Claude Haiku 4.5 est un modèle de langage de classe plus petite, optimisé pour un usage spécifique, proposé par Anthropic, sorti à la mi-octobre 2025. Il se positionne comme une option rapide et peu coûteuse dans la gamme Claude, qui préserve de fortes capacités sur des tâches comme le codage, l’orchestration d’agents et les workflows interactifs d’« utilisation de l’ordinateur », tout en permettant un débit bien plus élevé et un coût unitaire inférieur pour les déploiements d’entreprise.
Principales caractéristiques
- Vitesse et efficacité coûts: Haiku 4.5 est décrit comme plus de deux fois plus rapide que Sonnet 4 et coûtant environ un tiers de Sonnet 4 (et bien moins cher qu’Opus), ce qui le rend attractif pour une utilisation à grande échelle.
- Raisonnement étendu: Premier modèle Haiku à prendre en charge le raisonnement étendu (pensée résumée / entrelacée, budgets de réflexion configurables) pour un raisonnement multi-étapes plus profond tout en équilibrant la latence.
- Outils et utilisation de l’ordinateur: Prise en charge complète des outils Claude (bash, exécution de code, éditeur de texte, recherche web et automatisation de l’utilisation de l’ordinateur). Conçu pour des workflows agentiques et des architectures de sous-agents.
- Grande fenêtre de contexte: Fenêtre de contexte de 200k jetons (avec des options de contexte 1M disponibles sur des modèles plus grands en bêta pour d’autres classes de modèles).
Détails techniques
- Données d’entraînement et coupure: Haiku 4.5 a été entraîné sur un mélange propriétaire de données publiques et sous licence, avec une coupure d’entraînement autour de février 2025.
- Le raisonnement étendu (un mode de raisonnement hybride) est pris en charge afin que le modèle puisse échanger de la latence contre un raisonnement plus profond lorsqu’il est sollicité.
- La fenêtre de contexte au lancement est de 200,000 jetons, et le modèle est explicitement sensible au contexte (il suit la part de la fenêtre déjà utilisée).
- Performances / débit: Les premiers retours de la communauté et les tests d’Anthropic citent un OTPS (jetons de sortie/sec) très élevé et des vitesses anecdotiques autour de ~200+ jetons/sec dans certains tests internes/précoces — bien plus rapide que de nombreux modèles comparables de milieu de gamme.
Performances de référence
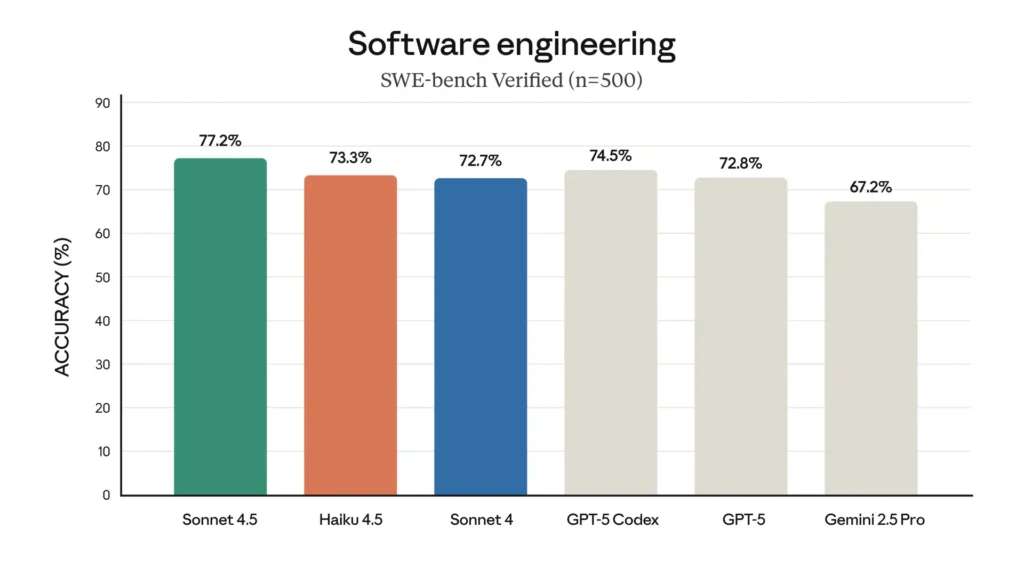
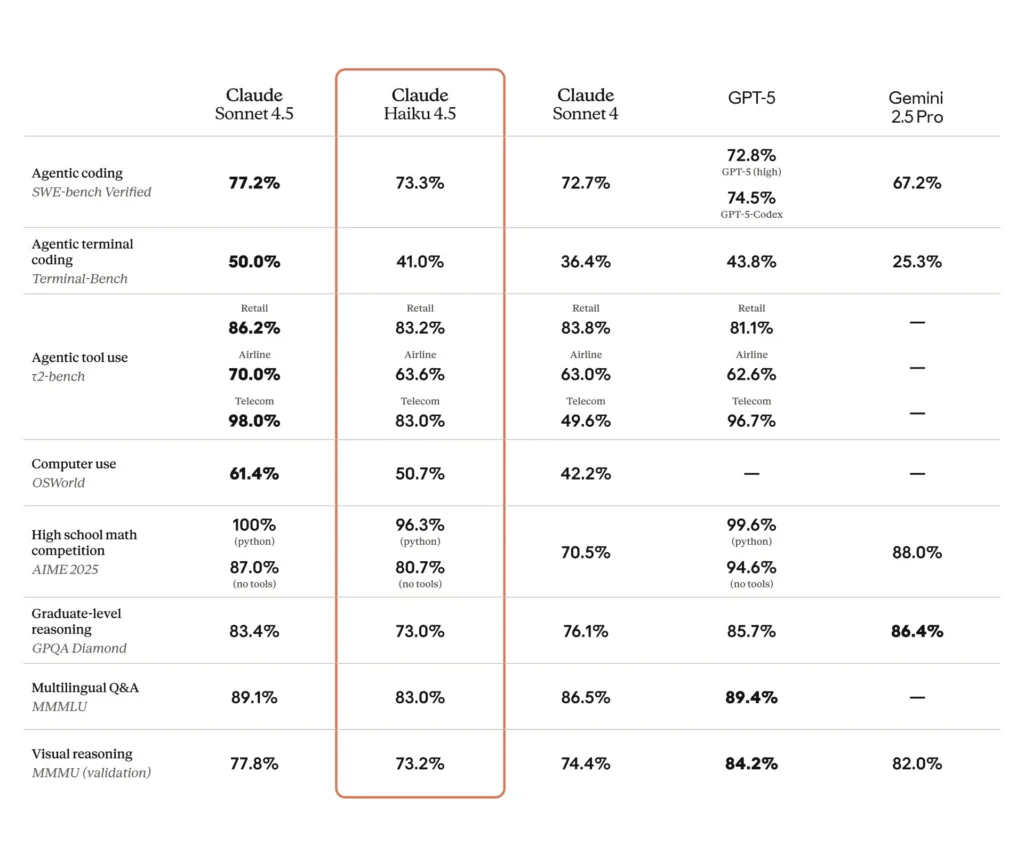
SWE-Bench (codage): Haiku 4.5 a obtenu ~73.3% sur SWE-Bench Verified — un résultat qu’Anthropic met en avant comme plaçant Haiku 4.5 parmi les meilleurs modèles de codage de sa catégorie.
Terminal / ligne de commande / tests d’outils: Anthropic a rapporté ~41% sur Terminal-Bench (axé ligne de commande) et des résultats comparables à Sonnet 4 et à plusieurs modèles concurrentiels de milieu de gamme sur de nombreux benchmarks d’utilisation d’outils.
Suivi d’instructions et texte de diapositives: des exemples internes d’Anthropic indiquent que Haiku 4.5 a surpassé les modèles précédents sur certaines tâches de suivi d’instructions (par ex., génération de texte de diapositives: 65% contre 44% pour un modèle premium antérieur dans leur benchmark).
Automatisation réelle / tâches d’agents: des évaluations tierces et des adopteurs précoces rapportent des taux de réussite compétitifs sur des tâches d’automatisation d’UI/d’agents (par exemple, des benchmarks de type OSWorld rapportant ≈50% de succès sur des automatisations complexes dans certains tests), montrant son utilité pour des workflows à l’échelle malgré des modes d’échec non négligeables.
Limitations et notes de sécurité
- Pas un modèle de pointe: Anthropic classe explicitement Haiku 4.5 comme non avant-gardiste; il est optimisé pour l’efficacité plutôt que pour repousser l’état de l’art. (Anthropic)
- Comportement occasionnel sur des sujets sensibles: pour certaines invites scientifiques / liées à la biosécurité, Haiku 4.5 renvoie parfois des informations de haut niveau avec des réserves plutôt que des refus stricts; Anthropic signale ce point comme étant en amélioration continue.
- Le raisonnement étendu peut modifier le comportement (il augmente parfois l’asymétrie des réponses).
Cas d’usage recommandés
- Codage agentique et orchestration multi-agents: sous-agents rapides, refactorisation itérative du code, tests automatisés et génération de correctifs. (Bon choix.)
- Workflows clients en temps réel et à grand volume: assistants de chat, automatisation interne où le coût par requête compte. (Bon choix.)
- Workflows outillés et contrôle de l’ordinateur: automatisation des tâches GUI/CLI, workflows documentaires et chaînes d’outils où la faible latence aide. (Bon choix.)
- Non recommandé (sans contrôles): rôles autonomes nécessitant une conception de séquences scientifiques de niveau frontière ou des tâches de biosécurité à haute assurance. (Faire preuve de prudence.)