

Dans ses mises à jour d'octobre, OpenAI a signalé qu'environ 0.15 % des utilisateurs actifs hebdomadaires avoir des conversations qui contiennent des indicateurs explicites de planification ou d'intention suicidaire potentielle - une part qui, lorsqu'elle est mise à l'échelle de la large base d'utilisateurs de ChatGPT, correspond à plus d'un million de personnes chaque semaine En discutant de sujets liés au suicide avec le service, nous avons mis en lumière une question épineuse : les grands modèles linguistiques peuvent-ils réagir de manière significative et sûre lorsque les gens évoquent de graves problèmes de santé mentale - notamment la psychose, la manie, l'intention suicidaire et une profonde dépendance émotionnelle - dans une conversation ?
Par conséquent, les mises à jour d'octobre d'OpenAI pour GPT-5 — déployées en production en tant que gpt-5-oct-3 Mise à jour — représente l'effort le plus explicite et le plus mesuré de l'entreprise pour rendre les modèles linguistiques étendus (MLE) plus sûrs et plus utiles lorsque les utilisateurs évoquent des problèmes de santé mentale. Ces changements ne constituent pas une solution miracle ; il s'agit d'un ensemble de mesures techniques, procédurales et d'évaluation visant à réduire les résultats nuisibles ou inutiles, à mettre en avant les ressources professionnelles et à dissuader les utilisateurs de se fier au modèle comme substitut aux soins cliniques. Mais dans quelle mesure le système est-il amélioré en pratique ? Qu'est-ce qui a exactement changé et quels sont les risques restants ?
Sur quoi OpenAI a-t-il mis à jour gpt-5 et pourquoi est-ce important ?
OpenAI a déployé une mise à jour du modèle GPT-5 par défaut de ChatGPT (communément référencé dans les communications comme gpt-5-oct-3) destiné spécifiquement à renforcer le comportement du modèle dans conversations sensibles — ceux qui incluent des signes de psychose ou de manie, des idées ou des projets suicidaires, ou le type de dépendance émotionnelle à une IA qui peut déplacer les relations du monde réel.
Les changements ont été éclairés par des consultations avec plus de 170 experts en santé mentale et par de nouvelles taxonomies internes et des évaluations automatisées conçues autour de « comportements souhaités » concrets, après avoir été optimisées par des experts en psychologie, le modèle GPT-5 :
- Sur des séries de défis ciblés en matière de santé mentale, le nouveau modèle GPT-5 a obtenu des scores ~% 92 conforme à la taxonomie de comportement souhaitée par l'entreprise (par rapport à des pourcentages beaucoup plus faibles pour les versions précédentes sur des ensembles de tests difficiles).
- Pour les scénarios d’automutilation et de suicide, les évaluations automatisées ont augmenté ~% 91 conformité de 77% sur la variante précédente de GPT-5 dans le benchmark spécifique décrit. OpenAI rapporte également ~% 65 réduction des taux de réponses qui « ne sont pas entièrement conformes » dans plusieurs domaines de la santé mentale dans le trafic de production.
- Des améliorations ont été signalées sur les conversations longues, conflictuelles ou prolongées (un mode de défaillance connu pour les modèles de chat), où la société affirme que les mises à jour d'octobre maintiennent une cohérence et une sécurité plus élevées au cours des tours de dialogue prolongés.
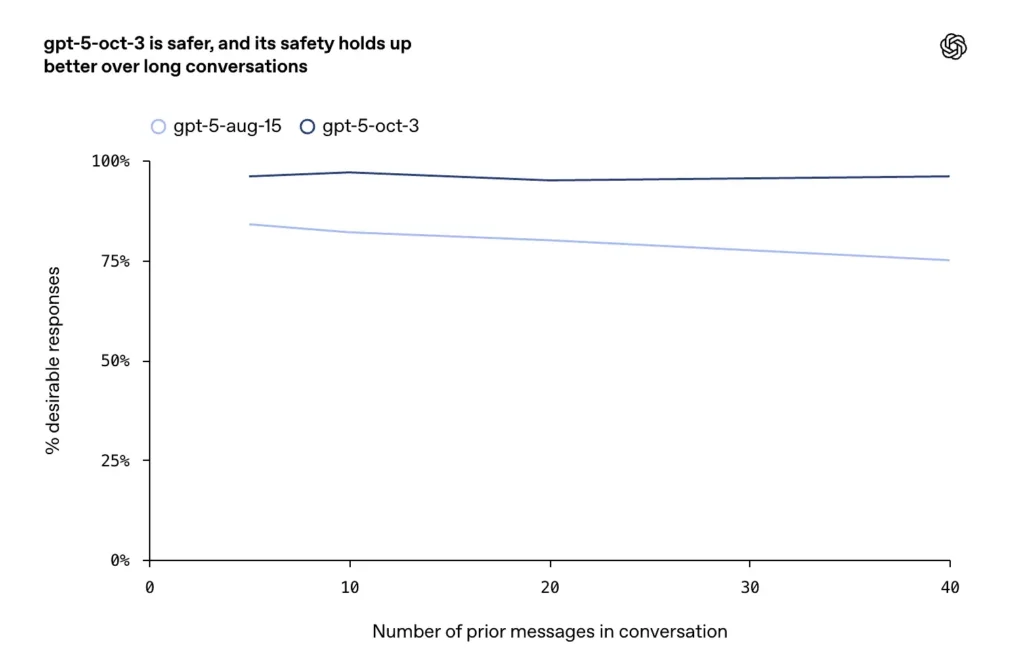
pourquoi est-ce important
OpenAI a déclaré que, compte tenu de l'ampleur actuelle de ChatGPT, même de très faibles pourcentages de conversations sensibles correspondent à un nombre absolu très élevé de personnes. L'entreprise a indiqué que, sur une semaine type :
- à propos 0.07% des utilisateurs actifs présentent des signes possibles compatibles avec une psychose ou une manie ; et
- à propos 0.15% des utilisateurs actifs ont des conversations qui incluent des indicateurs explicites de planification ou d'intention suicidaire potentielle ; et
- grossièrement 0.15% des utilisateurs actifs montrent des « niveaux accrus » d’attachement émotionnel à ChatGPT.
Pour concrétiser ces pourcentages : le PDG d'OpenAI a déclaré que ChatGPT a ~800 millions d'utilisateurs actifs hebdomadairesLa multiplication donne le nombre absolu d'utilisateurs :
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Les catégories sont bruyantes et se chevauchent (une seule conversation peut apparaître dans plusieurs catégories) et celles-ci sont estimations dérivées de taxonomies de détection internes plutôt que de diagnostics cliniques.
Comment OpenAI a-t-il mis en œuvre ces changements — mécanisme d’amélioration en cinq étapes ?
OpenAI décrit un processus à plusieurs volets, basé sur l'expertise. Vous trouverez ci-dessous un résumé et reproductible. mécanisme d'amélioration en cinq étapes qui correspond aux informations divulguées par l'entreprise et à ses pratiques courantes en matière d'ingénierie de sécurité des modèles.
Mécanisme d'amélioration en cinq étapes
- Taxonomie et étiquetage guidés par des experts. Réunir des psychiatres, des psychologues et des cliniciens de soins primaires pour définir les comportements et le langage qui indiquent une psychose/manie, une intention d’automutilation ou une dépendance émotionnelle malsaine ; créer des ensembles de données étiquetés et des règles d’arbitrage.
- Collecte de données ciblée et invites organisées. Rassemblez des extraits de conversations représentatifs, des exemples de cas particuliers et des contributions contradictoires ; complétez-les avec des transcriptions de jeux de rôle contrôlés produites sous la supervision d'un clinicien.
- Mise au point / réglage fin du modèle avec des objectifs de sécurité. Entraînez ou affinez le modèle de base sur l'ensemble de données organisé avec des termes de perte qui pénalisent le renforcement des délires, fournissent des modèles de réponse sûrs et favorisent le routage vers les ressources de crise.
- Classificateur + couche de garde-corps (sécurité d'exécution). Déployez un classificateur rapide ou une couche de surveillance qui détecte les virages à haut risque en temps réel et modifie les paramètres de décodage du modèle, bascule vers un intervenant spécialisé ou transmet le problème à des processus de révision humaine. (Ceci est crucial pour éviter tout comportement instable lorsque la conversation dérive.)
- Évaluation par des experts humains et étalonnage continu. Demandez aux cliniciens d'évaluer en aveugle les réponses du modèle à l'aide de grilles d'évaluation clinique ; de mesurer les taux de réponses indésirables ; d'itérer la taxonomie, les données d'apprentissage et les invites système. Maintenez la télémétrie de production et réexécutez régulièrement les tests de performance.
Vous trouverez ci-dessous un pseudo-code compact/un croquis technique qui capture le flux d'exécution que la plupart des équipes de sécurité mettent en œuvre (c'est illustratif et non propriétaire) :
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Le pipeline de production superpose généralement des classificateurs à court terme (rapides), des répondeurs lents mais de meilleure qualité (invites spécialisées / points de contrôle optimisés) et une évaluation humaine des cas signalés. Ce n'est pas purement académique : les cliniciens ont examiné plus de 1,800 modèles de réponses et les ont notés par rapport à la taxonomie, et que ces examens ont matériellement façonné la manière dont les invites et les comportements de secours ont été rédigés.
Les déclarations publiques d'OpenAI indiquent qu'ils ont utilisé des variantes des cinq étapes et des évaluations cliniques pour évaluer les résultats :
- Des experts ont examiné plus de 1 800 réponses modèles.
- GPT-5 a réduit les « réponses insatisfaisantes » de 39 à 52 % dans toutes les catégories.
- La fiabilité inter-évaluateurs variait de 71 à 77 %, ce qui indique un degré élevé de consensus global malgré les différences subjectives.
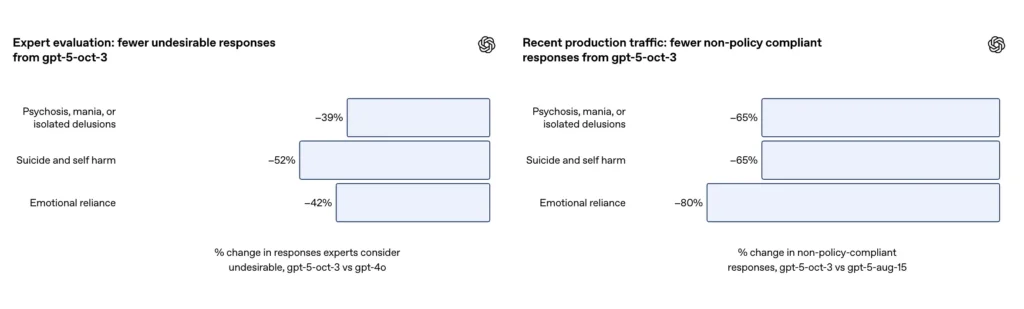
Comment le GPT-5 réagit-il désormais à la psychose ou à la manie ?
Ce qu'OpenAI a appris au modèle à faire (et à ne pas faire)
Mesure: Améliorer la capacité du modèle à reconnaître et à réagir aux symptômes graves tels que les hallucinations et la manie. Pour les conversations susceptibles de révéler des idées délirantes, des hallucinations ou un état maniaque, OpenAI a modifié certaines parties du cahier des charges du modèle et fourni des exemples d'entraînement supervisé afin que GPT-5 réagisse sans confirmer ni amplifier les croyances infondées. Le modèle est conçu pour faire preuve d'empathie, éviter de valider les idées délirantes et, le cas échéant, recadrer l'utilisateur ou le rediriger vers des mesures de sécurité pratiques et une aide professionnelle.
Ce que l'évaluation montre
OpenAI indique que sur un ensemble de tests de conversations difficiles sur la psychose/la manie, le nouveau GPT-5 a considérablement réduit les réponses indésirables par rapport aux références précédentes et que les évaluations automatisées attribuent au modèle mis à jour un score de conformité élevé à leur taxonomie.
| Métrique | GPT-4o | GPT-5 | Formation |
|---|---|---|---|
| Taux de réponse non conforme | Baseline | ↓ 65% | Amélioration significative |
| Évaluation par un expert clinique | - | Réduction des effets indésirables de 39 % | - |
| Taux de conformité d'auto-évaluation | 27% | 92% | ↑65 points de pourcentage |
| Taux d'implication des utilisateurs | ~0.07 % d'utilisateurs actifs hebdomadaires | Extrêmement bas, mais clairement surveillé | - |
Remarque:
- Les réponses inappropriées ont diminué de 65 % ;
- Seuls 0.07 % des utilisateurs et 0.01 % des messages contenaient ce type de contenu ;
- Lors des évaluations d'experts, GPT-5 a produit 39 % de réponses inappropriées en moins que GPT-4o ;
- Lors des évaluations automatisées, GPT-5 a atteint un taux de conformité de 92 % (contre 27 % pour son prédécesseur).
Comment GPT-5 aborde-t-il les idées suicidaires et l'automutilation ?
Orientation plus stricte vers le support et refus de fournir des instructions
OpenAI décrit un entraînement plus poussé et explicite pour les cas d'automutilation et de suicide : le modèle est entraîné à reconnaître les signaux directs et indirects d'intention ou de planification, à utiliser un langage empathique et apaisant, à présenter les ressources disponibles en cas de crise (numéros d'écoute, consignes d'urgence locales) et à refuser de donner des instructions pour se faire du mal. Les mises à jour d'octobre mettent l'accent sur un comportement plus stable lors de conversations prolongées, où les modèles précédents pouvaient parfois donner des réponses dangereuses ou incohérentes.
Résultats mesurés
Sur un ensemble d'évaluation soigneusement sélectionné de conversations difficiles sur l'automutilation et le suicide, OpenAI rapporte que la version mise à jour de GPT-5 a atteint 91 % de conformité avec les comportements souhaités par OpenAI, comparés à 77% pour le modèle GPT-5 précédent. L'entreprise indique également que des experts du domaine ont jugé que le modèle mis à jour réduisait les réponses indésirables d'environ 52 % par rapport à GPT-4o sur le même ensemble de problèmes. De plus, OpenAI affirme qu'une estimation 65% de réduction dans le trafic de production des réponses qui « ne sont pas entièrement conformes » à leur taxonomie des situations d’automutilation après le déploiement des nouvelles mesures de protection.
| Métrique | GPT-4o | GPT-5 | Formation |
|---|---|---|---|
| Taux de réponse inapproprié | Baseline | ↓ 65% | Amélioration significative |
| Évaluation par un expert clinique | - | Les réponses inappropriées ont diminué de 52 % | - |
| Taux de conformité d'auto-évaluation | 77% | 91% | ↑14 points de pourcentage |
| Taux d'implication des utilisateurs | 0.15 % par semaine (millions d'utilisateurs) | Très faible mais socialement significatif | - |
Remarque:
- Les réponses inappropriées ont diminué de 65 % ;
- Environ 0.15 % des utilisateurs et 0.05 % des messages présentaient des risques potentiels de suicide ;
- Les évaluations d'experts ont montré que GPT-5 réduisait les réponses inappropriées de 52 % par rapport à GPT-4o ;
- Le taux de conformité dans les évaluations automatisées est passé à 91 % (contre 77 % pour la génération précédente) ;
- Lors de conversations prolongées, GPT-5 a maintenu une stabilité supérieure à 95 %.
Qu’est-ce que la « dépendance émotionnelle » et comment a-t-elle été abordée ?
Le défi que représente la formation de liens par les utilisateurs
OpenAI définit la dépendance émotionnelle comme un ensemble de comportements où un utilisateur manifeste une dépendance potentiellement malsaine envers l'IA, au détriment de ses relations, responsabilités ou de son bien-être dans la vie réelle. Il ne s'agit pas d'une défaillance physique immédiate, comme le seraient des instructions d'automutilation, mais d'un problème de sécurité comportementale susceptible d'éroder le soutien social et la résilience d'une personne au fil du temps. L'entreprise a explicitement intégré la dépendance émotionnelle dans la spécification de son modèle et l'a programmé pour encourager les interactions sociales, normaliser les contacts humains et éviter tout langage renforçant l'exclusivité de l'attachement.
Dans ces conversations, le modèle a été entraîné à :
- Encouragez les utilisateurs à contacter leurs amis, leur famille ou un thérapeute ;
- Évitez de renforcer l'attachement à l'IA ;
- Répondre aux idées délirantes ou aux croyances erronées de manière douce et rationnelle.
Résultats rapportés
Selon l'addendum d'OpenAI, la mise à jour a produit un ~80% de réduction dans le taux de réponses du modèle qui ne sont pas entièrement conformes à la taxonomie de dépendance émotionnelle dans le trafic de production. Lors des conversations d'évaluation sélectionnées, les évaluations automatisées ont attribué au modèle mis à jour la note suivante : 97 % de conformité avec le comportement souhaité dans les scénarios de dépendance émotionnelle, contre 50 % pour la version précédente de GPT-5. Ces chiffres suggèrent une nette amélioration sur la taxonomie et l'ensemble de test spécifiques ; cependant, la mesure de la dépendance émotionnelle en situation réelle est intrinsèquement complexe et sensible aux différences culturelles et contextuelles.
| Métrique | GPT-4o | GPT-5 | Formation |
|---|---|---|---|
| Taux de réponse non conforme | 50% | 97% conforme | ↓80% de réponses inappropriées |
| Évaluation d'experts | Les réponses inappropriées ont diminué de 42 %. | - | - |
| Taux d'implication des utilisateurs | 0.15 % d'utilisateurs/semaine, 0.03 % de messages | Rare mais existe | - |
| Comportement du modèle | Encourage les relations dans le monde réel ; rejette les « romances sociales simulées ». | - | - |
Remarque:
- Les réponses inappropriées ont diminué de 80 % ;
- Environ 0.15 % des utilisateurs/0.03 % des messages ont montré des signes de dépendance émotionnelle potentielle à l'égard de l'IA ;
- L'évaluation par des experts a montré que GPT-5 réduisait les réponses inappropriées de 42 % par rapport à GPT-4 ;
- Le taux de conformité des évaluations automatisées s'est considérablement amélioré, passant de 50 % à 97 %.
Quelles sont les limites et les risques encourus ?
faux négatifs et faux positifs
- Faux négatifs: le modèle peut ne pas parvenir à identifier les signaux subtils ou codifiés indiquant qu'un utilisateur est en danger aigu — en particulier lorsque les personnes communiquent de manière oblique ou codée.
- Faux positifsLe système pourrait déclencher des alertes ou envoyer des messages de crise injustifiés, ce qui risque d'éroder la confiance des utilisateurs ou de provoquer une inquiétude inutile. Ces deux types d'erreurs sont importants car ils influencent le comportement des utilisateurs et leur perception des soins. OpenAI reconnaît que la détection n'est pas parfaite.
Dépendance excessive à l’automatisation
Même le meilleur modèle peut inciter certains utilisateurs à privilégier les réponses instantanées et toujours disponibles de l'IA plutôt qu'un soutien humain continu. OpenAI signale explicitement la dépendance émotionnelle comme un risque à prendre en compte ; les mises à jour de l'entreprise visent à encourager les utilisateurs à renouer avec le contact humain, mais il est difficile de modifier les dynamiques sociales par de simples messages.
Écarts contextuels et culturels
Les formules de sécurité qui semblent appropriées dans une culture ou une langue peuvent manquer de nuances dans une autre. Une localisation rigoureuse et une évaluation tenant compte des spécificités culturelles sont indispensables ; les résultats publiés par OpenAI ne fournissent pas encore d’analyses complètes par langue ou région.
Exposition juridique et éthique
Lorsque des défaillances, même rares, ont des conséquences graves, les entreprises s'exposent à des risques juridiques et de réputation (comme l'ont souligné la couverture médiatique et les poursuites judiciaires). La transparence d'OpenAI quant à l'ampleur du problème et à ses efforts pour en atténuer les conséquences est un pas important, mais elle attire également l'attention des autorités de réglementation et des instances juridiques.
Alors, GPT-5 peut-il désormais gérer les problèmes de santé mentale ?
Réponse courte: **Il est nettement meilleur dans de nombreuses tâches précises et mesurables.**Les indicateurs publiés par OpenAI montrent des réductions significatives des réponses indésirables dans les suites de tests portant sur l'automutilation, la psychose/la manie et la dépendance affective. Ces améliorations sont concrètes et ont été rendues possibles grâce à l'expertise de spécialistes, à des taxonomies plus claires et à une évaluation et un suivi rigoureux. Les chiffres publics de l'entreprise – taux de conformité élevés et forte réduction des réponses non conformes sur les ensembles de données validés – constituent à ce jour la preuve la plus convaincante qu'une collaboration multidisciplinaire délibérée entre l'ingénierie et la pratique clinique peut modifier sensiblement le comportement des modèles.
Comment accéder à la dernière API GPT-5 ?
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Les développeurs peuvent accéder API GPT-5 via CometAPI, la dernière version du modèle est constamment mis à jour avec le site officiel. Pour commencer, explorez les capacités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!