API audio GPT-4o: Un unificato /chat/completions estensione endpoint che accetta input audio (e testo) codificati in Opus e restituisce sintesi vocale o trascrizioni con parametri configurabili (modello=gpt-4o-audio-preview-<date>, speed, temperature) per interazioni vocali in batch e in streaming.
Informazioni di base su GPT-4o Audio
Anteprima audio GPT-4o (gpt-4o-audio-preview-2025-06-03) è l'ultima novità di OpenAI modello linguistico di grandi dimensioni incentrato sulla parola reso disponibile tramite lo standard API di completamento chat piuttosto che il canale Realtime a bassissima latenza. Costruito sulla stessa base "omni" di GPT-4o, questa variante è specializzata in input e output vocale ad alta fedeltà Per conversazioni a turni, creazione di contenuti, strumenti di accessibilità e flussi di lavoro agentici che non richiedono tempi di millisecondi. Eredita tutti i punti di forza del ragionamento testuale dei modelli di classe GPT-4, aggiungendo discorso-discorso end-to-end (S2S) condotte, deterministiche chiamata di funzione, E la nuova speed parametro per il controllo della velocità della voce.
Set di funzionalità principali di GPT-4o Audio
· XNUMX€ Elaborazione unificata della voce – L’audio viene trasformato direttamente in token semanticamente ricchi, ragionati e risintetizzati senza servizi STT/TTS esterni, producendo timbro vocale coerente, prosodia e mantenimento del contesto.
· XNUMX€ Miglioramento del follow-up delle istruzioni – La messa a punto di giugno 2025 fornisce +19 pp pass-at-1 sulle attività a comando vocale rispetto al valore di riferimento GPT-2024o di maggio 4, riducendo le allucinazioni in ambiti quali l'assistenza clienti e la stesura di contenuti.
· XNUMX€ Chiamata stabile dello strumento – I risultati del modello JSON strutturato conforme allo schema di chiamata delle funzioni OpenAI, consentendo l'attivazione delle API backend (ricerca, prenotazione, pagamenti) con >95% di accuratezza degli argomenti.
· XNUMX€ speed Parametro (0.25–4×) – Gli sviluppatori possono modulare la riproduzione vocale per un apprendimento lento, una narrazione normale o una rapida modalità di “scorrimento udibile”, senza risintetizzando esternamente il testo.
· XNUMX€ Turni di svolta consapevoli delle interruzioni – Sebbene non sia guidata dalla latenza come la variante in tempo reale, l'anteprima supporta streaming parziale: i token vengono emessi non appena vengono elaborati, consentendo agli utenti di interrompere anticipatamente se necessario.
Architettura tecnica di GPT-4o
• Trasformatore a pila singola – Come tutti i derivati GPT-4o, l’anteprima audio utilizza un codificatore-decodificatore unificato dove i segnali testuali e acustici attraversano blocchi di attenzione identici, favorendo il radicamento multimodale.
• Tokenizzazione audio gerarchica – PCM grezzo a 16 kHz → patch log-mel → codici acustici grossolani → token semanticiQuesta compressione multistadio raggiunge Riduzione della larghezza di banda del 40-50% preservando le sfumature e consentendo clip di più minuti per finestra di contesto.
• Pesi quantizzati NF4 – L’inferenza è servita a Normale a virgola mobile a 4 bit precisione, riducendo la memoria GPU della metà rispetto a fp16 e mantenendo Oltre 70 RTF in streaming (fattore in tempo reale) su nodi A100-80 GB.
• Streaming dell'attenzione e memorizzazione nella cache KV – Gli incorporamenti rotanti a finestra scorrevole mantengono il contesto per circa 30 secondi di discorso mantenendo O(L) utilizzo di memoria, ideale per editor di podcast o strumenti di lettura assistita.
Versioning e denominazione — Anteprima della traccia con build con data timbrata
| Identifier | canale | Missione | Data di uscita | Stabilità |
|---|---|---|---|---|
| gpt-4o-anteprima-audio-2025-06-03 | API di completamento chat | Interazioni audio a turni, attività agentiche | 03 giugno 2025 | Anteprima (feedback incoraggiato) |
Elementi chiave del nome:
- gpt-4o – Famiglia multimodale Omni.
- Audio – Ottimizzato per casi d’uso vocali.
- anteprima – Il contratto API potrebbe evolversi; non è ancora disponibile.
- 2025-06-03 – Snapshot di formazione e distribuzione per la riproducibilità.
Come chiamare l'API audio GPT-4o da CometAPI
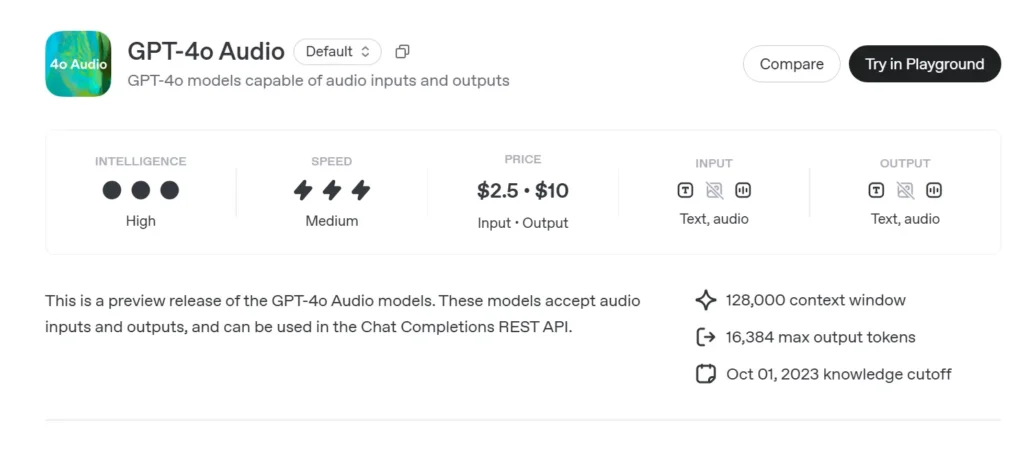
GPT-4o Audio API Prezzi API in CometAPI:
- Input token: $ 2 / M token
- Token di output: $ 8 / M token
Passi richiesti
- Accedere cometapi.comSe non sei ancora un nostro utente, registrati prima
- Ottieni la chiave API delle credenziali di accesso dell'interfaccia. Fai clic su "Aggiungi token" nel token API nell'area personale, ottieni la chiave token: sk-xxxxx e invia.
- Ottieni l'URL di questo sito: https://api.cometapi.com/
Metodi di utilizzo
- Selezionare l'opzione "
gpt-4o-audio-preview-2025-06-03"endpoint" per inviare la richiesta e impostarne il corpo. Il metodo e il corpo della richiesta sono reperibili nella documentazione API del nostro sito web. Il nostro sito web fornisce anche il test Apifox per vostra comodità. - Sostituire con la tua chiave CometAPI effettiva dal tuo account.
- Inserisci la tua domanda o richiesta nel campo contenuto: il modello risponderà a questa domanda.
- Elaborare la risposta API per ottenere la risposta generata.
Per informazioni sull'accesso al modello in Comet API, vedere Documento API.
Per informazioni sul prezzo del modello in Comet API, vedere https://api.cometapi.com/pricing.
Flusso di lavoro API — Completamento delle chat con parti audio e hook di funzione
- Formato di input -
audio/*MIME obase64Pezzi WAV incorporati inmessages[].content. - Opzioni di output -
· XNUMX€mode: "text"→ testo puro per didascalie.
· XNUMX€mode: "audio"→ restituisce un Streaming Payload Opus o µ-law con timestamp. - Invocazione della funzione - Aggiungi
functions:schema; il modello emetterole: "function"con argomenti JSON; lo sviluppatore esegue la chiamata allo strumento e, facoltativamente, inoltra il risultato. - Rate Control - Impostato
voice.speed=1.25per accelerare la riproduzione; intervalli sicuri 0.25–4.0. - Limiti di token/audio – 128 k di contesto (~4 min di discorso) all'avvio; 4096 token audio / 8192 token di testo a seconda di quale evento si verifica per primo.
Codice di esempio e integrazione API
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Highlight:
- modello:
"gpt-4o-audio-preview-2025-06-03" - Audio digitare Utente messaggio da inviare flusso binario
- velocità: Controlli velocità della voce tra lento (0.5) e veloce (2.0)
- temperatura: Saldi la creatività vs. coerenza
Indicatori tecnici — Latenza, qualità, accuratezza
| Metrico | Anteprima audio | GPT-4o (solo testo) | Delta |
|---|---|---|---|
| Latenza del primo token (1-shot) | 1.2 s avg | 0.35 s | +0.85 secondi |
| MOS (Naturalità del discorso, 5 pt) | 4.43 | - | - |
| Conformità alle istruzioni (voce) | 92% | 73% | +19 pagg |
| Precisione degli argomenti della chiamata di funzione | 95.8% | 87% | +8.8 pagg |
| Tasso di errore di parola (STT implicito) | 5.2% | n/a | - |
| Memoria GPU / Streaming (A100-80 GB) | 7.1 GB | 14 GB (fp16) | −49% |
Benchmark eseguiti tramite streaming di completamenti chat, dimensione batch = 1.
Vedere anche API in tempo reale GPT-4o