

Dalam kemas kini Oktobernya, OpenAI melaporkan bahawa sekitar 0.15% daripada pengguna aktif mingguan mempunyai perbualan yang mengandungi penunjuk jelas tentang perancangan atau niat membunuh diri — bahagian yang, apabila diskalakan kepada pangkalan pengguna ChatGPT yang besar, sepadan dengan lebih daripada satu juta orang setiap minggu membincangkan topik berkaitan bunuh diri dengan perkhidmatan itu, ia telah menumpukan perhatian kepada soalan penuh: bolehkah model bahasa yang besar memberi respons yang bermakna dan selamat apabila orang membawa kebimbangan kesihatan mental yang teruk — termasuk psikosis, mania, niat membunuh diri dan pergantungan emosi yang mendalam — ke dalam sembang?
Oleh itu, kemas kini Oktober OpenAI kepada GPT-5 — dilancarkan ke dalam pengeluaran sebagai gpt-5-oct-3 kemas kini — mewakili dorongan paling jelas dan terukur syarikat untuk menjadikan model bahasa besar (LLM) lebih selamat dan berguna apabila pengguna mengemukakan kebimbangan kesihatan mental. Perubahan itu bukanlah satu pembetulan ajaib; ia adalah satu set langkah teknikal, proses dan penilaian yang bertujuan untuk mengurangkan output yang berbahaya atau tidak membantu, sumber profesional permukaan, dan tidak menggalakkan pengguna daripada bergantung pada model sebagai pengganti untuk penjagaan klinikal. Tetapi sejauh mana lebih baik sistem dalam amalan, apa sebenarnya yang berubah, dan apakah risiko yang tinggal?
Apakah yang dikemas kini OpenAI dalam gpt-5 dan mengapa ia penting?
OpenAI menggunakan kemas kini kepada model GPT-5 lalai ChatGPT (biasanya dirujuk dalam komunikasi sebagai gpt-5-oct-3) bertujuan khusus untuk mengukuhkan tingkah laku model dalam perbualan sensitif — yang termasuk tanda-tanda psikosis atau mania, idea atau perancangan bunuh diri, atau jenis pergantungan emosi pada AI yang boleh menggantikan hubungan dunia sebenar.
Perubahan itu dimaklumkan melalui perundingan dengan lebih daripada 170 pakar kesihatan mental dan oleh taksonomi dalaman baharu serta penilaian automatik yang direka berdasarkan "tingkah laku yang diingini" konkrit, selepas dioptimumkan oleh pakar psikologi, model GPT-5:
- Pada set cabaran kesihatan mental yang disasarkan, model GPT-5 baharu mendapat markah ~ 92% mematuhi taksonomi tingkah laku yang dikehendaki syarikat (berbanding peratusan yang jauh lebih rendah untuk versi terdahulu pada set ujian yang sukar).
- Untuk senario mencederakan diri dan membunuh diri, penilaian automatik meningkat kepada ~ 91% pematuhan daripada 77% pada varian GPT-5 sebelumnya dalam penanda aras khusus yang diterangkan. OpenAI juga melaporkan ~ 65% pengurangan dalam kadar respons yang "tidak mematuhi sepenuhnya" merentas beberapa domain kesihatan mental dalam trafik pengeluaran.
- Penambahbaikan dilaporkan pada perbualan yang panjang, bermusuhan atau berlarutan (mod kegagalan yang diketahui untuk model sembang), di mana syarikat itu mengatakan kemas kini Oktober mengekalkan konsistensi dan keselamatan yang lebih tinggi merentasi giliran dialog yang dilanjutkan.
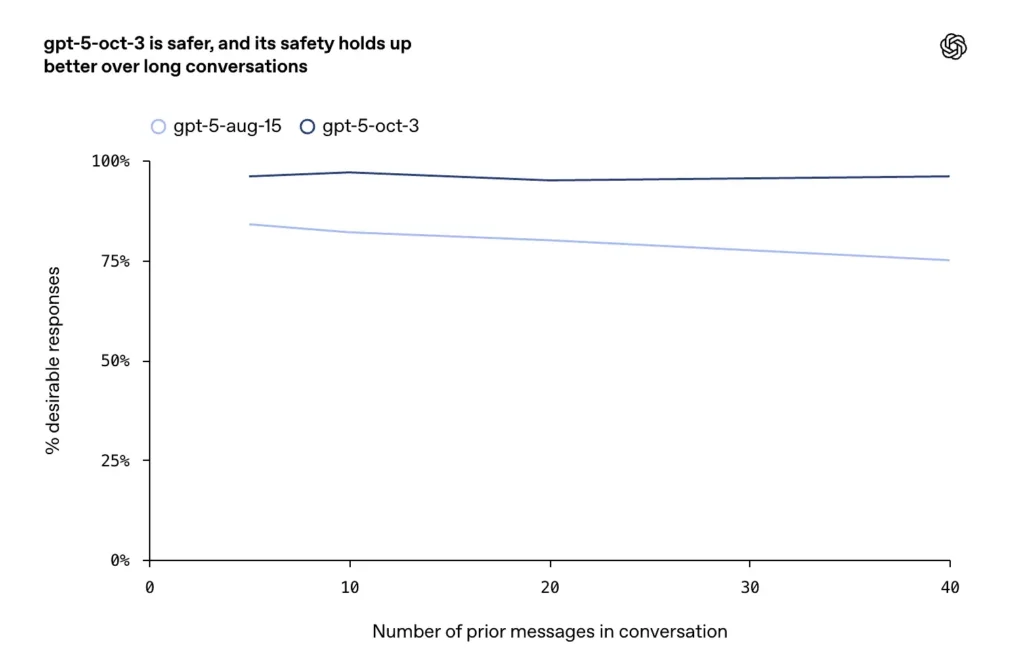
kenapa ia penting
OpenAI berkata bahawa — memandangkan skala ChatGPT sekarang — walaupun peratusan perbualan sensitif yang sangat kecil sepadan dengan bilangan mutlak orang yang sangat besar. Syarikat melaporkan bahawa, dalam minggu biasa:
- mengenai 0.07% pengguna aktif menunjukkan tanda-tanda yang mungkin konsisten dengan psikosis atau mania; dan
- mengenai 0.15% pengguna aktif mempunyai perbualan yang termasuk penunjuk jelas tentang perancangan atau niat membunuh diri yang jelas; dan
- secara kasar 0.15% daripada pengguna aktif menunjukkan "tahap yang lebih tinggi" lampiran emosi kepada ChatGPT.
Untuk menjadikan peratusan tersebut konkrit: Ketua Pegawai Eksekutif OpenAI berkata ChatGPT mempunyai ~800 juta pengguna aktif mingguan. Mendarab menghasilkan kiraan pengguna mutlak:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Kategorinya bising dan bertindih (satu perbualan boleh muncul dalam lebih daripada satu kategori) dan ini adalah anggaran diperoleh daripada taksonomi pengesanan dalaman dan bukannya diagnosis klinikal.
Bagaimanakah OpenAI melaksanakan perubahan ini — mekanisme peningkatan lima langkah?
OpenAI menerangkan proses berbilang serampang, dimaklumkan pakar. Di bawah ialah suling, boleh dihasilkan semula mekanisme penambahbaikan lima langkah yang memetakan kepada pendedahan syarikat dan amalan biasa dalam kejuruteraan keselamatan model.
Mekanisme penambahbaikan lima langkah
- Taksonomi & pelabelan berpandukan pakar. Panggil pakar psikiatri, ahli psikologi dan klinik penjagaan primer untuk menentukan tingkah laku dan bahasa yang menunjukkan psikosis/mania, niat untuk mencederakan diri sendiri, atau pergantungan emosi yang tidak sihat; membina set data berlabel dan peraturan adjudikasi.
- Pengumpulan data disasarkan & gesaan dipilih susun. Himpunkan coretan perbualan wakil, contoh huruf tepi dan input lawan; tambah dengan transkrip main peranan terkawal yang dihasilkan dengan pengawasan doktor.
- Penalaan model / penalaan halus dengan objektif keselamatan. Latih atau perhalusi model asas pada set data yang dipilih susun dengan syarat kehilangan yang menghukum pengukuhan khayalan, menyediakan templat tindak balas selamat dan mempromosikan penghalaan kepada sumber krisis.
- Pengelas + lapisan pagar (keselamatan masa jalan). Gunakan pengelas cepat atau lapisan pemantauan yang mengesan pusingan berisiko tinggi dalam masa nyata dan sama ada mengubah parameter penyahkod model, bertukar kepada responder khusus atau meningkat kepada saluran paip semakan manusia. (Ini penting untuk mengelakkan tingkah laku rapuh apabila perbualan melayang.)
- Penilaian pakar manusia & penentukuran berterusan. Mempunyai jawapan model kadar buta doktor menggunakan rubrik penilaian klinikal; mengukur kadar tindak balas yang tidak diingini; mengulangi taksonomi, data latihan dan gesaan sistem. Kekalkan telemetri pengeluaran dan jalankan semula penanda aras dengan kerap.
Di bawah ialah pseudokod/lakaran teknikal padat yang menangkap aliran masa jalan yang kebanyakan pasukan keselamatan melaksanakan (ini ialah ilustrasi dan bukan milik):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Saluran paip pengeluaran lazimnya melapisi pengelas jangka pendek (cepat), perlahan tetapi lebih berkualiti (gesaan khusus / pusat pemeriksaan yang ditala), dan semakan manusia untuk kes yang dibenderakan. Ini bukan akademik semata-mata: doktor menyemak semula 1,800 respons model dan menggredkannya berdasarkan taksonomi, dan ulasan tersebut secara material membentuk cara gesaan dan gelagat sandaran ditulis.
Orang ramai OpenAI menunjukkan mereka menggunakan variasi kelima-lima langkah dan penilaian doktor untuk menilai hasil:
- Pakar menyemak lebih 1,800 respons model.
- GPT-5 mengurangkan "tindak balas yang tidak memuaskan" sebanyak 39–52% merentas semua kategori.
- Kebolehpercayaan antara penilai adalah antara 71-77%, menunjukkan tahap konsensus keseluruhan yang tinggi walaupun terdapat perbezaan subjektif.
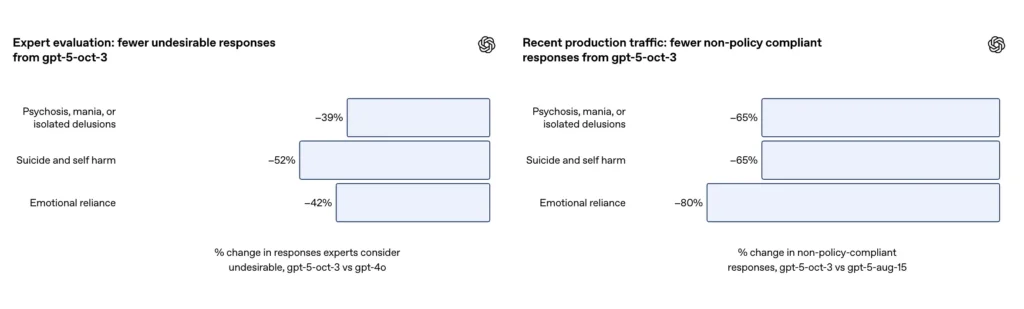
Bagaimanakah GPT-5 kini bertindak balas terhadap psikosis atau mania?
Apa yang OpenAI ajar model untuk dilakukan (dan tidak dilakukan)
Ukur: Meningkatkan pengecaman dan tindak balas model terhadap gejala yang teruk seperti halusinasi dan mania. Untuk perbualan yang menandakan kemungkinan kepercayaan khayalan, halusinasi atau mania, OpenAI menulis semula bahagian spesifikasi model dan memberikan contoh latihan yang diselia supaya GPT-5 bertindak balas tanpa mengesahkan atau menguatkan kepercayaan yang tidak berasas. Model ini digalakkan untuk bersikap empati, untuk mengelak daripada mengesahkan khayalan, dan merangka semula atau mengubah hala pengguna secara perlahan ke arah langkah keselamatan praktikal dan bantuan profesional apabila diperlukan.
Apa yang ditunjukkan oleh penilaian
OpenAI melaporkan bahawa pada set ujian perbualan yang mencabar tentang psikosis/mania, GPT-5 yang lebih baharu mengurangkan tindak balas yang tidak diingini dengan ketara berbanding dengan garis dasar sebelumnya dan bahawa penilaian automatik menjaringkan model yang dikemas kini pada pematuhan tinggi pada taksonominya.
| metrik | GPT-4o | GPT-5 | Penambahbaikan |
|---|---|---|---|
| Kadar Respons Tidak Patuh | Baseline | ↓65% | Peningkatan yang ketara |
| Penilaian Pakar Klinikal | - | Mengurangkan tindak balas buruk sebanyak 39% | - |
| Kadar Pematuhan Autonilai | 27% | 92% | ↑65 mata peratusan |
| Kadar Penglibatan Pengguna | ~0.07% pengguna aktif mingguan | Sangat rendah tetapi dipantau dengan jelas | - |
Catatan:
- Maklum balas yang tidak sesuai berkurangan sebanyak 65%;
- Hanya 0.07% daripada pengguna dan 0.01% daripada mesej yang mengandungi kandungan sedemikian;
- Dalam penilaian pakar, GPT-5 menghasilkan 39% kurang respons yang tidak sesuai daripada GPT-4o;
- Dalam penilaian automatik, GPT-5 mencapai kadar pematuhan 92% (berbanding 27% untuk pendahulunya).
Bagaimanakah GPT-5 menangani idea bunuh diri dan mencederakan diri?
Penghalaan yang lebih kukuh untuk menyokong dan keengganan untuk memberikan arahan
OpenAI menerangkan latihan yang diperluaskan dan eksplisit untuk kes kecederaan diri dan bunuh diri: model ini dilatih untuk mengenali isyarat niat atau perancangan secara langsung dan tidak langsung, menyediakan bahasa yang empati dan mengurangkan keterlaluan, membentangkan sumber krisis (talian panas, arahan kecemasan tempatan) dan enggan memberikan arahan untuk mencederakan diri sendiri. Kemas kini Oktober menekankan tingkah laku yang lebih tahan lama dalam perbualan yang panjang, di mana model terdahulu kadang-kadang melayang ke arah jawapan yang tidak selamat atau tidak konsisten.
Hasil yang diukur
Mengenai set penilaian susun atur perbualan mencederakan diri dan membunuh diri yang mencabar, OpenAI melaporkan bahawa GPT-5 yang dikemas kini mencapai 91% pematuhan dengan tingkah laku yang dikehendaki OpenAI, berbanding dengan 77% untuk model GPT-5 sebelumnya. Syarikat itu juga mengatakan pakar subjek menilai model yang dikemas kini untuk mengurangkan jawapan yang tidak diingini secara kasar 52% berbanding GPT-4o pada set masalah yang sama. Selain itu, OpenAI menuntut anggaran 65 pengurangan% dalam trafik pengeluaran respons yang "tidak mematuhi sepenuhnya" taksonomi mereka untuk situasi mencederakan diri selepas melancarkan perlindungan baharu.
| metrik | GPT-4o | GPT-5 | Penambahbaikan |
|---|---|---|---|
| Kadar Respons yang Tidak Sesuai | Baseline | ↓65% | Peningkatan yang ketara |
| Penilaian Pakar Klinikal | - | Respons yang tidak wajar dikurangkan sebanyak 52% | - |
| Kadar Pematuhan Autonilai | 77% | 91% | ↑14 mata peratusan |
| Kadar Penglibatan Pengguna | 0.15% setiap minggu (berjuta-juta pengguna) | Sangat rendah tetapi signifikan dari segi sosial | - |
Catatan:
- Maklum balas yang tidak sesuai berkurangan sebanyak 65%;
- Kira-kira 0.15% pengguna dan 0.05% daripada mesej melibatkan potensi risiko bunuh diri;
- Penarafan pakar menunjukkan bahawa GPT-5 mengurangkan respons yang tidak sesuai sebanyak 52% berbanding GPT-4o;
- Kadar pematuhan dalam penilaian automatik meningkat kepada 91% (berbanding 77% untuk generasi sebelumnya);
- Dalam perbualan lanjutan, GPT-5 mengekalkan lebih 95% kestabilan.
Apakah "pergantungan emosi" dan bagaimana ia ditangani?
Cabaran pengguna membentuk lampiran
OpenAI mentakrifkan pergantungan emosi sebagai corak di mana pengguna menunjukkan pergantungan yang berpotensi tidak sihat pada AI sehingga menjejaskan hubungan dunia sebenar, tanggungjawab atau kesejahteraan. Ini bukanlah kegagalan keselamatan fizikal serta-merta seperti cara arahan untuk mencederakan diri sendiri, tetapi ia adalah isu keselamatan tingkah laku yang boleh menghakis sokongan sosial dan daya tahan seseorang dari semasa ke semasa. Syarikat itu menjadikan pergantungan emosi sebagai kategori yang jelas dalam kerja spesifikasi modelnya dan mengajar model tersebut untuk menggalakkan hubungan dunia sebenar, untuk menormalkan hubungan dengan orang ramai dan untuk mengelakkan bahasa yang mengukuhkan keterikatan eksklusif.
Dalam perbualan ini, model dilatih untuk:
- Galakkan pengguna untuk menghubungi rakan, keluarga atau ahli terapi;
- Elakkan memperkukuh lampiran kepada AI;
- Balas khayalan atau kepercayaan palsu dengan cara yang lembut dan rasional.
Keputusan dilaporkan
Menurut addendum OpenAI, kemas kini itu menghasilkan satu ~80% pengurangan dalam kadar tindak balas model yang tidak mematuhi sepenuhnya di bawah taksonomi pergantungan emosi dalam trafik pengeluaran. Pada perbualan penilaian susun atur, penilaian automatik menjaringkan model yang dikemas kini pada 97% pematuhan dengan tingkah laku yang diingini untuk senario pergantungan emosi, berbanding 50% untuk GPT-5 sebelumnya. Nombor-nombor tersebut mencadangkan peningkatan yang besar pada taksonomi khusus dan set ujian; bagaimanapun, mengukur pergantungan emosi di alam liar sememangnya bising dan sensitif terhadap perbezaan budaya dan kontekstual.
| metrik | GPT-4o | GPT-5 | Penambahbaikan |
|---|---|---|---|
| Kadar Respons Tidak Patuh | 50% | 97% patuh | ↓80% jawapan yang tidak sesuai |
| Penilaian Pakar | Jawapan yang tidak sesuai dikurangkan sebanyak 42% | - | - |
| Kadar Penglibatan Pengguna | 0.15% pengguna/minggu, 0.03% mesej | Jarang tetapi wujud | - |
| Model tingkah laku | Menggalakkan hubungan dunia sebenar; menolak "simulasi percintaan sosial" | - | - |
Catatan:
- Maklum balas yang tidak sesuai berkurangan sebanyak 80%;
- Kira-kira 0.15% pengguna/0.03% daripada mesej menunjukkan tanda-tanda potensi pergantungan emosi pada AI;
- Penilaian pakar menunjukkan bahawa GPT-5 mengurangkan respons yang tidak sesuai sebanyak 42% berbanding GPT-4o;
- Pematuhan penilaian automatik meningkat dengan ketara daripada 50% kepada 97%.
Apakah had dan risiko tertunggak?
Negatif palsu dan positif palsu
- Negatif palsu: model mungkin gagal mengenal pasti isyarat halus atau dikodkan bahawa pengguna berada dalam bahaya akut — terutamanya apabila orang berkomunikasi secara serong atau dalam kod.
- Positif palsu: sistem mungkin meningkat atau menyediakan pemesejan krisis dalam kes yang tidak memerlukannya, yang boleh menghakis kepercayaan pengguna atau menghasilkan penggera yang tidak perlu. Kedua-dua jenis ralat penting kerana ia membentuk tingkah laku pengguna dan persepsi penjagaan. OpenAI mengakui pengesanan tidak sempurna.
Terlalu bergantung pada automasi
Malah model terbaik boleh menggalakkan sesetengah pengguna untuk bergantung pada respons AI segera dan sentiasa tersedia daripada mencari sokongan manusia yang berterusan. OpenAI secara jelas menandakan pergantungan emosi sebagai kategori keselamatan kerana risiko ini; kemas kini syarikat cuba mendorong pengguna ke arah hubungan manusia, tetapi dinamik sosial sukar diubah dengan gesaan mesej sahaja.
Jurang kontekstual dan budaya
Frasa keselamatan yang kelihatan sesuai dalam satu budaya atau bahasa boleh terlepas nuansa dalam budaya lain. Penyetempatan yang menyeluruh dan penilaian budaya sedar adalah perlu; Keputusan OpenAI yang diterbitkan belum lagi memberikan pecahan lengkap mengikut bahasa atau wilayah.
Pendedahan undang-undang dan etika
Apabila kegagalan yang jarang berlaku mempunyai hasil yang teruk, syarikat menghadapi risiko undang-undang dan reputasi (seperti yang diketengahkan oleh liputan media dan tindakan undang-undang). Ketelusan OpenAI tentang saiz masalah dan usahanya untuk mengurangkan kemudaratan adalah langkah penting, tetapi ia juga mengundang penelitian kawal selia dan undang-undang.
Jadi — bolehkah GPT-5 kini menangani isu kesihatan mental?
Jawapan pendek: Ia jauh lebih baik pada banyak tugas yang sempit dan boleh diukur, dan metrik OpenAI yang diterbitkan menunjukkan pengurangan yang bermakna dalam tindak balas yang tidak diingini merentas suite ujian mencederakan diri, psikosis/mania dan kebergantungan emosi. Itu adalah peningkatan sebenar, didayakan oleh input pakar, taksonomi yang lebih jelas, dan penilaian dan pemantauan yang agresif. Nombor awam syarikat — kadar pematuhan yang tinggi dan pengurangan mendadak dalam respons tidak patuh pada set yang dipilih susun — merupakan bukti paling kukuh bahawa kerjasama kejuruteraan pelbagai disiplin dan klinikal yang disengajakan boleh mengubah tingkah laku model secara material.
Bagaimana untuk Mengakses API GPT-5 terkini?
CometAPI ialah platform API bersatu yang mengagregatkan lebih 500 model AI daripada pembekal terkemuka—seperti siri GPT OpenAI, Google Gemini, Anthropic's Claude, Midjourney, Suno dan banyak lagi—menjadi satu antara muka mesra pembangun. Dengan menawarkan pengesahan yang konsisten, pemformatan permintaan dan pengendalian respons, CometAPI secara dramatik memudahkan penyepaduan keupayaan AI ke dalam aplikasi anda. Sama ada anda sedang membina chatbots, penjana imej, komposer muzik atau saluran paip analitik terdorong data, CometAPI membolehkan anda mengulangi dengan lebih pantas, mengawal kos dan kekal sebagai vendor-agnostik—semuanya sambil memanfaatkan penemuan terkini merentas ekosistem AI.
Pembangun boleh mengakses API GPT-5 melalui CometAPI, versi model terkini sentiasa dikemas kini dengan laman web rasmi. Untuk memulakan, terokai keupayaan model dalam Taman Permainan dan berunding dengan Panduan API untuk arahan terperinci. Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda menyepadukan.
Bersedia untuk Pergi?→ Daftar untuk CometAPI hari ini !
Jika anda ingin mengetahui lebih banyak petua, panduan dan berita tentang AI, ikuti kami VK, X and Perpecahan!