Claude Haiku 4.5 is een doelgeoptimaliseerd taalmodel van kleinere klasse van Anthropic, uitgebracht medio oktober 2025. Het is gepositioneerd als een snel, voordelig alternatief binnen de Claude-reeks dat sterke capaciteiten behoudt voor taken zoals coderen, agent-orkestratie en interactieve “computergebruik”-workflows, terwijl het veel hogere doorvoer en lagere kost per eenheid voor bedrijfsimplementaties mogelijk maakt.
Belangrijkste functies
- Snelheid en kostenefficiëntie: Haiku 4.5 wordt beschreven als meer dan twee keer zo snel als Sonnet 4 en ongeveer een derde van de kosten van Sonnet 4 (en veel goedkoper dan Opus), wat het aantrekkelijk maakt voor grootschalig gebruik.
- Uitgebreid redeneren: Eerste Haiku-model met ondersteuning voor uitgebreid redeneren (samengevatte / verweven gedachten, configureerbare denkbudgetten) voor diepere meerstapsredenering met behoud van latentie.
- Tools en computergebruik: Volledige ondersteuning voor Claude-tools (bash, code-executie, teksteditor, webzoekopdrachten en automatisering van computergebruik). Ontworpen voor agentgerichte workflows en subagent-architecturen.
- Groot contextvenster: 200k tokens contextvenster (met 1M-contextopties beschikbaar op grotere modellen als bèta voor andere modelklassen).
Technische details
- Trainingsgegevens en afkapdatum: Haiku 4.5 is getraind op een propriëtaire mix van publieke en gelicentieerde data met een trainingsafkapdatum rond februari 2025.
- Uitgebreid redeneren (een hybride redeneermodus) wordt ondersteund zodat het model, wanneer gevraagd, latentie kan inruilen voor diepere redenering.
- Contextvenster bij release is 200,000 tokens, en het model is expliciet contextbewust (het houdt bij hoeveel van het venster is gebruikt).
- Prestaties/doorvoer: Vroege communityrapporten en tests van Anthropic melden zeer hoge OTPS (output tokens/sec) en anekdotische snelheden rond ~200+ tokens/sec in sommige interne/vroege tests — veel sneller dan veel vergelijkbare modellen uit het middensegment.
Benchmarkprestaties
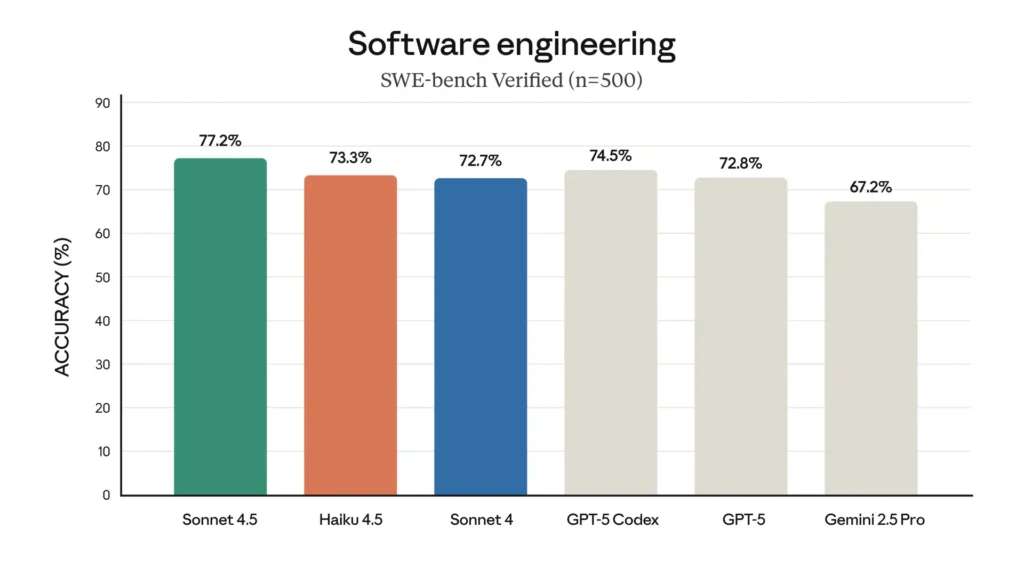
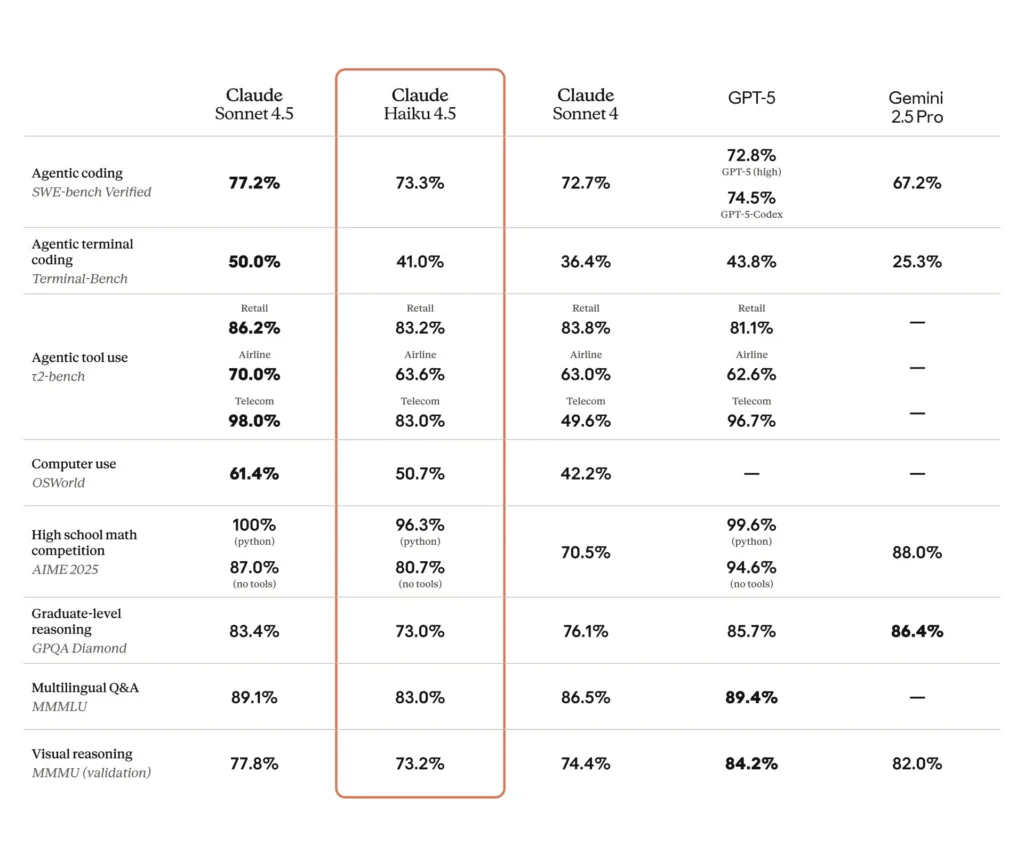
SWE-Bench (coderen): Haiku 4.5 behaalde ~73.3% op SWE-Bench Verified — een resultaat dat volgens Anthropic Haiku 4.5 tot de beste codeermodellen ter wereld in zijn klasse rekent.
Terminal-/command-line-/tooltests: Anthropic rapporteerde ~41% op Terminal-Bench (gericht op de command-line) en vergelijkbare resultaten als Sonnet 4 en verschillende concurrerende frontier-modellen uit het middensegment op veel toolgebruik-benchmarks.
Instructievolging & slidetekst: interne voorbeelden van Anthropic stellen dat Haiku 4.5 eerdere modellen overtrof op sommige instructievolgingstaken (bijv. slidetekstgeneratie: 65% vs 44% voor een eerder premium-model in hun benchmark).
Automatisering in de praktijk / agent-taken: evaluaties door derden en vroege gebruikers melden concurrerende succescijfers op geautomatiseerde UI/agent-taken (bijvoorbeeld OSWorld-achtige of agent-benchmarks die ≈50% succes rapporteren bij complexe automatisering in sommige tests), wat de bruikbaarheid voor grootschalige workflows aantoont, zij het met niet-triviale faalmodi.
Beperkingen en veiligheidsnotities
- Geen frontiermodel: Anthropic classificeert Haiku 4.5 expliciet als niet frontier-verhogend; het is geoptimaliseerd voor efficiëntie in plaats van het verleggen van de absolute state of the art. (Anthropic)
- Af en toe gedrag rond gevoelige onderwerpen: bij sommige wetenschappelijke/bio-veiligheidsgerelateerde prompts geeft Haiku 4.5 soms hoog-over informatie met kanttekeningen in plaats van strikte weigeringen; Anthropic markeert dit als een punt van voortdurende verbetering.
- Uitgebreid redeneren kan het gedrag veranderen (het vergroot soms de asymmetrie in antwoorden).
Aanbevolen gebruiksscenario’s
- Agentgericht coderen & multi-agent-orkestratie: snelle subagents, iteratieve code-refactoring, autotests en patchgeneratie. (Goede match.)
- Realtime, grootschalige klantworkflows: chatassistenten, interne automatisering waar kosten per verzoek belangrijk zijn. (Goede match.)
- Tool-ondersteunde workflows & computerbediening: automatiseren van GUI/CLI-taken, documentworkflows en toolchains waar lage latentie helpt. (Goede match.)
- Niet aanbevolen (zonder waarborgen): zelfstandige rollen die wetenschappelijk sequentieontwerp op frontier-niveau of biosecurity-taken met hoge zekerheid vereisen. (Wees voorzichtig.)