Claude Haiku 4.5 è un modello linguistico di classe più piccola, ottimizzato per scopi specifici, di Anthropic, rilasciato a metà ottobre 2025. È posizionato come un’opzione veloce, a basso costo nella gamma Claude che mantiene solide capacità in attività come coding, orchestrazione di agenti e flussi di lavoro interattivi di “uso del computer”, consentendo al contempo un throughput molto più elevato e un costo unitario inferiore per le implementazioni enterprise.
Caratteristiche principali
- Velocità ed efficienza dei costi: Haiku 4.5 è descritto come oltre due volte più veloce di Sonnet 4 e circa un terzo del costo di Sonnet 4 (e molto più economico di Opus), rendendolo attraente per utilizzi su larga scala.
- Pensiero esteso: Primo modello Haiku a supportare il pensiero esteso (pensiero riassunto/intervallato, budget di pensiero configurabili) per un ragionamento multi‑passo più profondo, bilanciando la latenza.
- Strumenti e uso del computer: Pieno supporto per gli strumenti Claude (bash, esecuzione di codice, editor di testo, ricerca sul web e automazione dell’uso del computer). Progettato per flussi di lavoro basati su agenti e architetture con sotto‑agenti.
- Ampia finestra di contesto: 200k token (con opzioni di contesto da 1M disponibili sui modelli più grandi in beta per altre classi di modelli).
Dettagli tecnici
- Dati di addestramento e cutoff: Haiku 4.5 è stato addestrato su un mix proprietario di dati pubblici e con licenza con un cutoff di addestramento intorno a febbraio 2025.
- È supportato il pensiero esteso (una modalità ibrida di ragionamento) così il modello può scambiare latenza per un ragionamento più profondo quando richiesto.
- La finestra di contesto al rilascio è di 200,000 tokens, e il modello è esplicitamente consapevole del contesto (tiene traccia di quanto della finestra è stato utilizzato).
- Prestazioni / throughput: Rapporti iniziali della community e test di Anthropic citano OTPS molto elevati (output tokens/sec) e velocità aneddotiche intorno a ~200+ tokens/sec in alcuni test interni/iniziali — molto più veloce di molti modelli di fascia media comparabili.
Prestazioni nei benchmark
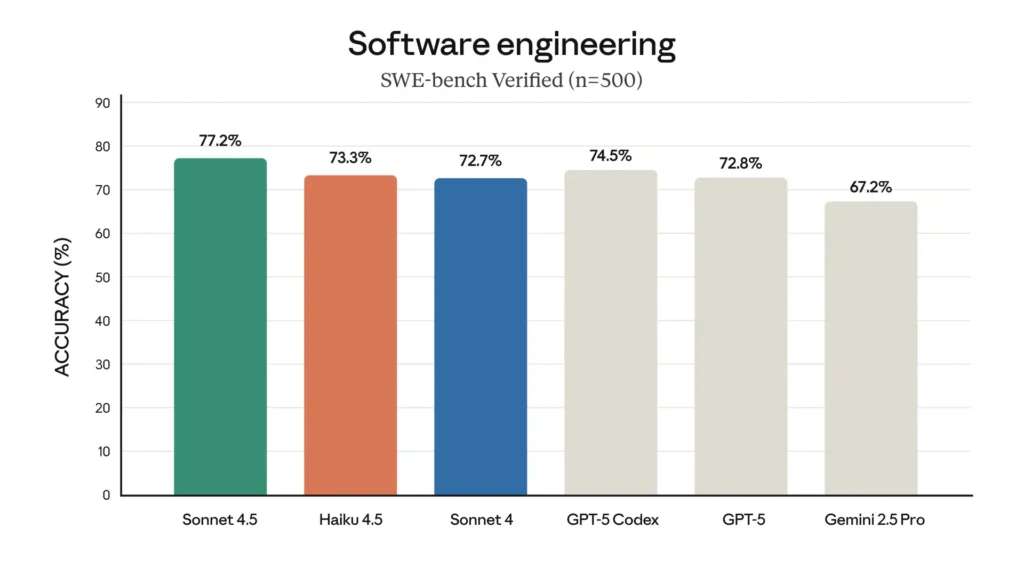
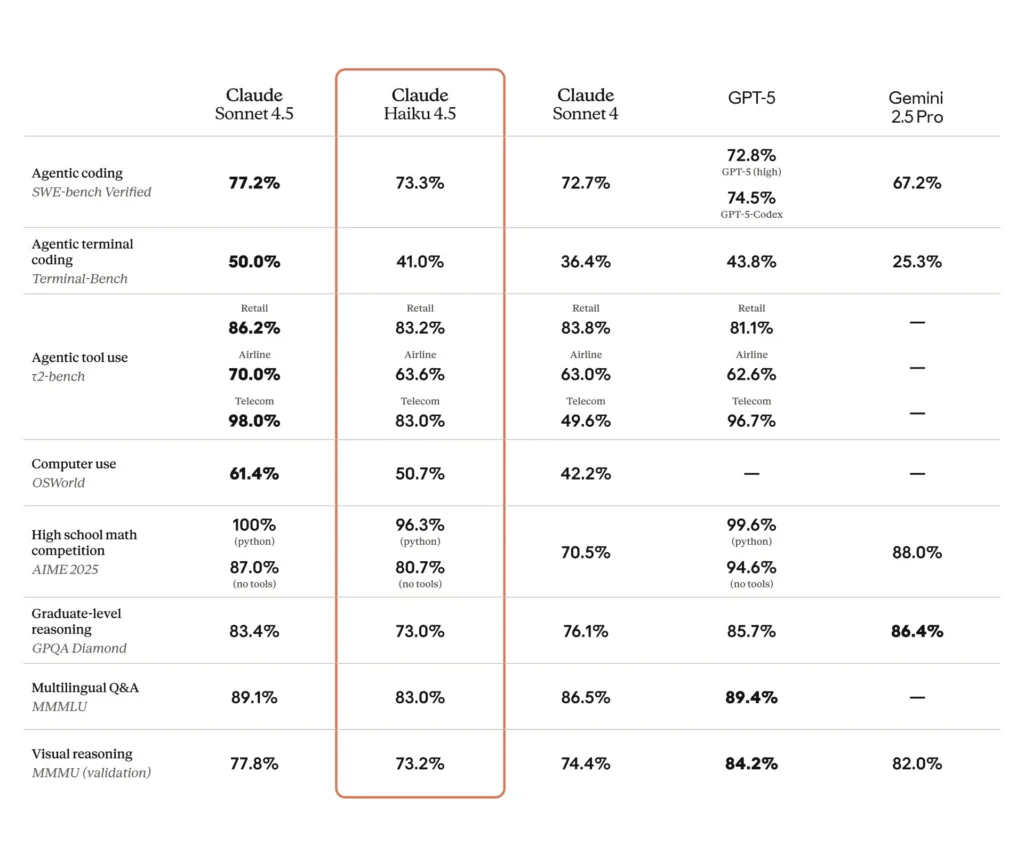
SWE-Bench (coding): Haiku 4.5 ha ottenuto ~73.3% su SWE-Bench Verified — un risultato che Anthropic evidenzia come tale da collocare Haiku 4.5 tra i migliori modelli di coding al mondo nella sua classe.
Terminale / riga di comando / test degli strumenti: Anthropic ha riportato ~41% su Terminal-Bench (incentrato sulla riga di comando) e risultati comparabili a Sonnet 4 e a diversi modelli frontier di fascia media concorrenti in molti benchmark di uso degli strumenti.
Follow‑the‑instruction e testo per slide: esempi interni di Anthropic indicano che Haiku 4.5 ha superato i modelli precedenti in alcuni compiti di follow‑the‑instruction (ad es., generazione di testo per slide: 65% vs 44% rispetto a un precedente modello premium nel loro benchmark).
Automazione nel mondo reale / compiti per agent: valutazioni di terze parti e early adopter riportano tassi di successo competitivi in attività automatizzate di UI/agent (ad esempio, benchmark in stile OSWorld o per agent che riportano ≈50% di successo su automazioni complesse in alcuni test), mostrando utilità per flussi di lavoro su scala pur con modalità di errore non trascurabili.
Limitazioni e note sulla sicurezza
- Non è un modello di frontiera: Anthropic classifica esplicitamente Haiku 4.5 come non orientato ad avanzare la frontiera; è ottimizzato per l’efficienza piuttosto che per spingere lo stato dell’arte. (Anthropic)
- Comportamento occasionale su temi sensibili: in alcuni prompt scientifici/di biosicurezza Haiku 4.5 talvolta restituisce informazioni di alto livello con cautele invece di rifiuti netti; Anthropic segnala questo come un’area di miglioramento continuo.
- Il pensiero esteso può cambiare il comportamento (a volte aumenta l’asimmetria nelle risposte).
Casi d’uso consigliati
- Coding con agenti e orchestrazione multi‑agente: sub‑agenti veloci, refactoring iterativo del codice, autotest e generazione di patch. (Adatto.)
- Flussi di lavoro clienti in tempo reale e ad alto volume: assistenti di chat, automazione interna dove conta il costo per richiesta. (Adatto.)
- Flussi di lavoro abilitati da strumenti e controllo del computer: automatizzazione di attività GUI/CLI, flussi documentali e toolchain dove la bassa latenza aiuta. (Adatto.)
- Non consigliato (senza controlli): ruoli stand‑alone che richiedono progettazione di sequenze scientifiche a livello di frontiera o compiti di biosicurezza ad alta affidabilità. (Usare cautela.)