

Pada 17 Jun 2025, peneraju AI yang berpangkalan di Shanghai, MiniMax (juga dikenali sebagai Teknologi Xiyu) secara rasmi mengeluarkan MiniMax-M1 (selepas ini “M1”)—model penaakulan perhatian hibrid berskala besar berat terbuka pertama di dunia. Menggabungkan seni bina Campuran Pakar (KPM) dengan mekanisme Perhatian Kilat yang inovatif, M1 mencapai prestasi peneraju industri dalam tugas berorientasikan produktiviti, menyaingi sistem sumber tertutup teratas sambil mengekalkan keberkesanan kos yang tiada tandingan. Dalam artikel mendalam ini, kami meneroka apa itu M1, cara ia berfungsi, ciri penentunya dan panduan praktikal tentang mengakses dan menggunakan model.
Apakah MiniMax-M1?
MiniMax-M1 mewakili kemuncak penyelidikan MiniMaxAI ke dalam mekanisme perhatian yang boleh skala dan cekap. Membina asas MiniMax-Text-01, lelaran M1 menyepadukan perhatian kilat dengan rangka kerja MoE untuk mencapai kecekapan yang tidak pernah berlaku sebelum ini semasa latihan dan inferens. Gabungan ini membolehkan model mengekalkan prestasi tinggi walaupun semasa memproses urutan yang sangat panjang — keperluan utama untuk tugasan yang melibatkan pangkalan kod, dokumen undang-undang atau kesusasteraan saintifik yang meluas.
Seni bina teras dan parameterisasi
Pada terasnya, MiniMax-M1 memanfaatkan sistem MoE hibrid yang mengarahkan token secara dinamik melalui subset sub-rangkaian pakar. Walaupun model itu mengandungi 456 bilion parameter secara keseluruhan, hanya 45.9 bilion yang diaktifkan untuk setiap token, mengoptimumkan penggunaan sumber. Reka bentuk ini mendapat inspirasi daripada pelaksanaan KPM terdahulu tetapi memperhalusi logik penghalaan untuk meminimumkan overhed komunikasi antara GPU semasa inferens teragih.
Perhatian kilat dan sokongan konteks panjang
Ciri yang menentukan MiniMax-M1 ialah mekanisme perhatian kilatnya, yang secara drastik mengurangkan beban pengiraan perhatian diri untuk jujukan yang panjang. Dengan menganggarkan matriks perhatian melalui gabungan kernel tempatan dan global, model ini mengurangkan FLOP sehingga 75% berbanding dengan transformer tradisional apabila memproses jujukan token 100K . Kecekapan ini bukan sahaja mempercepatkan inferens tetapi juga membuka pintu untuk mengendalikan tetingkap konteks sehingga satu juta token tanpa keperluan perkakasan yang melarang.
Bagaimanakah MiniMax-M1 mencapai kecekapan pengiraan?
Keuntungan kecekapan MiniMax-M1 berpunca daripada dua inovasi utama: seni bina Campuran Pakar hibridnya dan algoritma pembelajaran tetulang CISPO novel yang digunakan semasa latihan. Bersama-sama, elemen ini mengurangkan kedua-dua masa latihan dan kos inferens, membolehkan percubaan dan penggunaan pantas.
Penghalaan Campuran Hibrid Pakar
Komponen KPM menggunakan 32 sub-rangkaian pakar, setiap satu mengkhusus dalam aspek penaakulan yang berbeza atau tugas khusus domain. Semasa inferens, mekanisme gating yang dipelajari secara dinamik memilih pakar yang paling relevan untuk setiap token, mengaktifkan hanya sub-rangkaian yang diperlukan untuk memproses input. Pengaktifan terpilih ini mengurangkan pengiraan berlebihan dan mengurangkan permintaan lebar jalur memori, memberikan MiniMax-M1 kelebihan yang ketara dalam kecekapan kos berbanding model pengubah monolitik .
CISPO: Algoritma pembelajaran pengukuhan baru
Untuk meningkatkan lagi kecekapan latihan, MiniMaxAI membangunkan CISPO (Clipped Importance Sampling with Partial Overrides), algoritma RL yang menggantikan kemas kini berat peringkat token dengan keratan berasaskan pensampelan kepentingan. CISPO mengurangkan isu letupan berat yang biasa dalam persediaan RL berskala besar, mempercepatkan penumpuan dan memastikan peningkatan dasar yang stabil merentas pelbagai penanda aras. Akibatnya, latihan RL penuh MiniMax-M1 pada 512 H800 GPU siap dalam masa tiga minggu sahaja, menelan belanja kira-kira $534,700 — sebahagian kecil daripada kos yang dilaporkan untuk latihan GPT-4 yang setanding.
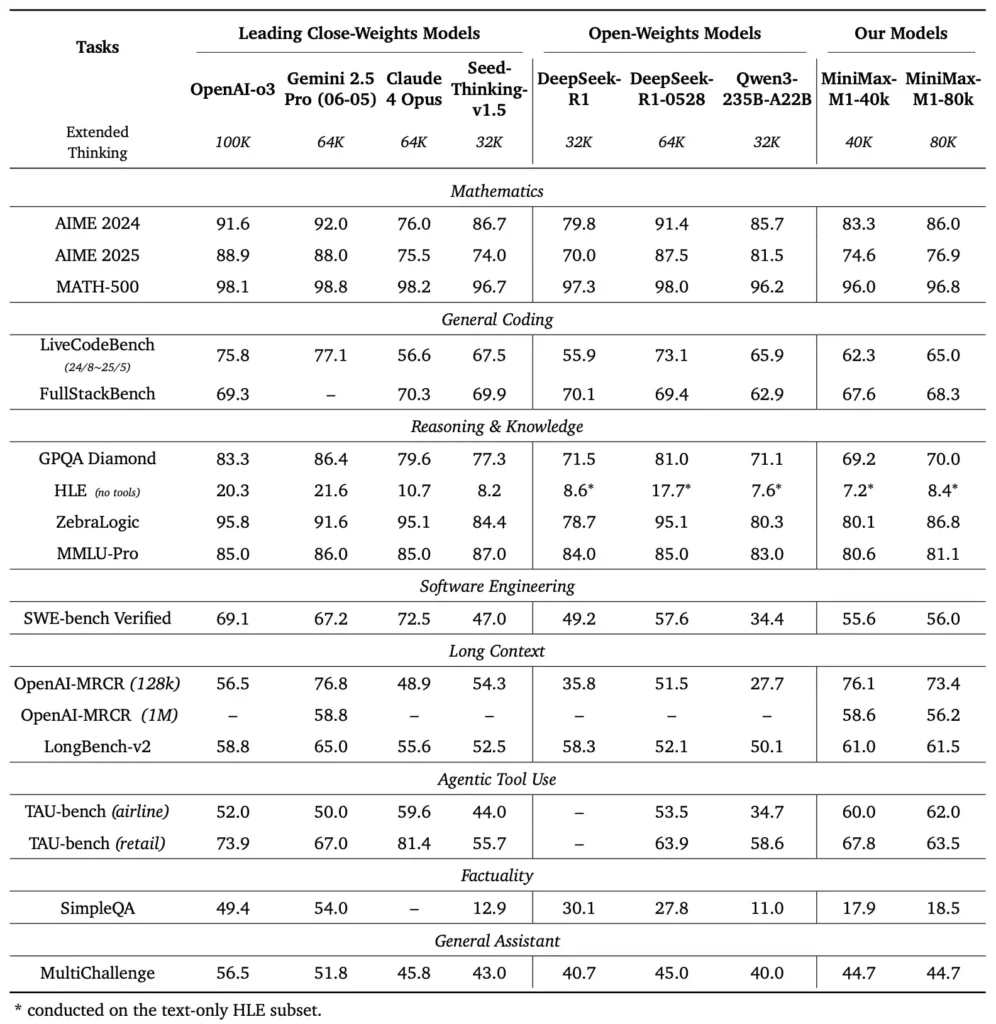
Apakah penanda aras prestasi MiniMax-M1?
MiniMax-M1 cemerlang dalam pelbagai penanda aras standard dan domain khusus, menunjukkan kehebatannya dalam mengendalikan penaakulan konteks panjang, penyelesaian masalah matematik dan penjanaan kod.
Tugas penaakulan konteks panjang
Dalam ujian pemahaman dokumen yang meluas, MiniMax-M1 memproses tetingkap konteks sehingga 1,000,000 token, mengatasi DeepSeek-R1 dengan faktor lapan dalam panjang konteks maksimum dan mengurangkan separuh keperluan pengiraan untuk jujukan 100K token . Pada penanda aras seperti penilaian konteks lanjutan NarrativeQA, model ini mencapai skor pemahaman terkini, yang dikaitkan dengan keupayaan perhatian kilatnya untuk menangkap kedua-dua kebergantungan tempatan dan global dengan cekap.
Kejuruteraan perisian dan penggunaan alat
MiniMax-M1 telah dilatih secara khusus mengenai persekitaran kejuruteraan perisian kotak pasir menggunakan RL berskala besar, membolehkannya menjana dan menyahpepijat kod dengan ketepatan yang luar biasa. Dalam penanda aras pengekodan seperti HumanEval dan MBPP, model itu mencapai kadar lulus yang setanding atau melebihi Qwen3-235B dan DeepSeek-R1, terutamanya dalam pangkalan kod berbilang fail dan tugasan yang memerlukan rujukan silang segmen kod panjang . Tambahan pula, demonstrasi awal MiniMaxAI mempamerkan keupayaan model untuk disepadukan dengan alat pembangun, daripada menjana saluran paip CI/CD kepada aliran kerja autodokumentasi.
Bagaimanakah pemaju boleh mengakses MiniMax-M1?
Untuk memupuk penerimaan yang meluas, MiniMaxAI telah menjadikan MiniMax-M1 tersedia secara bebas sebagai model berat terbuka. Pembangun boleh mengakses pusat pemeriksaan terlatih, berat model dan kod inferens melalui repositori GitHub rasmi.
Keluaran berat terbuka pada GitHub
MiniMaxAI menerbitkan fail model MiniMax-M1 dan skrip yang disertakan di bawah lesen sumber terbuka yang permisif di GitHub. Pengguna yang berminat boleh mengklon repositori di https://github.com/MiniMax-AI/MiniMax-M1, yang menganjurkan pusat pemeriksaan untuk kedua-dua varian belanjawan token 40K dan 80K, serta contoh penyepaduan untuk rangka kerja ML biasa seperti PyTorch dan TensorFlow .
Titik akhir API dan penyepaduan awan
Di luar penggunaan tempatan, MiniMaxAI telah bekerjasama dengan penyedia awan utama untuk menawarkan perkhidmatan API terurus. Melalui perkongsian ini, pembangun boleh memanggil MiniMax-M1 melalui titik akhir RESTful, dengan SDK tersedia untuk Python, JavaScript dan Java. API termasuk parameter boleh dikonfigurasikan untuk panjang konteks, ambang penghalaan pakar dan belanjawan token, yang membolehkan pengguna menyesuaikan prestasi dengan kes penggunaan mereka sambil memantau penggunaan pengiraan dalam masa nyata .
Bagaimana untuk mengintegrasikan dan menggunakan MiniMax-M1 dalam aplikasi sebenar?
Memanfaatkan keupayaan MiniMax-M1 memerlukan pemahaman corak APInya, amalan terbaik untuk gesaan konteks panjang dan strategi untuk orkestrasi alat.
Contoh penggunaan API asas
Panggilan API biasa melibatkan penghantaran muatan JSON yang mengandungi teks input dan penggantian konfigurasi pilihan. Contohnya:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Respons mengembalikan JSON berstruktur dengan teks yang dijana, statistik penggunaan token dan log penghalaan, membolehkan pemantauan terperinci pengaktifan pakar .
Penggunaan alat dan Agen MiniMax
Di samping model teras, MiniMaxAI telah memperkenalkan MiniMax Agent, rangka kerja ejen beta yang boleh memanggil alat luaran—bermula daripada persekitaran pelaksanaan kod kepada pengikis web—di bawah hud. Pembangun boleh membuat seketika sesi ejen yang merangkaikan penaakulan model dengan penyeruan alat, contohnya, untuk mendapatkan semula data masa nyata, melakukan pengiraan atau mengemas kini pangkalan data. Paradigma ejen ini memudahkan pembangunan aplikasi hujung-ke-hujung, membolehkan MiniMax-M1 berfungsi sebagai orkestra dalam aliran kerja yang kompleks.
Amalan terbaik dan perangkap
- Kejuruteraan segera untuk konteks yang panjang: Pecahkan input kepada segmen yang koheren, benamkan ringkasan pada selang masa yang logik, dan gunakan strategi "ringkaskan kemudian sebab" untuk mengekalkan fokus model.
- Pengiraan vs. tukar ganti prestasi: Eksperimen dengan ambang pakar yang lebih rendah atau belanjawan pemikiran yang dikurangkan (cth, varian 40K) untuk aplikasi sensitif kependaman.
- Pemantauan dan tadbir urus: Gunakan log laluan dan statistik token untuk mengaudit penggunaan pakar dan memastikan pematuhan dengan belanjawan kos, terutamanya dalam persekitaran pengeluaran.
Dengan mengikuti garis panduan ini, pembangun boleh memanfaatkan kekuatan MiniMax-M1—pengendalian konteks yang luas dan penaakulan yang cekap—sambil mengurangkan risiko yang berkaitan dengan penggunaan model berskala besar.
Bagaimanakah anda menggunakan MiniMax-M1?
Setelah dipasang, M1 boleh digunakan melalui skrip Python mudah atau buku nota interaktif.
Apakah Rupa Skrip Inferens Asas?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Sampel ini menggunakan varian 40 k-bajet; bertukar kepada "MiniMax-AI/MiniMax-M1-80k" membuka kunci belanjawan penaakulan 80 k penuh ().
Bagaimana Anda Mengendalikan Konteks Ultra-Panjang?
Untuk input yang melebihi saiz penimbal biasa, M1 menyokong tokenisasi penstriman. Gunakan stream=True benderakan dalam tokenizer untuk menyuap token dalam ketulan, dan memanfaatkan inferens pusat pemeriksaan-mula semula untuk mengekalkan prestasi berbanding jujukan berjuta-token.
Bagaimanakah Anda Boleh Memperhalus atau Menyesuaikan M1?
Walaupun pusat pemeriksaan asas mencukupi untuk kebanyakan tugas, penyelidik boleh menggunakan penalaan halus RL menggunakan kod CISPO yang disertakan dalam repositori. Dengan membekalkan fungsi ganjaran tersuai—bermula daripada ketepatan kod kepada kesetiaan semantik—pengamal boleh menyesuaikan M1 kepada aliran kerja khusus domain.
Kesimpulan
MiniMax-M1 menonjol sebagai model AI yang terobosan, menolak sempadan pemahaman dan penaakulan bahasa konteks panjang. Dengan seni bina MoE hibridnya, mekanisme perhatian kilat dan rejimen latihan yang disokong CISPO, model ini menyampaikan prestasi tinggi pada tugasan daripada analisis undang-undang kepada kejuruteraan perisian, semuanya sekaligus mengurangkan perbelanjaan pengiraan secara mendadak. Terima kasih kepada keluaran berat terbuka dan tawaran API awan, MiniMax-M1 boleh diakses oleh spektrum luas pembangun dan organisasi yang tidak sabar-sabar untuk membina aplikasi berkuasa AI generasi akan datang. Memandangkan komuniti AI terus meneroka potensi model konteks besar, inovasi MiniMax-M1 bersedia untuk mempengaruhi penyelidikan dan pembangunan produk masa depan di seluruh industri.
Bermula
CometAPI menyediakan antara muka REST bersatu yang mengagregatkan ratusan model AI—termasuk keluarga ChatGPT—di bawah titik akhir yang konsisten, dengan pengurusan kunci API terbina dalam, kuota penggunaan dan papan pemuka pengebilan. Daripada menyulap berbilang URL vendor dan bukti kelayakan.
Untuk bermula, terokai keupayaan model dalam Taman Permainan dan berunding dengan Panduan API untuk arahan terperinci. Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API.
Penyepaduan MiniMax‑M1 API terbaharu akan muncul di CometAPI tidak lama lagi, jadi nantikan!Sementara kami memuktamadkan muat naik Model MiniMax‑M1, teroka model kami yang lain di Halaman model atau cuba mereka dalam Taman Permainan AI. Model terbaru MiniMax dalam CometAPI ialah API Pratonton ABAB7 Minimax and API Video-01 MiniMax , rujuk:
