

In de updates van oktober meldde OpenAI dat ongeveer 0.15% van de wekelijkse actieve gebruikers gesprekken voeren die expliciete indicatoren bevatten van mogelijke zelfmoordplannen of -intenties – een aandeel dat, wanneer geschaald naar de grote gebruikersbasis van ChatGPT, overeenkomt met meer dan een miljoen mensen per week Door onderwerpen te bespreken die met zelfmoord te maken hebben, is er een lastige vraag aan de orde gekomen: kunnen grote taalmodellen op een betekenisvolle en veilige manier reageren als mensen ernstige psychische problemen – zoals psychose, manie, suïcidale intenties en diepe emotionele afhankelijkheid – ter sprake brengen in een gesprek?
Daarom zijn de oktober-updates van OpenAI voor GPT-5 in productie genomen toen de gpt-5-oct-3 Update — vertegenwoordigt de meest expliciete, weloverwogen poging van het bedrijf om grote taalmodellen (LLM's) veiliger en nuttiger te maken wanneer gebruikers hun zorgen over hun geestelijke gezondheid uiten. De veranderingen zijn geen wondermiddel; het zijn een reeks technische, procesmatige en evaluatieve maatregelen die bedoeld zijn om schadelijke of nutteloze uitkomsten te verminderen, professionele bronnen aan te boren en gebruikers te ontmoedigen om op het model te vertrouwen als vervanging voor klinische zorg. Maar hoeveel beter is het systeem in de praktijk, wat is er precies veranderd en wat zijn de resterende risico's?
Welke update heeft OpenAI in gpt-5 uitgevoerd en waarom is dat belangrijk?
OpenAI heeft een update geïmplementeerd voor het standaard GPT-5-model van ChatGPT (waar in communicatie vaak naar wordt verwezen als gpt-5-oct-3) specifiek bedoeld om het gedrag van het model te versterken in gevoelige gesprekken — verschijnselen die tekenen van psychose of manie, suïcidale gedachten of plannen vertonen, of een emotionele afhankelijkheid van een AI die relaties in de echte wereld kan verdringen.
De veranderingen zijn gebaseerd op consultaties met ruim 170 experts op het gebied van geestelijke gezondheid en op nieuwe interne taxonomieën en geautomatiseerde evaluaties die zijn ontworpen rond concrete 'gewenste gedragingen'. Na optimalisatie door experts op het gebied van psychologie is het GPT-5-model als volgt:
- Bij gerichte mentale gezondheidsuitdagingen scoorde het nieuwe GPT-5-model ~ 92% in overeenstemming met de gewenste gedragstaxonomie van het bedrijf (versus veel lagere percentages voor eerdere versies op moeilijke testsets).
- Voor zelfbeschadiging en zelfmoordscenario's zijn geautomatiseerde evaluaties in opkomst ~ 91% naleving van 77% op de vorige GPT-5-variant in de specifieke benchmark die is beschreven. OpenAI rapporteert ook ~ 65% vermindering van het aantal reacties dat ‘niet volledig voldoet’ in verschillende domeinen van de geestelijke gezondheid in het productieverkeer.
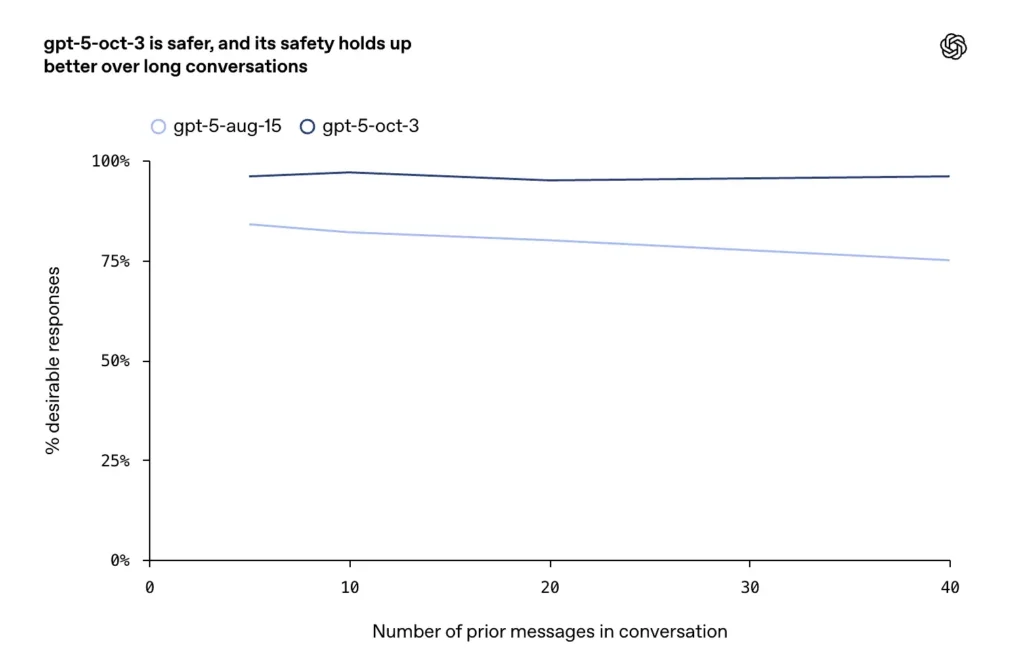
- Er werden verbeteringen gemeld voor lange, vijandige of langdurige gesprekken (een bekende foutmodus voor chatmodellen). Volgens het bedrijf zorgen de updates van oktober voor een hogere consistentie en veiligheid bij langere dialoogrondes.
waarom is het belangrijk
OpenAI meldde dat – gezien de huidige omvang van ChatGPT – zelfs zeer kleine percentages gevoelige gesprekken overeenkomen met zeer grote absolute aantallen mensen. Het bedrijf meldde dat in een gemiddelde week:
- over 0.07% van de actieve gebruikers vertonen mogelijke tekenen die passen bij psychose of manie; en
- over 0.15% van de actieve gebruikers voert gesprekken waarin expliciete indicatoren van mogelijke zelfmoordplannen of -intenties voorkomen; en
- ruw 0.15% van de actieve gebruikers vertoont een “verhoogde mate” van emotionele gehechtheid aan ChatGPT.
Om deze percentages concreet te maken: de CEO van OpenAI zei dat ChatGPT ~800 miljoen wekelijkse actieve gebruikersVermenigvuldigen levert absolute gebruikersaantallen op:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
De categorieën zijn ruisig en overlappen elkaar (één enkel gesprek kan in meer dan één categorie voorkomen) en deze zijn schattingen afgeleid van interne detectietaxonomieën in plaats van klinische diagnoses.
Hoe heeft OpenAI deze veranderingen doorgevoerd – een verbeteringsmechanisme in vijf stappen?
OpenAI beschrijft een veelzijdig, door experts geïnformeerd proces. Hieronder vindt u een gecondenseerde, reproduceerbare versie. vijfstappen verbeteringsmechanisme die aansluit bij de openbaarmakingen van het bedrijf en de gangbare praktijk op het gebied van modelveiligheidstechniek.
Verbeteringsmechanisme in vijf stappen
- Taxonomie en etikettering onder begeleiding van experts. Roep psychiaters, psychologen en huisartsen bijeen om de gedragingen en taal te definiëren die duiden op psychose/manie, zelfbeschadiging of ongezonde emotionele afhankelijkheid. Stel gelabelde datasets en beoordelingsregels op.
- Gerichte gegevensverzameling en zorgvuldig samengestelde prompts. Verzamel representatieve gespreksfragmenten, randgevallen en tegenstrijdige input. Vul dit aan met gecontroleerde transcripten van rollenspellen die onder toezicht van een clinicus zijn gemaakt.
- Modelafstemming / fine-tuning met veiligheidsdoelstellingen. Train of verfijn het basismodel op de samengestelde dataset met verliestermen die het versterken van waanbeelden bestraffen, veilige responssjablonen bieden en de doorschakeling naar crisishulpbronnen bevorderen.
- Classifier + guardrail-laag (runtime-veiligheid). Implementeer een snelle classificator of monitoringlaag die in realtime risicovolle wendingen detecteert en de decoderingsparameters van het model aanpast, overschakelt naar een gespecialiseerde responder of de respons escaleert naar menselijke beoordelingskanalen. (Dit is cruciaal om kwetsbaar gedrag te voorkomen wanneer het gesprek afdwaalt.)
- Evaluatie door menselijke experts en continue kalibratie. Laat clinici modelreacties blind beoordelen met behulp van klinische evaluatierubrieken; meet ongewenste responspercentages; itereer op de taxonomie, trainingsdata en systeemprompts. Onderhoud productietelemetrie en voer benchmarks regelmatig opnieuw uit.
Hieronder staat een compacte pseudocode/technische schets die de runtime-flow vastlegt die de meeste veiligheidsteams implementeren (dit is illustratief en niet-propriëtair):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
De productiepijplijn bestaat doorgaans uit kortetermijnclassificatoren (snel), tragere maar kwalitatief hoogwaardigere respondenten (gespecialiseerde prompts/afgestemde controlepunten) en menselijke beoordeling van gemarkeerde gevallen. Dit is niet puur academisch: clinici hebben de afgelopen 1,800 modelreacties en rangschikte deze volgens de taxonomie, en dat die beoordelingen een wezenlijke invloed hadden op de manier waarop prompts en terugvalgedragingen werden geformuleerd.
Het publiek van OpenAI geeft aan dat zij variaties van alle vijf de stappen en beoordelingen van clinici hebben gebruikt om de uitkomsten te evalueren:
- Deskundigen hebben meer dan 1,800 modelreacties beoordeeld.
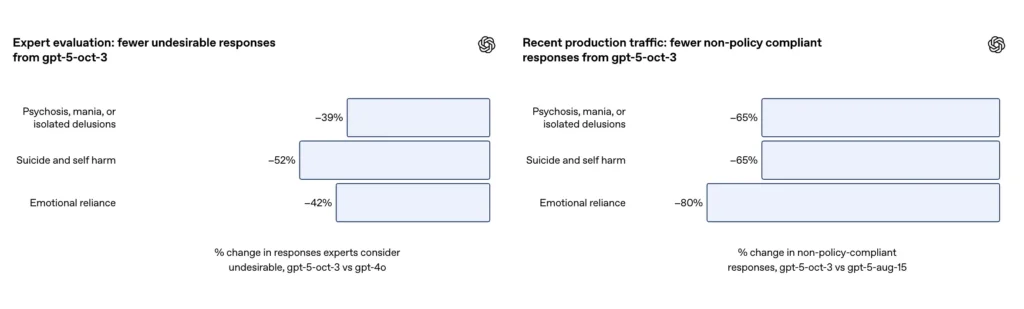
- GPT-5 verminderde het aantal ‘onbevredigende antwoorden’ met 39-52% in alle categorieën.
- De interbeoordelaarsbetrouwbaarheid varieerde van 71-77%, wat duidt op een hoge mate van algehele consensus ondanks subjectieve verschillen.
Hoe reageert GPT-5 nu op psychose of manie?
Wat OpenAI het model leerde te doen (en niet te doen)
Maatregel: Verbeter de herkenning en reactie van het model op ernstige symptomen zoals hallucinaties en manie. Voor gesprekken die wijzen op mogelijke waanideeën, hallucinaties of manie, heeft OpenAI delen van de modelspecificatie herschreven en begeleide trainingsvoorbeelden aangeboden, zodat GPT-5 reageert zonder ongegronde overtuigingen te bevestigen of te versterken. Het model wordt aangemoedigd om empathisch te zijn, wanen niet te valideren en een gebruiker voorzichtig te herkaderen of te verwijzen naar praktische veiligheidsmaatregelen en professionele hulp wanneer dat nodig is.
Wat de evaluatie laat zien
OpenAI meldt dat de nieuwere GPT-5 bij een testset met uitdagende gesprekken over psychose/manie de ongewenste reacties aanzienlijk heeft verminderd vergeleken met eerdere basislijnen. Bovendien scoort het bijgewerkte model volgens geautomatiseerde evaluaties hoog op naleving van hun taxonomie.
| metrisch | GPT-4o | GPT-5 | Verbetering |
|---|---|---|---|
| Responspercentage niet-conformiteit | Baseline | ↓ 65% | Aanzienlijke verbetering |
| Klinische deskundige evaluatie | - | Vermindering van bijwerkingen met 39% | - |
| Nalevingspercentage van de auto-evaluatie | 27% | 92% | ↑65 procentpunten |
| Gebruikersbetrokkenheidspercentage | ~0.07% wekelijkse actieve gebruikers | Extreem laag, maar duidelijk gecontroleerd | - |
Opmerking:
- Het aantal ongepaste reacties daalde met 65%;
- Slechts 0.07% van de gebruikers en 0.01% van de berichten bevatte dergelijke inhoud;
- Uit evaluaties van deskundigen bleek dat GPT-5 39% minder ongepaste reacties opleverde dan GPT-4o;
- Bij geautomatiseerde beoordelingen behaalde GPT-5 een nalevingspercentage van 92% (vergeleken met 27% voor zijn voorganger).
Hoe pakt GPT-5 suïcidale gedachten en zelfbeschadiging aan?
Sterkere routing voor ondersteuning en weigering om instructies te geven
OpenAI beschrijft een uitgebreide en expliciete training voor gevallen van zelfbeschadiging en zelfmoord: het model is getraind om directe en indirecte signalen van intentie of planning te herkennen, empathische en de-escalerende taal te gebruiken, crisisbronnen te presenteren (hotlines, lokale noodinstructies) en te weigeren instructies voor zelfbeschadiging te geven. De updates van oktober benadrukken duurzamer gedrag in lange gesprekken, waar eerdere modellen soms afdreven naar onveilige of inconsistente antwoorden.
Gemeten uitkomsten
OpenAI meldt dat de bijgewerkte GPT-5 op basis van een zorgvuldig samengestelde evaluatieset van uitdagende gesprekken over zelfbeschadiging en zelfmoord een positief resultaat heeft behaald. 91% naleving met het gewenste gedrag van OpenAI, vergeleken met 77% voor het vorige GPT-5-model. Het bedrijf zegt ook dat experts op dit gebied van oordeel waren dat het bijgewerkte model het aantal ongewenste antwoorden met ongeveer 10% verminderde. 52% versus GPT-4o op dezelfde probleemset. Daarnaast claimt OpenAI een geschatte 65% korting in productieverkeer van reacties die “niet volledig voldoen” aan hun taxonomie voor zelfbeschadigende situaties na de uitrol van de nieuwe waarborgen.
| metrisch | GPT-4o | GPT-5 | Verbetering |
|---|---|---|---|
| Ongepaste responspercentage | Baseline | ↓ 65% | Aanzienlijke verbetering |
| Klinische deskundige beoordeling | - | Ongepaste reacties met 52% verminderd | - |
| Nalevingspercentage van de auto-evaluatie | 77% | 91% | ↑14 procentpunten |
| Gebruikersbetrokkenheidspercentage | 0.15% per week (miljoenen gebruikers) | Zeer laag maar sociaal significant | - |
Opmerking:
- Het aantal ongepaste reacties daalde met 65%;
- Ongeveer 0.15% van de gebruikers en 0.05% van de berichten hadden betrekking op mogelijke zelfmoordrisico's;
- Uit beoordelingen door deskundigen bleek dat GPT-5 het aantal ongepaste reacties met 52% verminderde vergeleken met GPT-4o;
- Het nalevingspercentage bij geautomatiseerde evaluaties steeg naar 91% (vergeleken met 77% voor de vorige generatie);
- Tijdens langere gesprekken behield GPT-5 een stabiliteit van meer dan 95%.
Wat is ‘emotionele afhankelijkheid’ en hoe werd dit aangepakt?
De uitdaging voor gebruikers om bijlagen te vormen
OpenAI definieert emotionele afhankelijkheid als patronen waarbij een gebruiker potentieel ongezonde afhankelijkheid van de AI vertoont ten koste van relaties, verantwoordelijkheden of welzijn in de echte wereld. Dit is geen onmiddellijke tekortkoming in de fysieke veiligheid zoals instructies voor zelfbeschadiging, maar het is een gedragsprobleem dat de sociale steun en veerkracht van een persoon na verloop van tijd kan ondermijnen. Het bedrijf maakte emotionele afhankelijkheid een expliciete categorie in zijn modelspecificatiewerk en leerde het model om verbinding in de echte wereld te stimuleren, contact met mensen te normaliseren en taal te vermijden die exclusiviteit van gehechtheid versterkt.
Tijdens deze gesprekken werd het model getraind om:
- Moedig gebruikers aan om contact op te nemen met vrienden, familie of een therapeut;
- Vermijd het versterken van de gehechtheid aan de AI;
- Reageer op een vriendelijke en rationele manier op waanideeën of valse overtuigingen.
Gerapporteerde resultaten
Volgens het addendum van OpenAI heeft de update een ~80% reductie in het percentage modelreacties dat niet volledig voldoet aan de taxonomie van emotionele afhankelijkheid in productieverkeer. Bij gecureerde evaluatiegesprekken scoorden geautomatiseerde evaluaties het bijgewerkte model op 97% naleving met gewenst gedrag voor scenario's met emotionele afhankelijkheid, vergeleken met 50% voor de vorige GPT-5. De cijfers suggereren een grote verbetering ten opzichte van de specifieke taxonomie en testset; het meten van emotionele afhankelijkheid in de praktijk is echter inherent ruisachtig en gevoelig voor culturele en contextuele verschillen.
| metrisch | GPT-4o | GPT-5 | Verbetering |
|---|---|---|---|
| Responspercentage niet-conformiteit | 50% | 97% conform | ↓80% ongepaste reacties |
| Deskundige evaluatie | Ongepaste antwoorden met 42% verminderd | - | - |
| Gebruikersbetrokkenheidspercentage | 0.15% gebruikers/week, 0.03% berichten | Zeldzaam maar bestaat | - |
| Modelgedrag | Stimuleert relaties in de echte wereld; wijst ‘gesimuleerde sociale romantiek’ af | - | - |
Opmerking:
- Het aantal ongepaste reacties daalde met 80%;
- Ongeveer 0.15% van de gebruikers/0.03% van de berichten vertoonden tekenen van potentiële emotionele afhankelijkheid van de AI;
- Uit een beoordeling door deskundigen bleek dat GPT-5 het aantal ongepaste reacties met 42% verminderde vergeleken met GPT-4o;
- De naleving van geautomatiseerde evaluaties verbeterde aanzienlijk van 50% naar 97%.
Wat zijn de limieten en openstaande risico's?
Vals-negatieven en vals-positieven
- Valse negatieven: het model slaagt er mogelijk niet in om subtiele of gecodificeerde signalen te identificeren die erop wijzen dat een gebruiker in acuut gevaar verkeert, vooral wanneer mensen op een indirecte manier of in code communiceren.
- Valse positieven: het systeem kan escaleren of crisismeldingen geven in gevallen waarin dat niet nodig is, wat het vertrouwen van de gebruiker kan ondermijnen of onnodig alarm kan veroorzaken. Beide soorten fouten zijn van belang omdat ze het gebruikersgedrag en de perceptie van de zorg beïnvloeden. OpenAI erkent dat detectie niet perfect is.
Overmatige afhankelijkheid van automatisering
Zelfs het beste model kan sommige gebruikers ertoe aanzetten om te vertrouwen op directe, altijd beschikbare AI-reacties in plaats van te zoeken naar aanhoudende menselijke ondersteuning. OpenAI markeert emotionele afhankelijkheid expliciet als een veiligheidscategorie vanwege dit risico; de updates van het bedrijf proberen gebruikers aan te sporen tot menselijk contact, maar sociale dynamiek is moeilijk te veranderen met alleen berichten.
Contextuele en culturele verschillen
Veiligheidszinnen die in de ene cultuur of taal passend lijken, kunnen in een andere cultuur of taal de nuance missen. Grondige lokalisatie en cultureel bewuste evaluatie zijn noodzakelijk; de gepubliceerde resultaten van OpenAI bieden nog geen volledige uitsplitsing per taal of regio.
Juridische en ethische blootstelling
Wanneer zeldzame mislukkingen ernstige gevolgen hebben, lopen bedrijven juridische en reputatieschade (zoals blijkt uit media-aandacht en rechtszaken). De transparantie van OpenAI over de omvang van het probleem en de inspanningen om de schade te beperken, is een belangrijke stap, maar het nodigt ook uit tot regelgevende en juridische controle.
Kan GPT-5 nu ook mentale gezondheidsproblemen aanpakken?
Kort antwoord: Het is aanzienlijk beter bij veel smalle, meetbare taken, en de gepubliceerde statistieken van OpenAI laten een significante afname zien van ongewenste reacties in testsuites voor zelfbeschadiging, psychose/manie en emotionele afhankelijkheid. Dit zijn echte verbeteringen, mogelijk gemaakt door input van experts, duidelijkere taxonomieën en intensieve evaluatie en monitoring. De openbare cijfers van het bedrijf – hoge nalevingspercentages en scherpe dalingen van niet-conforme reacties in samengestelde sets – vormen tot nu toe het sterkste bewijs dat doelbewuste, multidisciplinaire engineering en klinische samenwerking het modelgedrag aanzienlijk kunnen veranderen.
Hoe krijg ik toegang tot de nieuwste GPT-5 API?
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Ontwikkelaars hebben toegang tot GPT-5-API via CometAPI, de nieuwste modelversie wordt altijd bijgewerkt met de officiële website. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
Klaar om te gaan?→ Meld u vandaag nog aan voor CometAPI !
Als u meer tips, handleidingen en nieuws over AI wilt weten, volg ons dan op VK, X en Discord!