Claude Haiku 4.5 es un modelo de lenguaje de clase más pequeña y optimizado para un propósito específico de Anthropic, lanzado a mediados de octubre de 2025. Se posiciona como una opción rápida y de bajo costo dentro de la línea Claude que mantiene una gran capacidad en tareas como programación, orquestación de agentes y flujos de trabajo interactivos de “uso de computadora”, a la vez que permite un rendimiento mucho mayor y menor costo unitario para implementaciones empresariales.
Características clave
- Velocidad y eficiencia en costos: Haiku 4.5 se describe como más de dos veces más rápida que Sonnet 4 y aproximadamente un tercio del costo de Sonnet 4 (y mucho más barata que Opus), lo que la hace atractiva para usos a escala.
- Pensamiento extendido: Primer modelo Haiku que admite pensamiento extendido (pensamiento resumido/intercalado, presupuestos de pensamiento configurables) para un razonamiento de múltiples pasos más profundo equilibrando la latencia.
- Herramientas y uso de computadora: Compatibilidad total con las herramientas de Claude (bash, ejecución de código, editor de texto, búsqueda web y automatización del uso de la computadora). Diseñado para flujos de trabajo con agentes y arquitecturas de subagentes.
- Gran ventana de contexto: 200k tokens de ventana de contexto (con opciones de 1M de contexto disponibles en modelos más grandes como beta para otras clases de modelos).
Detalles técnicos
- Datos de entrenamiento y fecha de corte: Haiku 4.5 se entrenó con una mezcla propietaria de datos públicos y con licencia, con una fecha de corte de entrenamiento alrededor de febrero de 2025.
- Pensamiento extendido (un modo híbrido de razonamiento) es compatible para que el modelo pueda intercambiar latencia por razonamiento más profundo cuando se solicite.
- Ventana de contexto en el lanzamiento de 200,000 tokens, y el modelo es explícitamente consciente del contexto (rastrea cuánto de la ventana se ha utilizado).
- Rendimiento / throughput: Informes tempranos de la comunidad y pruebas de Anthropic mencionan OTPS muy altos (tokens de salida/seg) y velocidades anecdóticas alrededor de ~200+ tokens/seg en algunas pruebas internas/tempranas, mucho más rápidas que muchos modelos medios comparables.
Rendimiento en benchmarks
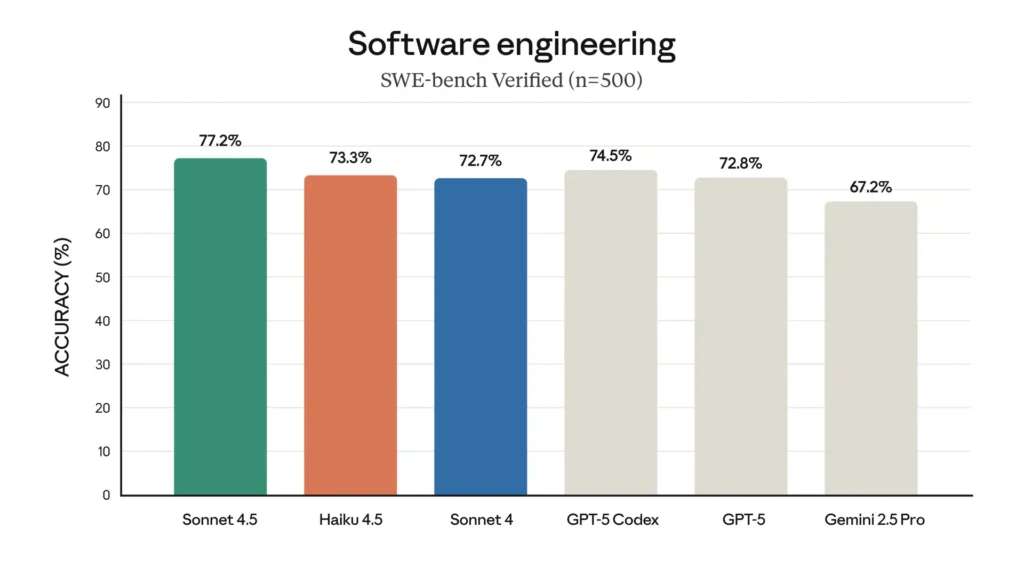
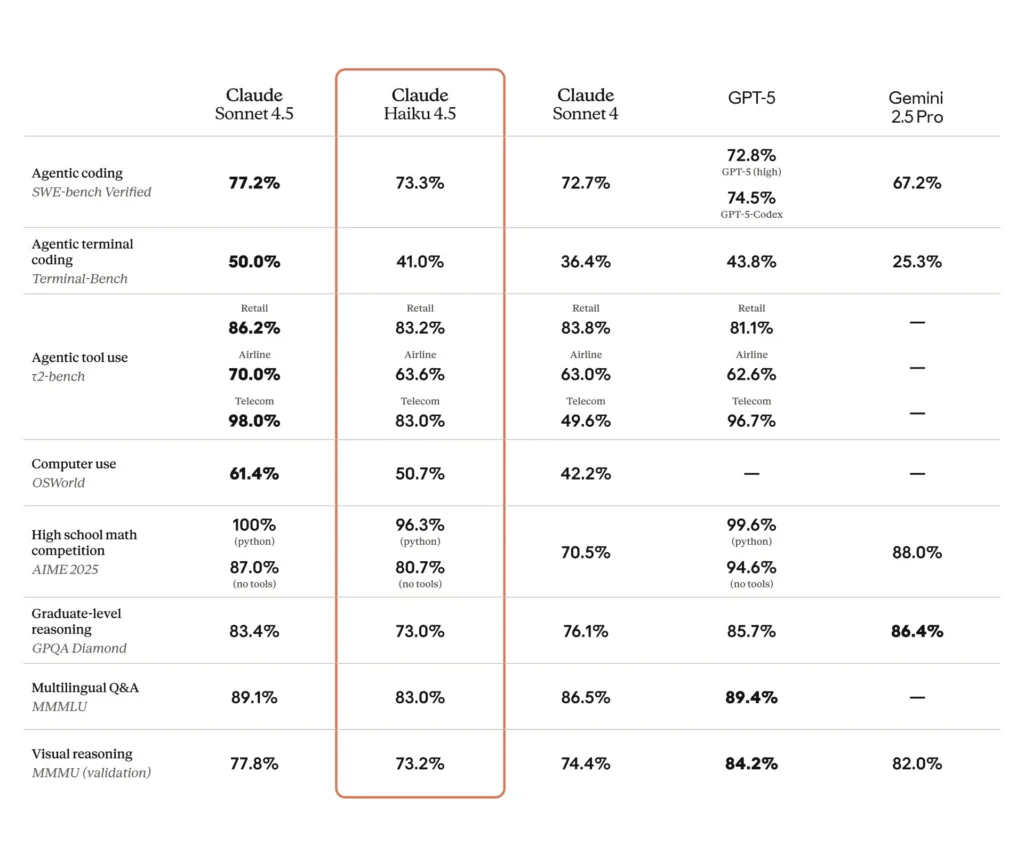
SWE-Bench (programación): Haiku 4.5 obtuvo ~73.3% en SWE-Bench Verified, un resultado que Anthropic destaca por situar a Haiku 4.5 entre los mejores modelos de programación del mundo en su clase.
Terminal / línea de comandos / pruebas de herramientas: Anthropic reportó ~41% en Terminal-Bench (enfoque en la línea de comandos) y resultados comparables a Sonnet 4 y a varios modelos frontera de gama media de la competencia en muchos benchmarks de uso de herramientas.
Seguimiento de instrucciones y texto para diapositivas: ejemplos internos de Anthropic afirman que Haiku 4.5 superó a modelos anteriores en algunas tareas de seguimiento de instrucciones (por ejemplo, generación de texto para diapositivas: 65% vs 44% frente a un modelo premium anterior en su benchmark).
Automatización del mundo real / tareas de agente: evaluaciones de terceros y primeros usuarios informan tasas de éxito competitivas en tareas automatizadas de IU/agente (por ejemplo, benchmarks tipo OSWorld o de agentes que reportan ≈50% de éxito en automatizaciones complejas en algunas pruebas), lo que demuestra utilidad para flujos de trabajo a escala aunque con modos de fallo no triviales.
Limitaciones y notas de seguridad
- No es un modelo de frontera: Anthropic clasifica explícitamente a Haiku 4.5 como no de avance fronterizo; está optimizado para la eficiencia en lugar de llevar el estado del arte absoluto. (Anthropic)
- Conducta ocasional en temas sensibles: en algunos avisos científicos / de bioseguridad, Haiku 4.5 a veces devuelve información de alto nivel con salvedades en lugar de negativas estrictas; Anthropic señala esto como un área en mejora continua.
- El pensamiento extendido puede cambiar el comportamiento (a veces aumenta la asimetría en las respuestas).
Casos de uso recomendados
- Programación con agentes y orquestación multiagente: subagentes rápidos, refactorización iterativa de código, auto-tests y generación de parches. (Buena opción.)
- Flujos en tiempo real y de alto volumen para clientes: asistentes de chat, automatización interna donde el costo por solicitud es relevante. (Buena opción.)
- Flujos habilitados por herramientas y control de computadora: automatización de tareas GUI/CLI, flujos documentales y cadenas de herramientas donde la baja latencia ayuda. (Buena opción.)
- No recomendado (sin controles): roles autónomos que requieran diseño de secuencias científicas de nivel frontera o tareas de bioseguridad de alta garantía. (Precaución.)