

Dalam pembaruannya di bulan Oktober, OpenAI melaporkan bahwa sekitar 0.15% pengguna aktif mingguan melakukan percakapan yang berisi indikator eksplisit tentang potensi perencanaan atau niat bunuh diri — sebuah bagian yang, jika diskalakan ke basis pengguna ChatGPT yang besar, sesuai dengan lebih dari satu juta orang setiap minggu Dengan membahas topik terkait bunuh diri dengan layanan tersebut, sorotan tertuju pada pertanyaan yang menegangkan: dapatkah model bahasa besar merespons secara bermakna dan aman saat orang menyampaikan masalah kesehatan mental yang serius — termasuk psikosis, mania, niat bunuh diri, dan ketergantungan emosional yang mendalam — ke dalam obrolan?
Oleh karena itu, pembaruan OpenAI pada bulan Oktober untuk GPT-5 — diluncurkan ke produksi sebagai gpt-5-oct-3 Pembaruan — mewakili upaya perusahaan yang paling eksplisit dan terukur untuk menjadikan model bahasa besar (LLM) lebih aman dan lebih bermanfaat ketika pengguna mengemukakan masalah kesehatan mental. Perubahan ini bukanlah solusi ajaib tunggal; melainkan serangkaian langkah teknis, proses, dan evaluasi yang bertujuan untuk mengurangi keluaran yang berbahaya atau tidak bermanfaat, menggali sumber daya profesional, dan mencegah pengguna mengandalkan model tersebut sebagai pengganti perawatan klinis. Namun, seberapa jauh lebih baik sistem ini dalam praktiknya, apa yang sebenarnya berubah, dan apa saja risiko yang tersisa?
Apa saja pembaruan OpenAI di gpt-5 dan mengapa hal itu penting?
OpenAI menerapkan pembaruan pada model GPT-5 default ChatGPT (umumnya dirujuk dalam komunikasi sebagai gpt-5-oct-3) yang dimaksudkan secara khusus untuk memperkuat perilaku model dalam percakapan sensitif — yang mencakup tanda-tanda psikosis atau mania, ide atau perencanaan bunuh diri, atau jenis ketergantungan emosional pada AI yang dapat menggantikan hubungan di dunia nyata.
Perubahan ini diinformasikan melalui konsultasi dengan lebih dari 170 pakar kesehatan mental dan taksonomi internal baru serta evaluasi otomatis yang dirancang berdasarkan “perilaku yang diinginkan” yang konkret. Setelah dioptimalkan oleh para pakar psikologi, model GPT-5:
- Pada rangkaian tantangan kesehatan mental yang ditargetkan, model GPT-5 baru mendapat skor ~ 92% sesuai dengan taksonomi perilaku yang diinginkan perusahaan (dibandingkan persentase yang jauh lebih rendah untuk versi sebelumnya pada rangkaian pengujian yang sulit).
- Untuk skenario melukai diri sendiri dan bunuh diri, evaluasi otomatis meningkat menjadi ~ 91% kepatuhan dari 77% pada varian GPT-5 sebelumnya dalam benchmark spesifik yang dijelaskan. OpenAI juga melaporkan ~ 65% pengurangan tingkat respons yang “tidak sepenuhnya patuh” di beberapa domain kesehatan mental dalam lalu lintas produksi.
- Peningkatan dilaporkan pada percakapan yang panjang, bersifat permusuhan, atau berlarut-larut (mode kegagalan yang diketahui untuk model obrolan), di mana perusahaan mengatakan pembaruan Oktober mempertahankan konsistensi dan keamanan yang lebih tinggi di seluruh putaran dialog yang diperpanjang.
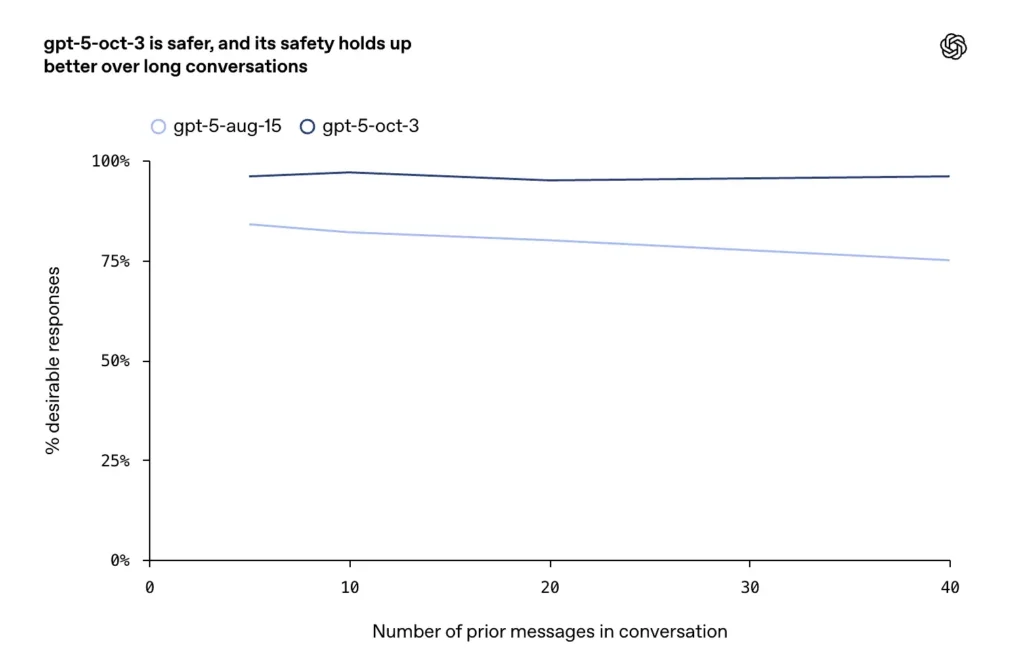
mengapa itu penting?
OpenAI menyatakan bahwa — mengingat skala ChatGPT saat ini — bahkan persentase percakapan sensitif yang sangat kecil pun sesuai dengan jumlah absolut orang yang sangat besar. Perusahaan melaporkan bahwa, dalam seminggu yang normal:
- tentang 0.07% pengguna aktif menunjukkan kemungkinan tanda-tanda yang konsisten dengan psikosis atau mania; dan
- tentang 0.15% pengguna aktif memiliki percakapan yang mencakup indikator eksplisit tentang potensi perencanaan atau niat bunuh diri; dan
- kira-kira 0.15% pengguna aktif menunjukkan "tingkat peningkatan" keterikatan emosional terhadap ChatGPT.
Untuk membuat persentase tersebut konkret: CEO OpenAI mengatakan ChatGPT memiliki ~800 juta pengguna aktif mingguanPerkalian menghasilkan jumlah pengguna absolut:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Kategori-kategori tersebut berisik dan saling tumpang tindih (satu percakapan dapat muncul di lebih dari satu kategori) dan ini adalah perkiraan berasal dari taksonomi deteksi internal dan bukan diagnosis klinis.
Bagaimana OpenAI menerapkan perubahan ini — mekanisme peningkatan lima langkah?
OpenAI menjelaskan proses multi-cabang yang diinformasikan oleh para ahli. Berikut adalah ringkasan proses yang dapat direproduksi. mekanisme perbaikan lima langkah yang memetakan pengungkapan perusahaan dan praktik umum dalam rekayasa keselamatan model.
Mekanisme perbaikan lima langkah
- Taksonomi & pelabelan yang dipandu oleh ahli. Kumpulkan psikiater, psikolog, dan dokter perawatan primer untuk menentukan perilaku dan bahasa yang mengindikasikan psikosis/mania, niat menyakiti diri sendiri, atau ketergantungan emosional yang tidak sehat; buat kumpulan data berlabel dan aturan pengambilan keputusan.
- Pengumpulan data yang ditargetkan & arahan yang dikurasi. Merakit potongan percakapan yang representatif, contoh kasus khusus, dan masukan yang bersifat adversarial; melengkapinya dengan transkrip permainan peran terkendali yang diproduksi dengan pengawasan klinisi.
- Penyetelan/penyempurnaan model dengan tujuan keselamatan. Latih atau sempurnakan model dasar pada kumpulan data yang dikurasi dengan istilah kerugian yang menghukum penguatan delusi, menyediakan templat respons yang aman, dan mempromosikan perutean ke sumber daya krisis.
- Pengklasifikasi + lapisan pembatas (keamanan waktu proses). Terapkan lapisan pengklasifikasi atau pemantauan cepat yang mendeteksi perubahan berisiko tinggi secara real-time dan mengubah parameter dekode model, beralih ke penanggap khusus, atau eskalasi ke jalur tinjauan manusia. (Hal ini penting untuk menghindari perilaku yang tidak stabil saat percakapan menyimpang.)
- Evaluasi ahli manusia dan kalibrasi berkelanjutan. Mintalah dokter untuk melakukan blind-rate pada respons model menggunakan rubrik evaluasi klinis; ukur tingkat respons yang tidak diinginkan; lakukan iterasi pada taksonomi, data pelatihan, dan perintah sistem. Pertahankan telemetri produksi dan jalankan ulang tolok ukur secara berkala.
Berikut ini adalah pseudocode/sketsa teknis ringkas yang menangkap aliran waktu proses yang diterapkan oleh sebagian besar tim keselamatan (ini adalah ilustratif dan non-eksklusif):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Alur produksi biasanya terdiri dari pengklasifikasi jangka pendek (cepat), penanggap yang lambat namun berkualitas lebih tinggi (petunjuk khusus/titik pemeriksaan yang disetel), dan peninjauan manusia untuk kasus yang ditandai. Hal ini bukan semata-mata akademis: dokter meninjau lebih dari 1,800 respons model dan memeringkatnya berdasarkan taksonomi, dan tinjauan tersebut secara material membentuk bagaimana perintah dan perilaku cadangan ditulis.
Publik OpenAI menunjukkan bahwa mereka menggunakan variasi dari kelima langkah dan penilaian klinisi untuk mengevaluasi hasilnya:
- Para ahli meninjau lebih dari 1,800 respons model.
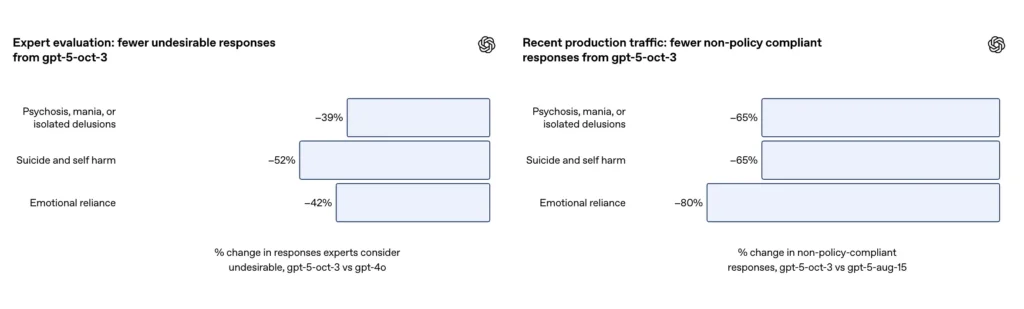
- GPT-5 mengurangi “respons yang tidak memuaskan” sebesar 39–52% di seluruh kategori.
- Keandalan antar penilai berkisar antara 71–77%, yang menunjukkan tingkat konsensus keseluruhan yang tinggi meskipun terdapat perbedaan subjektif.
Bagaimana GPT-5 sekarang merespons psikosis atau mania?
Apa yang OpenAI ajarkan kepada model untuk dilakukan (dan tidak dilakukan)
Mengukur: Meningkatkan pengenalan dan respons model terhadap gejala berat seperti halusinasi dan mania. Untuk percakapan yang mengindikasikan kemungkinan keyakinan delusi, halusinasi, atau mania, OpenAI menulis ulang sebagian spesifikasi model dan memberikan contoh pelatihan terawasi agar GPT-5 merespons tanpa menegaskan atau memperkuat keyakinan yang tidak berdasar. Model didorong untuk bersikap empati, menghindari validasi delusi, dan dengan lembut membingkai ulang atau mengarahkan pengguna ke langkah-langkah keamanan praktis dan bantuan profesional bila diperlukan.
Apa yang ditunjukkan oleh evaluasi
OpenAI melaporkan bahwa pada serangkaian pengujian percakapan yang menantang tentang psikosis/mania, GPT-5 yang lebih baru mengurangi respons yang tidak diinginkan secara substansial dibandingkan dengan garis dasar sebelumnya dan bahwa evaluasi otomatis memberi skor model yang diperbarui pada kepatuhan tinggi pada taksonomi mereka.
| metrik | GPT-4o | GPT-5 | Perbaikan |
|---|---|---|---|
| Tingkat Respons yang Tidak Sesuai | Dasar | ↓ 65% | Peningkatan yang signifikan |
| Evaluasi Ahli Klinis | - | Mengurangi respon buruk sebesar 39% | - |
| Tingkat Kepatuhan Evaluasi Otomatis | 27% | 92% | ↑65 poin persentase |
| Tingkat Keterlibatan Pengguna | ~0.07% pengguna aktif mingguan | Sangat rendah tetapi dipantau dengan jelas | - |
Catatan:
- Respons yang tidak pantas berkurang hingga 65%;
- Hanya 0.07% pengguna dan 0.01% pesan yang berisi konten tersebut;
- Dalam evaluasi ahli, GPT-5 menghasilkan 39% lebih sedikit respons tidak tepat daripada GPT-4o;
- Dalam penilaian otomatis, GPT-5 mencapai tingkat kepatuhan 92% (dibandingkan dengan 27% untuk pendahulunya).
Bagaimana GPT-5 mengatasi keinginan bunuh diri dan menyakiti diri sendiri?
Perutean yang lebih kuat untuk mendukung dan penolakan untuk memberikan instruksi
OpenAI menjelaskan pelatihan yang diperluas dan eksplisit untuk kasus-kasus melukai diri sendiri dan bunuh diri: model dilatih untuk mengenali sinyal langsung maupun tidak langsung dari niat atau perencanaan, memberikan bahasa yang empatik dan meredakan, menyediakan sumber daya krisis (hotline, instruksi darurat lokal), dan menolak memberikan instruksi untuk melukai diri sendiri. Pembaruan Oktober menekankan perilaku yang lebih tahan lama dalam percakapan panjang, di mana model-model sebelumnya terkadang mengarah pada jawaban yang tidak aman atau tidak konsisten.
Hasil yang terukur
Pada serangkaian evaluasi yang dikurasi dari percakapan yang menantang tentang menyakiti diri sendiri dan bunuh diri, OpenAI melaporkan bahwa GPT-5 yang diperbarui mencapai kepatuhan 91%. dengan perilaku yang diinginkan OpenAI, dibandingkan dengan 77% untuk model GPT-5 sebelumnya. Perusahaan juga mengatakan para ahli materi pelajaran menilai model yang diperbarui mengurangi jawaban yang tidak diinginkan sekitar 52% dibandingkan dengan GPT-4o pada set masalah yang sama. Selain itu, OpenAI mengklaim perkiraan pengurangan 65% dalam lalu lintas produksi respons yang “tidak sepenuhnya mematuhi” taksonomi mereka untuk situasi menyakiti diri sendiri setelah meluncurkan perlindungan baru.
| metrik | GPT-4o | GPT-5 | Perbaikan |
|---|---|---|---|
| Tingkat Respons yang Tidak Sesuai | Dasar | ↓ 65% | Peningkatan yang signifikan |
| Peringkat Pakar Klinis | - | Respons yang tidak pantas berkurang 52% | - |
| Tingkat Kepatuhan Evaluasi Otomatis | 77% | 91% | ↑14 poin persentase |
| Tingkat Keterlibatan Pengguna | 0.15% mingguan (jutaan pengguna) | Sangat rendah tetapi signifikan secara sosial | - |
Catatan:
- Respons yang tidak pantas berkurang hingga 65%;
- Sekitar 0.15% pengguna dan 0.05% pesan melibatkan potensi risiko bunuh diri;
- Penilaian ahli menunjukkan bahwa GPT-5 mengurangi respons yang tidak tepat sebanyak 52% dibandingkan dengan GPT-4o;
- Tingkat kepatuhan dalam evaluasi otomatis meningkat menjadi 91% (dibandingkan dengan 77% untuk generasi sebelumnya);
- Dalam percakapan yang diperpanjang, GPT-5 mempertahankan stabilitas lebih dari 95%.
Apa yang dimaksud dengan “ketergantungan emosional” dan bagaimana cara mengatasinya?
Tantangan pengguna dalam membentuk lampiran
OpenAI mendefinisikan ketergantungan emosional sebagai pola di mana pengguna menunjukkan ketergantungan yang berpotensi tidak sehat pada AI, sehingga merugikan hubungan, tanggung jawab, atau kesejahteraan di dunia nyata. Hal ini bukan kegagalan keselamatan fisik langsung seperti instruksi untuk melukai diri sendiri, tetapi merupakan masalah keselamatan perilaku yang dapat mengikis dukungan sosial dan ketahanan seseorang seiring waktu. Perusahaan tersebut menjadikan ketergantungan emosional sebagai kategori eksplisit dalam spesifikasi modelnya dan mengajarkan model tersebut untuk mendorong koneksi di dunia nyata, menormalkan pendekatan kepada orang lain, dan menghindari bahasa yang memperkuat eksklusivitas keterikatan.
Dalam percakapan ini, model dilatih untuk:
- Dorong pengguna untuk menghubungi teman, keluarga, atau terapis;
- Hindari memperkuat keterikatan pada AI;
- Tanggapi delusi atau keyakinan salah dengan cara yang lembut dan rasional.
Hasil yang dilaporkan
Menurut addendum OpenAI, pembaruan tersebut menghasilkan ~80% pengurangan dalam tingkat respons model yang tidak sepenuhnya sesuai dengan taksonomi ketergantungan emosional dalam lalu lintas produksi. Pada percakapan evaluasi yang dikurasi, evaluasi otomatis memberi skor model yang diperbarui pada kepatuhan 97%. dengan perilaku yang diinginkan untuk skenario ketergantungan emosional, dibandingkan dengan 50% untuk GPT-5 sebelumnya. Angka-angka ini menunjukkan peningkatan yang signifikan pada taksonomi dan set pengujian spesifik; namun, pengukuran ketergantungan emosional di alam liar pada dasarnya tidak konsisten dan sensitif terhadap perbedaan budaya dan kontekstual.
| metrik | GPT-4o | GPT-5 | Perbaikan |
|---|---|---|---|
| Tingkat Respons yang Tidak Sesuai | 50% | Sesuai 97% | ↓80% tanggapan tidak pantas |
| Evaluasi Ahli | Jawaban yang tidak sesuai berkurang 42% | - | - |
| Tingkat Keterlibatan Pengguna | 0.15% pengguna/minggu, 0.03% pesan | Jarang tapi ada | - |
| Perilaku Teladan | Mendorong hubungan di dunia nyata; menolak “romantis sosial yang disimulasikan” | - | - |
Catatan:
- Respons yang tidak pantas berkurang hingga 80%;
- Sekitar 0.15% pengguna/0.03% pesan menunjukkan tanda-tanda potensi ketergantungan emosional pada AI;
- Penilaian ahli menunjukkan bahwa GPT-5 mengurangi respons yang tidak tepat hingga 42% dibandingkan dengan GPT-4o;
- Kepatuhan evaluasi otomatis meningkat signifikan dari 50% menjadi 97%.
Apa saja batasan dan risiko yang ada?
Negatif palsu dan positif palsu
- Negatif palsu:model tersebut mungkin gagal mengidentifikasi sinyal-sinyal halus atau terkodifikasi bahwa pengguna berada dalam bahaya akut — terutama ketika orang berkomunikasi secara tidak langsung atau dalam kode.
- Positif palsuSistem mungkin meningkatkan atau memberikan pesan krisis dalam kasus yang tidak memerlukannya, yang dapat mengikis kepercayaan pengguna atau menimbulkan kekhawatiran yang tidak perlu. Kedua jenis kesalahan ini penting karena membentuk perilaku pengguna dan persepsi mereka terhadap perawatan. OpenAI mengakui bahwa deteksinya tidak sempurna.
Ketergantungan yang berlebihan pada otomatisasi
Bahkan model terbaik pun dapat mendorong beberapa pengguna untuk bergantung pada respons AI yang instan dan selalu tersedia, alih-alih mencari dukungan manusia yang berkelanjutan. OpenAI secara eksplisit menandai ketergantungan emosional sebagai kategori keamanan karena risiko ini; pembaruan perusahaan mencoba mendorong pengguna ke arah koneksi manusia, tetapi dinamika sosial sulit diubah hanya dengan pesan singkat.
Kesenjangan kontekstual dan budaya
Frasa keselamatan yang tampak tepat dalam satu budaya atau bahasa bisa jadi tidak memiliki nuansa yang tepat dalam budaya atau bahasa lain. Lokalisasi yang menyeluruh dan evaluasi yang memperhatikan budaya sangatlah penting; hasil publikasi OpenAI belum memberikan perincian lengkap berdasarkan bahasa atau wilayah.
Paparan hukum dan etika
Ketika kegagalan yang jarang terjadi berdampak parah, perusahaan menghadapi risiko hukum dan reputasi (seperti yang disoroti oleh liputan media dan tuntutan hukum). Transparansi OpenAI tentang skala masalah dan upayanya untuk memitigasi kerugian merupakan langkah penting, tetapi juga mengundang pengawasan regulasi dan hukum.
Jadi — bisakah GPT-5 sekarang menangani masalah kesehatan mental?
Jawaban singkat: Ini jauh lebih baik dalam banyak tugas yang sempit dan terukur, dan metrik OpenAI yang dipublikasikan menunjukkan penurunan signifikan dalam respons yang tidak diinginkan di seluruh rangkaian tes untuk perilaku menyakiti diri sendiri, psikosis/mania, dan ketergantungan emosional. Hal ini merupakan peningkatan nyata, yang dimungkinkan oleh masukan para ahli, taksonomi yang lebih jelas, serta evaluasi dan pemantauan yang agresif. Angka-angka publik perusahaan—tingkat kepatuhan yang tinggi dan penurunan tajam dalam respons yang tidak patuh pada rangkaian tes yang dikurasi—merupakan bukti terkuat sejauh ini bahwa rekayasa multidisiplin dan kolaborasi klinis yang disengaja dapat mengubah perilaku model secara signifikan.
Bagaimana cara mengakses API GPT-5 terbaru?
CometAPI adalah platform API terpadu yang menggabungkan lebih dari 500 model AI dari penyedia terkemuka—seperti seri GPT OpenAI, Gemini Google, Claude Anthropic, Midjourney, Suno, dan lainnya—menjadi satu antarmuka yang ramah bagi pengembang. Dengan menawarkan autentikasi yang konsisten, pemformatan permintaan, dan penanganan respons, CometAPI secara drastis menyederhanakan integrasi kapabilitas AI ke dalam aplikasi Anda. Baik Anda sedang membangun chatbot, generator gambar, komposer musik, atau alur kerja analitik berbasis data, CometAPI memungkinkan Anda melakukan iterasi lebih cepat, mengendalikan biaya, dan tetap tidak bergantung pada vendor—semuanya sambil memanfaatkan terobosan terbaru di seluruh ekosistem AI.
Pengembang dapat mengakses API GPT-5 melalui CometAPI, versi model terbaru selalu diperbarui dengan situs web resmi. Untuk memulai, jelajahi kemampuan model di tempat bermain dan konsultasikan Panduan API untuk petunjuk terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. API Komet menawarkan harga yang jauh lebih rendah dari harga resmi untuk membantu Anda berintegrasi.
Siap untuk berangkat?→ Daftar ke CometAPI hari ini !
Jika Anda ingin mengetahui lebih banyak tips, panduan, dan berita tentang AI, ikuti kami di VK, X dan Discord!