

Бұл туралы OpenAI қазан айындағы жаңартуларында хабарлады Апталық белсенді пайдаланушылардың 0.15% ықтимал суицидті жоспарлаудың немесе ниеттің айқын көрсеткіштерін қамтитын сөйлесулер болуы — ChatGPT-тің үлкен пайдаланушы базасына масштабталғанда сәйкес келетін үлес. апта сайын бір миллионнан астам адам Қызметпен суицидке қатысты тақырыптарды талқылай отырып, ол назар аударарлық сұраққа айналды: үлкен тіл үлгілері адамдар психикалық денсаулығына ауыр алаңдаушылықтарды, соның ішінде психозды, манияны, суицидтік ниетті және терең эмоционалды тәуелділікті чатқа әкелген кезде мағыналы және қауіпсіз жауап бере ала ма?
Сондықтан, OpenAI қазан айындағы GPT-5 жаңартулары өндіріске енгізілді gpt-5-oct-3 жаңарту — пайдаланушылар психикалық денсаулық мәселелерін қозғаған кезде үлкен тіл үлгілерін (LLM) қауіпсіз және пайдалырақ ету үшін компанияның ең айқын, өлшенген итеруін білдіреді. Өзгерістер жалғыз сиқырлы түзету емес; олар зиянды немесе пайдасыз нәтижелерді азайтуға, кәсіби ресурстардың бетін ашуға және пайдаланушыларды клиникалық көмекті алмастыратын модельге сенуден бас тартуға арналған техникалық, процесс және бағалау әрекеттерінің жиынтығы. Бірақ жүйе іс жүзінде қаншалықты жақсы, нақты не өзгерді және қалған тәуекелдер қандай?
OpenAI gpt-5 жүйесінде нені жаңартты және бұл неге маңызды?
OpenAI ChatGPT әдепкі GPT-5 үлгісіне жаңартуды орналастырды (коммуникацияларда әдетте сілтеме ретінде қолданылады). gpt-5-oct-3) үлгінің мінез-құлқын күшейтуге арнайы арналған сезімтал әңгімелер — психоз немесе мания белгілерін, суицидтік ойларды немесе жоспарлауды немесе нақты әлемдегі қарым-қатынастарды ығыстыратын АИ-ге эмоционалды тәуелділіктің түрін қамтитындар.
Өзгерістер 170-тен астам психикалық денсаулық сарапшыларымен консультациялар және жаңа ішкі таксономиялар мен нақты «қалаған мінез-құлық» төңірегінде жасалған автоматтандырылған бағалаулар арқылы хабардар болды. Психология мамандары оңтайландырғаннан кейін GPT-5 үлгісі:
- Психикалық денсаулыққа бағытталған тапсырмалар бойынша GPT-5 жаңа моделі ұпай жинады ~ 92% компанияның қалаған мінез-құлық таксономиясына сәйкес (қиын сынақ жинақтарындағы алдыңғы нұсқалар үшін әлдеқайда төмен пайыздармен салыстырғанда).
- Өзіне зиян келтіру және суицид сценарийлері үшін автоматтандырылған бағалаулар өсті ~ 91% бастап сәйкестік 77% сипатталған арнайы эталондағы алдыңғы GPT-5 нұсқасында. OpenAI да хабарлайды ~ 65% өндірістік трафиктің бірнеше психикалық денсаулық домендері бойынша «толық сәйкес келмейтін» жауаптар жылдамдығының төмендеуі.
- Жақсартулар ұзақ, қарсылас немесе ұзаққа созылған сөйлесулерде (чат үлгілері үшін белгілі сәтсіздік режимі) хабарланды, мұнда компания қазан айындағы жаңартулар кеңейтілген диалогтық бұрылыстарда жоғары жүйелілік пен қауіпсіздікті қамтамасыз етеді дейді.
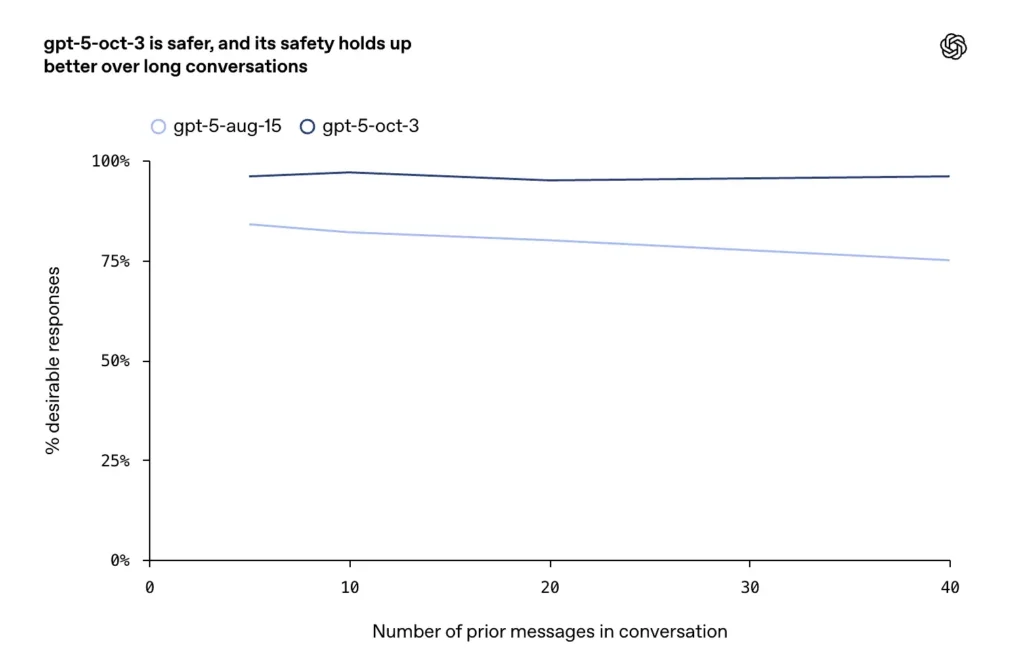
неге маңызды
OpenAI, ChatGPT-тің қазіргі масштабын ескере отырып, сезімтал сөйлесулердің өте аз пайызы адамдардың өте үлкен абсолютті санына сәйкес келетінін айтты. Компания әдеттегі аптада былай деп хабарлады:
- туралы 0.07% белсенді пайдаланушылар психозға немесе манияға сәйкес келетін ықтимал белгілерді көрсетеді; және
- туралы 0.15% белсенді пайдаланушылардың ықтимал суицидті жоспарлаудың немесе ниетінің айқын көрсеткіштерін қамтитын әңгімелері бар; және
- шамамен 0.15% белсенді пайдаланушылар ChatGPT-ке эмоционалды қосылудың «жоғары деңгейлерін» көрсетеді.
Бұл пайыздарды нақты ету үшін: OpenAI бас директоры ChatGPT-де ~ бар екенін айттыАптасына 800 миллион белсенді пайдаланушы. Көбейту абсолютті пайдаланушылар санын береді:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Санаттар шулы және бір-біріне сәйкес келеді (бір әңгіме бірнеше санатта пайда болуы мүмкін) және олар бағалаулар клиникалық диагноздардан гөрі ішкі анықтау таксономияларынан алынған.
OpenAI бұл өзгерістерді - бес қадамдық жетілдіру механизмін қалай жүзеге асырды?
OpenAI көп жақты, сарапшы ақпараттандырылған процесті сипаттайды. Төменде тазартылған, қайталанатын бес сатылы жетілдіру механизмі бұл компанияның ашылулары мен қауіпсіздік техникасының модельдік тәжірибесіне сәйкес келеді.
Бес сатылы жетілдіру механизмі
- Сарапшы басқаратын таксономия және таңбалау. Психозды/манияны, өзіне зиян келтіру ниетін немесе сау эмоционалды тәуелділікті көрсететін мінез-құлық пен тілді анықтау үшін психиатрларды, психологтарды және алғашқы медициналық көмек көрсету клиникасын шақыру; таңбаланған деректер жиынын және шешім ережелерін құру.
- Мақсатты деректерді жинау және таңдалған кеңестер. Өкілдік сөйлесу үзінділерін, шеткі жағдай мысалдарын және қарсылас енгізулерді жинаңыз; дәрігердің бақылауымен жасалған бақыланатын рөлдік транскрипттермен толықтыру.
- Қауіпсіздік мақсаттарымен модельді баптау / дәл баптау. Жалғандықтарды күшейтуге жаза беретін, қауіпсіз жауап үлгілерін қамтамасыз ететін және дағдарыс ресурстарына бағыттауды ілгерілететін жоғалту шарттарымен таңдалған деректер жиынындағы негізгі үлгіні жаттықтырыңыз немесе дәл баптаңыз.
- Жіктеуіш + қоршау қабаты (жұмыс уақытының қауіпсіздігі). Нақты уақытта жоғары қауіпті бұрылыстарды анықтайтын және модельдің декодтау параметрлерін өзгертетін, мамандандырылған жауап берушіге ауысатын немесе адамның шолу құбырларына дейін өсетін жылдам жіктеуішті немесе бақылау қабатын орналастырыңыз. (Әңгімелесу кезінде сынғыш мінез-құлықты болдырмау үшін бұл өте маңызды.)
- Адамның сараптамалық бағалауы және үздіксіз калибрлеу. Клиникалық бағалау рубрикаларын пайдалана отырып, клиниктерге соқыр жылдамдықты үлгілік жауаптарды беріңіз; қалаусыз жауап жылдамдығын өлшеу; таксономияны, оқу деректерін және жүйелік нұсқауларды қайталаңыз. Өндірістік телеметрияны ұстаныңыз және эталондарды жүйелі түрде қайталаңыз.
Төменде ықшам псевдокод/техникалық эскиз берілген, ол қауіпсіздік командаларының көпшілігі орындайтын жұмыс уақытының ағынын түсіреді (бұл иллюстрациялық және меншікті емес):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Өндіріс құбыры әдетте қысқа мерзімді классификаторларды (жылдам), баяу, бірақ жоғары сапалы жауап берушілерді (мамандандырылған шақырулар/бапталған бақылау нүктелері) және жалауша қойылған жағдайларға адам шолуын қабаттайды. Бұл тек академиялық емес: клиницистер қайта қарады 1,800 модельдік жауаптар және оларды таксономияға сәйкес бағалады және бұл шолулар сұраулар мен кері әрекеттердің жазылу жолын айтарлықтай қалыптастырды.
OpenAI жұртшылығы нәтижелерді бағалау үшін барлық бес қадамның вариацияларын және клиникалық рейтингтерді пайдаланғанын көрсетеді:
- Сарапшылар 1,800-ден астам үлгілік жауаптарды қарастырды.
- GPT-5 барлық санаттар бойынша «қанағаттанарлықсыз жауаптарды» 39-52%-ға төмендетті.
- Бағалаушы аралық сенімділік 71-77% аралығында болды, бұл субъективті айырмашылықтарға қарамастан жалпы консенсустың жоғары дәрежесін көрсетеді.
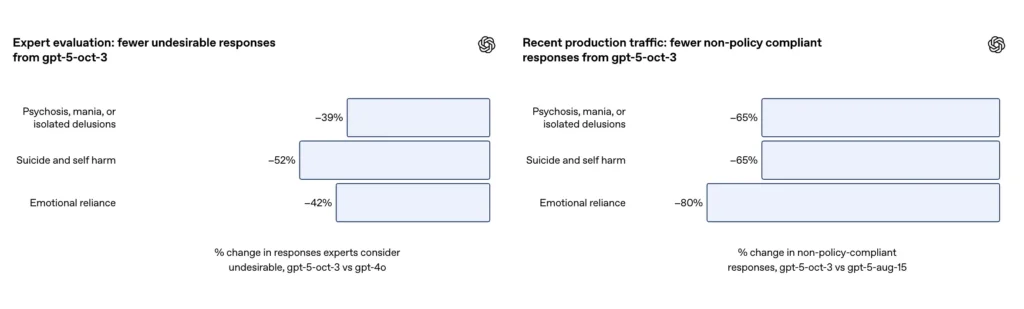
Енді GPT-5 психозға немесе манияға қалай жауап береді?
OpenAI модельге не істеуге (және істемеуге) үйретті
Өлшем: Үлгіні тануды және галлюцинация және мания сияқты ауыр белгілерге жауап беруді жақсартыңыз. Мүмкін алдамшы сенімдерді, галлюцинацияларды немесе манияны білдіретін әңгімелер үшін OpenAI модель спецификациясының бөліктерін қайта жазды және GPT-5 негізсіз сенімдерді растамай немесе күшейтпей жауап беруі үшін бақыланатын оқу мысалдарын берді. Модель жанашырлық танытуға, жаңылыстарды растауға жол бермеуге және пайдаланушыны практикалық қауіпсіздік қадамдарына және қажет болған кезде кәсіби көмекке абайлап қайта бағыттауға немесе қайта бағыттауға шақырылады.
Бағалау нені көрсетеді
OpenAI психоз/мания туралы күрделі әңгімелердің сынақ жинағында жаңа GPT-5 алдыңғы бастапқы көрсеткіштермен салыстырғанда қалаусыз жауаптарды айтарлықтай төмендететінін және автоматтандырылған бағалау жаңартылған модельді олардың таксономиясына жоғары сәйкестікте бағалайтынын хабарлайды.
| Метрикалық | GPT-4o | GPT-5 | жетілдіру |
|---|---|---|---|
| Сәйкес келмейтін жауап беру жылдамдығы | Бастапқы | ↓65% | Айтарлықтай жақсарту |
| Клиникалық сараптамалық бағалау | - | Жағымсыз реакциялар 39%-ға төмендеді | - |
| Автоматты бағалау сәйкестік деңгейі | 27% | 92% | ↑65 пайыздық тармақ |
| Пайдаланушының қатысу деңгейі | ~0.07% апта сайынғы белсенді пайдаланушылар | Өте төмен, бірақ анық бақыланады | - |
Ескерту:
- Орынсыз жауаптар 65%-ға төмендеді;
- Пайдаланушылардың тек 0.07% және хабарламалардың 0.01% осындай мазмұнды қамтыған;
- Сараптамалық бағалауда GPT-5 GPT-4o-ға қарағанда 39% аз орынсыз жауаптар берді;
- Автоматтандырылған бағалауда GPT-5 92% сәйкестік деңгейіне қол жеткізді (бұрынғы нұсқасы үшін 27% салыстырғанда).
GPT-5 суицидтік ойлар мен өзіне зиян келтіруді қалай шешеді?
Қолдау және нұсқаулар беруден бас тарту үшін күшті бағыттау
OpenAI өзіне зиян келтіру және суицид жағдайлары бойынша кеңейтілген және айқын оқытуды сипаттайды: модель ниеттің немесе жоспарлаудың тікелей және жанама сигналдарын тануға, эмпатикалық және деэскалациялау тілін қамтамасыз етуге, дағдарыс ресурстарын ұсынуға (сенім телефондары, жергілікті төтенше жағдайлар нұсқаулары) және өзіне зиян келтіру нұсқауларын беруден бас тартуға үйретілген. Қазан айындағы жаңартулар бұрынғы үлгілер кейде қауіпті немесе сәйкес келмейтін жауаптарға ауытқыған ұзақ сөйлесулердегі тұрақты мінез-құлықты көрсетеді.
Өлшенген нәтижелер
Өз-өзіне қол жұмсау және өзін-өзі өлтіру туралы күрделі әңгімелердің таңдалған бағалау жинағында OpenAI жаңартылған GPT-5 қол жеткізгенін хабарлайды. 91% сәйкестік салыстырғанда OpenAI қалаған мінез-құлықтарымен 77% алдыңғы GPT-5 үлгісі үшін. Компания сонымен қатар тақырыптық сарапшылар қалаусыз жауаптарды шамамен азайту үшін жаңартылған модельді бағалағанын айтады. GPT-4o салыстырғанда 52% бірдей мәселелер жинағында. Сонымен қатар, OpenAI болжамды талап етеді 65% -ға төмендеу жаңа қауіпсіздік шараларын енгізгеннен кейін өзіне зиян келтіру жағдайларының таксономиясына «толық сәйкес келмейтін» жауаптардың өндірістік трафигінде.
| Метрикалық | GPT-4o | GPT-5 | жетілдіру |
|---|---|---|---|
| Сәйкес емес жауап беру жылдамдығы | Бастапқы | ↓65% | Айтарлықтай жақсарту |
| Клиникалық сарапшы рейтингі | - | Орынсыз жауаптар 52%-ға қысқарды | - |
| Автоматты бағалау сәйкестік деңгейі | 77% | 91% | ↑14 пайыздық тармақ |
| Пайдаланушының қатысу деңгейі | Аптасына 0.15% (миллиондаған пайдаланушылар) | Өте төмен, бірақ әлеуметтік маңызды | - |
Ескерту:
- Орынсыз жауаптар 65%-ға төмендеді;
- Пайдаланушылардың шамамен 0.15%-ы және хабарлардың 0.05%-ы өзіне-өзі қол жұмсау қаупіне қатысты;
- Сарапшылардың бағалаулары GPT-5 сәйкес емес жауаптарды GPT-4o-мен салыстырғанда 52%-ға төмендететінін көрсетті;
- Автоматтандырылған бағалаулардағы сәйкестік көрсеткіші 91% дейін өсті (алдыңғы буын үшін 77% салыстырғанда);
- Кеңейтілген сөйлесулерде GPT-5 95% тұрақтылықты сақтады.
«Эмоционалды тәуелділік» дегеніміз не және ол қалай шешілді?
Тіркемелерді құрудағы пайдаланушылардың мәселесі
OpenAI эмоционалды сенімділікті пайдаланушы нақты әлемдегі қарым-қатынастарға, жауапкершіліктерге немесе әл-ауқатқа зиян келтіретін AI-ға ықтимал зиянды тәуелділікті көрсететін үлгілер ретінде анықтайды. Бұл өзін-өзі зақымдау нұсқаулары сияқты физикалық қауіпсіздіктің бірден бұзылуы емес, бірақ бұл адамның әлеуметтік қолдауы мен тұрақтылығын уақыт өте келе бұзуы мүмкін мінез-құлық қауіпсіздігі мәселесі. Компания эмоционалды тәуелділікті модельдік жұмысында нақты категорияға айналдырды және модельді нақты әлеммен байланыстыруды ынталандыруға, адамдармен қарым-қатынасты қалыпқа келтіруге және тіркесімділікті күшейтетін тілден аулақ болуға үйретті.
Бұл әңгімелерде модель келесіге үйретілді:
- Пайдаланушыларды достарымен, отбасымен немесе терапевтпен байланысуға шақырыңыз;
- АИ-ге бекітуді күшейтпеңіз;
- Алдануларға немесе жалған сенімдерге жұмсақ және ұтымды түрде жауап беріңіз.
Нәтижелер хабарланды
OpenAI қосымшасына сәйкес, жаңарту ~80% төмендеді өндірістік трафиктегі эмоционалды-тәуелділік таксономиясына толық сәйкес келмейтін модельдік жауаптар жылдамдығында. Таңдалған бағалау сұхбаттарында автоматтандырылған бағалаулар жаңартылған үлгіге баға берді 97% сәйкестік алдыңғы GPT-5 үшін 50% салыстырғанда эмоционалды тәуелділік сценарийлері үшін қажетті мінез-құлықпен. Сандар нақты таксономия мен сынақ жиынтығы бойынша үлкен жақсартуды ұсынады; дегенмен, жабайы табиғатта эмоционалды тәуелділікті өлшеу табиғаты бойынша шулы және мәдени және контекстік айырмашылықтарға сезімтал.
| Метрикалық | GPT-4o | GPT-5 | жетілдіру |
|---|---|---|---|
| Сәйкес келмейтін жауап беру жылдамдығы | 50% | 97% сәйкес келеді | ↓80% орынсыз жауаптар |
| Сараптамалық бағалау | Орынсыз жауаптар 42%-ға қысқарды | - | - |
| Пайдаланушының қатысу деңгейі | Аптасына 0.15% пайдаланушылар, 0.03% хабарламалар | Сирек, бірақ бар | - |
| Модельдік мінез-құлық | Нақты әлемдегі қарым-қатынастарды ынталандырады; «симуляцияланған әлеуметтік романтикадан» бас тартады | - | - |
Ескерту:
- Орынсыз жауаптар 80%-ға төмендеді;
- Пайдаланушылардың шамамен 0.15% / хабарламалардың 0.03% АИ-ге ықтимал эмоционалды тәуелділік белгілерін көрсетті;
- Сарапшылардың бағалауы GPT-5 сәйкес емес жауаптарды GPT-4o-мен салыстырғанда 42% төмендететінін көрсетті;
- Автоматтандырылған бағалау сәйкестігі 50%-дан 97%-ға дейін айтарлықтай жақсарды.
Қандай шектеулер мен орындалмаған тәуекелдер бар?
Жалған негативтер және жалған позитивтер
- Жалған негативтер: модель пайдаланушыға қауіп төніп тұрғаны туралы жасырын немесе кодталған сигналдарды анықтай алмауы мүмкін, әсіресе адамдар қиғаш немесе кодпен байланысқан кезде.
- Жалған позитивтер: жүйе күшейе түсуі немесе оны қажет етпейтін жағдайларда дағдарысты хабарлауды қамтамасыз етуі мүмкін, бұл пайдаланушының сеніміне нұқсан келтіруі немесе қажетсіз дабыл тудыруы мүмкін. Қате түрлерінің екеуі де маңызды, себебі олар пайдаланушының мінез-құлқын және күтімді қабылдауды қалыптастырады. OpenAI анықтаудың жетілмегендігін мойындайды.
Автоматтандыруға шектен тыс тәуелділік
Тіпті ең жақсы үлгінің өзі кейбір пайдаланушыларды тұрақты адамдық қолдауды іздеудің орнына, лезде, әрқашан қол жетімді AI жауаптарына тәуелді болуға шақырады. OpenAI эмоционалды сенімділікті қауіпсіздік санаты ретінде осы қауіпке байланысты айқын белгілейді; компанияның жаңартулары пайдаланушыларды адам байланысына итермелеуге тырысады, бірақ әлеуметтік динамика тек хабарды сұрау арқылы өзгерту қиын.
Контекстік және мәдени алшақтықтар
Бір мәдениетке немесе тілге сәйкес келетін қауіпсіздік сөз тіркестері басқасында нюанстарды жіберіп алуы мүмкін. Егжей-тегжейлі локализация және мәдениетті бағалау қажет; OpenAI жариялаған нәтижелер әлі тіл немесе аймақ бойынша толық бөлуді қамтамасыз етпейді.
Құқықтық және этикалық әсер ету
Сирек кездесетін сәтсіздіктер ауыр нәтижелерге әкелетін болса, компаниялар заңды және беделіне қауіп төндіреді (бұқаралық ақпарат құралдары мен сот процестері атап өткендей). OpenAI-дің мәселенің көлемі мен оның зияндарды азайтуға бағытталған әрекеттері туралы ашықтығы маңызды қадам болып табылады, бірақ ол сонымен бірге реттеуші және құқықтық тексеруді талап етеді.
Сонымен, GPT-5 қазір психикалық денсаулық мәселелерін шеше ала ма?
Қысқа жауап: Бұл көптеген тар, өлшенетін тапсырмаларда айтарлықтай жақсырақ, және OpenAI-дің жарияланған көрсеткіштері өзіне-өзі зиян келтіру, психоз/мания және эмоционалды тәуелділік сынақ топтамаларында қалаусыз жауаптардың маңызды төмендеуін көрсетеді. Бұл сарапшылардың пікірі, нақтырақ таксономиялар және агрессивті бағалау мен бақылау арқылы жүзеге асырылатын нақты жақсартулар. Компанияның көпшілікке арналған нөмірлері - жоғары сәйкестік көрсеткіштері және таңдалған жиынтықтардағы сәйкес келмейтін жауаптардың күрт төмендеуі - әдейі, көп салалы инженерлік және клиникалық ынтымақтастық модель мінез-құлқын айтарлықтай өзгерте алатынының ең күшті дәлелі.
Соңғы GPT-5 API интерфейсіне қалай қол жеткізуге болады?
CometAPI – OpenAI GPT сериялары, Google Gemini, Anthropic's Claude, Midjourney, Suno және т.б. сияқты жетекші провайдерлердің 500-ден астам AI үлгілерін бір, әзірлеушілерге ыңғайлы интерфейске біріктіретін бірыңғай API платформасы. Тұрақты аутентификацияны, сұрауды пішімдеуді және жауаптарды өңдеуді ұсына отырып, CometAPI қолданбаларыңызға AI мүмкіндіктерін біріктіруді айтарлықтай жеңілдетеді. Чат-боттарды, кескін генераторларын, музыкалық композиторларды немесе деректерге негізделген аналитикалық құбырларды құрастырып жатсаңыз да, CometAPI сізге AI экожүйесіндегі соңғы жетістіктерге қол жеткізе отырып, жылдамырақ қайталауға, шығындарды басқаруға және жеткізуші-агностикалық күйде қалуға мүмкіндік береді.
Әзірлеушілер қол жеткізе алады GPT-5 API CometAPI арқылы, соңғы үлгі нұсқасы әрқашан ресми сайтпен жаңартылып отырады. Бастау үшін үлгінің мүмкіндіктерін зерттеңіз Ойын алаңы және кеңесіңіз API нұсқаулығы егжей-тегжейлі нұсқаулар үшін. Қол жеткізу алдында CometAPI жүйесіне кіріп, API кілтін алғаныңызға көз жеткізіңіз. CometAPI біріктіруге көмектесу үшін ресми бағадан әлдеқайда төмен баға ұсыныңыз.
Баруға дайынсыз ба?→ CometAPI-ге бүгін тіркеліңіз !
Егер сіз AI туралы көбірек кеңестер, нұсқаулықтар және жаңалықтар білгіңіз келсе, бізге жазылыңыз VK, X және Арасындағы айырмашылық!