
- Schnelles Engineering für lange Zusammenhänge: Teilen Sie Eingaben in zusammenhängende Segmente auf, fügen Sie Zusammenfassungen in logischen Abständen ein und nutzen Sie Strategien nach dem Prinzip „Zusammenfassen und dann begründen“, um den Fokus des Modells beizubehalten.
- Kompromisse zwischen Rechenleistung und Leistung: Experimentieren Sie mit niedrigeren Expertenschwellenwerten oder reduzierten Denkbudgets (z. B. der 40K-Variante) für latenzempfindliche Anwendungen.
- Überwachung und Governance: Verwenden Sie Routing-Protokolle und Token-Statistiken, um die Expertenauslastung zu prüfen und die Einhaltung der Kostenbudgets sicherzustellen, insbesondere in Produktionsumgebungen.
Durch Befolgen dieser Richtlinien können Entwickler die Stärken von MiniMax-M1 – umfassende Kontextverarbeitung und effizientes Denken – nutzen und gleichzeitig die mit der Bereitstellung groß angelegter Modelle verbundenen Risiken minimieren.
Wie verwenden Sie MiniMax-M1?
Nach der Installation kann M1 über einfache Python-Skripte oder interaktive Notizbücher aufgerufen werden.
Wie sieht ein grundlegendes Inferenzskript aus?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Dieses Beispiel verwendet die 40 k-Budget-Variante. Der Wechsel zu "MiniMax-AI/MiniMax-M1-80k" schaltet das gesamte 80-k-Reasoning-Budget frei ().
Wie gehen Sie mit extrem langen Kontexten um?
Für Eingaben, die die typische Puffergröße überschreiten, unterstützt M1 die Streaming-Tokenisierung. Verwenden Sie die stream=True Flag im Tokenizer, um Token in Blöcken einzugeben und Checkpoint-Restart-Inferenz zu nutzen, um die Leistung über Millionen-Token-Sequenzen hinweg aufrechtzuerhalten.
Wie können Sie M1 feinabstimmen oder anpassen?
Während die Basis-Checkpoints für die meisten Aufgaben ausreichen, können Forscher mithilfe des im Repository enthaltenen CISPO-Codes RL-Feintuning vornehmen. Durch die Bereitstellung benutzerdefinierter Belohnungsfunktionen – von Codekorrektheit bis hin zu semantischer Genauigkeit – können Praktiker M1 an domänenspezifische Arbeitsabläufe anpassen.
Fazit
MiniMax-M1 ist ein bahnbrechendes KI-Modell, das die Grenzen des Sprachverständnisses und der Argumentation im Langkontext erweitert. Dank seiner hybriden MoE-Architektur, dem Lightning-Attention-Mechanismus und dem CISPO-gestützten Trainingsprogramm liefert das Modell Höchstleistungen bei Aufgaben von der Rechtsanalyse bis zur Softwareentwicklung und reduziert gleichzeitig den Rechenaufwand drastisch. Dank seiner Open-Weight-Release- und Cloud-API-Angebote ist MiniMax-M1 für ein breites Spektrum an Entwicklern und Organisationen zugänglich, die KI-basierte Anwendungen der nächsten Generation entwickeln möchten. Da die KI-Community das Potenzial großkontextbasierter Modelle weiter erforscht, werden die Innovationen von MiniMax-M1 die zukünftige Forschung und Produktentwicklung der gesamten Branche beeinflussen.
Erste Schritte
CometAPI bietet eine einheitliche REST-Schnittstelle, die Hunderte von KI-Modellen – einschließlich der ChatGPT-Familie – unter einem konsistenten Endpunkt aggregiert, mit integrierter API-Schlüsselverwaltung, Nutzungskontingenten und Abrechnungs-Dashboards. Anstatt mit mehreren Anbieter-URLs und Anmeldeinformationen zu jonglieren.
Erkunden Sie zunächst die Fähigkeiten der Modelle in der Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben.
Die neueste Integration der MiniMax‑M1 API wird bald auf CometAPI erscheinen, also bleiben Sie dran! Während wir den Upload des MiniMax‑M1-Modells abschließen, erkunden Sie unsere anderen Modelle auf der Modelle-Seite oder probieren Sie sie im KI-Spielplatz. MiniMax' neuestes Modell in CometAPI sind Minimax ABAB7-Vorschau-API kombiniert mit einem nachhaltigen Materialprofil. MiniMax Video-01 API ,siehe:
