

Op 17 juni 2025 lanceerde de in Shanghai gevestigde AI-leider MiniMax (ook bekend als Xiyu Technology) officieel MiniMax-M1 (hierna "M1") – 's werelds eerste open, grootschalige model voor hybride-attention reasoning. Door een Mixture-of-Experts (MoE)-architectuur te combineren met een innovatief Lightning Attention-mechanisme, behaalt M1 toonaangevende prestaties in productiviteitsgerichte taken en kan het concurreren met toonaangevende closed-sourcesystemen, terwijl het tegelijkertijd een ongeëvenaarde kosteneffectiviteit behoudt. In dit uitgebreide artikel bespreken we wat M1 is, hoe het werkt, de belangrijkste kenmerken en praktische richtlijnen voor toegang tot en gebruik van het model.
Wat is MiniMax-M1?
MiniMax-M1 vormt de culminatie van MiniMaxAI's onderzoek naar schaalbare, efficiënte aandachtsmechanismen. Voortbouwend op de MiniMax-Text-01-basis integreert de M1-iteratie Lightning Attention met een MoE-framework om ongekende efficiëntie te bereiken tijdens zowel training als inferentie. Deze combinatie stelt het model in staat om hoge prestaties te behouden, zelfs bij het verwerken van extreem lange sequenties – een belangrijke vereiste voor taken met uitgebreide codebases, juridische documenten of wetenschappelijke literatuur.
Kernarchitectuur en parameterisatie
In de kern maakt de MiniMax-M1 gebruik van een hybride MoE-systeem dat tokens dynamisch routeert via een subset van expert-subnetwerken. Hoewel het model in totaal 456 miljard parameters omvat, worden er slechts 45.9 miljard per token geactiveerd, waardoor het resourcegebruik wordt geoptimaliseerd. Dit ontwerp is geïnspireerd op eerdere MoE-implementaties, maar verfijnt de routeringslogica om de communicatieoverhead tussen GPU's tijdens gedistribueerde inferentie te minimaliseren.
Bliksemsnelle aandacht en langdurige ondersteuning
Een bepalend kenmerk van de MiniMax-M1 is het Lightning Attention-mechanisme, dat de rekenlast van zelf-aandacht voor lange sequenties drastisch vermindert. Door aandachtsmatrices te benaderen met een combinatie van lokale en globale kernels, verlaagt het model FLOP's tot wel 75% ten opzichte van traditionele transformers bij de verwerking van 100 tokensequenties. Deze efficiëntie versnelt niet alleen de inferentie, maar opent ook de deur naar het verwerken van contextvensters tot wel een miljoen tokens zonder hoge hardwarevereisten.
Hoe bereikt de MiniMax-M1 rekenefficiëntie?
De efficiëntieverbeteringen van de MiniMax-M1 zijn te danken aan twee belangrijke innovaties: de hybride Mixture-of-Experts-architectuur en het nieuwe CISPO reinforcement learning-algoritme dat tijdens de training wordt gebruikt. Samen verminderen deze elementen zowel de trainingstijd als de inferentiekosten, wat snelle experimenten en implementatie mogelijk maakt.
Hybride mix van experts-routering
De MoE-component maakt gebruik van 32 expert-subnetwerken, die elk gespecialiseerd zijn in verschillende aspecten van redeneren of domeinspecifieke taken. Tijdens de inferentie selecteert een aangeleerd poortmechanisme dynamisch de meest relevante experts voor elk token en activeert alleen de subnetwerken die nodig zijn om de invoer te verwerken. Deze selectieve activering vermindert redundante berekeningen en de vraag naar geheugenbandbreedte, wat de MiniMax-M1 een aanzienlijk voordeel geeft in kostenefficiëntie ten opzichte van monolithische transformatormodellen.
CISPO: een nieuw reinforcement learning-algoritme
Om de trainingsefficiëntie verder te verbeteren, ontwikkelde MiniMaxAI CISPO (Clipped Importance Sampling with Partial Overrides), een RL-algoritme dat gewichtsupdates op tokenniveau vervangt door clipping op basis van importance-sampling. CISPO vermindert problemen met gewichtsexplosies die veel voorkomen in grootschalige RL-opstellingen, versnelt de convergentie en zorgt voor stabiele beleidsverbetering in diverse benchmarks. Hierdoor is de volledige RL-training van MiniMax-M1 op 512 H800 GPU's in slechts drie weken voltooid en kost ongeveer $ 534,700 – een fractie van de kosten die worden gerapporteerd voor vergelijkbare GPT-4-trainingsruns.
Wat zijn de prestatiebenchmarks van MiniMax-M1?
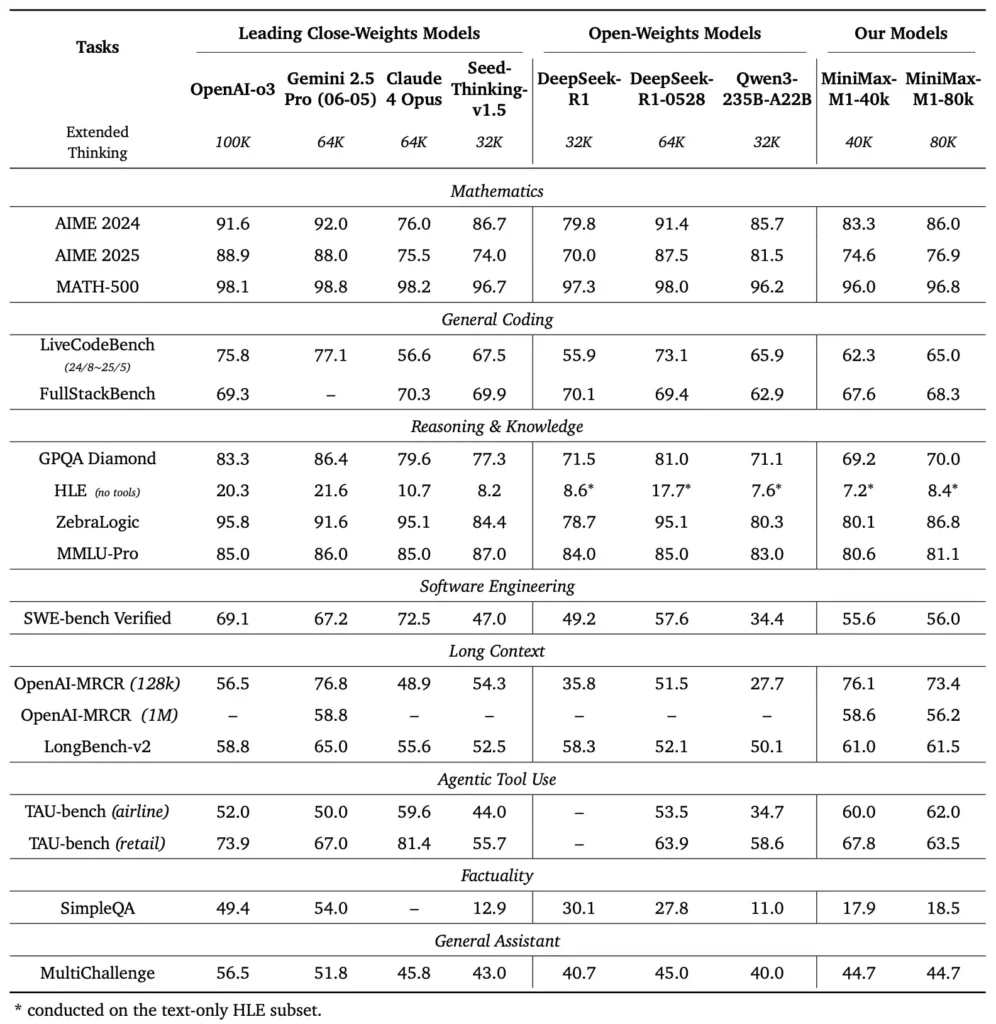
MiniMax-M1 blinkt uit in een groot aantal standaard- en domeinspecifieke benchmarks en toont zijn vaardigheden op het gebied van contextueel redeneren, wiskundige probleemoplossing en codegeneratie.
Lange-context redeneertaken
In uitgebreide tests voor documentbegrip verwerkt MiniMax-M1 contextvensters tot 1,000,000 tokens, waarmee het DeepSeek-R1 acht keer beter presteert qua maximale contextlengte en de rekenkracht voor reeksen van 100 tokens halveert. In benchmarks zoals de uitgebreide contextevaluatie van NarrativeQA behaalt het model state-of-the-art begripsscores, dankzij het vermogen van de bliksemsnelle aandacht om zowel lokale als globale afhankelijkheden efficiënt vast te leggen.
Software engineering en toolgebruik
MiniMax-M1 is specifiek getraind in sandbox-software engineeringomgevingen met behulp van grootschalige RL, waardoor het model code met opmerkelijke nauwkeurigheid kan genereren en debuggen. In codebenchmarks zoals HumanEval en MBPP behaalt het model slagingspercentages die vergelijkbaar zijn met of hoger zijn dan die van Qwen3-235B en DeepSeek-R1, met name in codebases met meerdere bestanden en taken die kruisverwijzingen naar lange codesegmenten vereisen. Bovendien tonen de eerste demonstraties van MiniMaxAI de integratiemogelijkheden van het model met ontwikkelaarstools aan, van het genereren van CI/CD-pipelines tot workflows voor automatische documentatie.
Hoe krijgen ontwikkelaars toegang tot MiniMax-M1?
Om brede acceptatie te bevorderen, heeft MiniMaxAI MiniMax-M1 gratis beschikbaar gesteld als een open-weight model. Ontwikkelaars hebben toegang tot vooraf getrainde checkpoints, modelgewichten en inferentiecode via de officiële GitHub-repository.
Open-weight release op GitHub
MiniMaxAI publiceerde de modelbestanden en bijbehorende scripts van MiniMax-M1 onder een open-sourcelicentie op GitHub. Geïnteresseerde gebruikers kunnen de repository klonen op https://github.com/MiniMax-AI/MiniMax-M1. Deze repository host checkpoints voor zowel de varianten met een budget van 40K als 80K tokens, evenals integratievoorbeelden voor gangbare ML-frameworks zoals PyTorch en TensorFlow.
API-eindpunten en cloudintegratie
Naast lokale implementatie werkt MiniMaxAI samen met grote cloudproviders om beheerde API-services aan te bieden. Via deze samenwerkingen kunnen ontwikkelaars MiniMax-M1 aanroepen via RESTful-eindpunten, met SDK's beschikbaar voor Python, JavaScript en Java. De API's bevatten configureerbare parameters voor contextlengte, deskundige routingdrempels en tokenbudgetten, waardoor gebruikers de prestaties kunnen afstemmen op hun use cases en tegelijkertijd het rekenvermogen in realtime kunnen monitoren.
Hoe integreer en gebruik je MiniMax-M1 in echte toepassingen?
Om de mogelijkheden van MiniMax-M1 optimaal te benutten, hebt u inzicht nodig in de API-patronen, best practices voor prompts met lange context en strategieën voor toolorkestratie.
Voorbeeld van basis-API-gebruik
Een typische API-aanroep omvat het versturen van een JSON-payload met de invoertekst en optionele configuratie-overschrijvingen. Bijvoorbeeld:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Het antwoord retourneert een gestructureerde JSON met gegenereerde tekst, statistieken over tokengebruik en routeringslogboeken, waardoor gedetailleerde monitoring van expertactivaties mogelijk is.
Gereedschapsgebruik en MiniMax Agent
Naast het kernmodel heeft MiniMaxAI MiniMax Agent geïntroduceerd, een bèta-agentframework dat externe tools – variërend van code-uitvoeringsomgevingen tot webscrapers – onder de motorkap kan aanroepen. Ontwikkelaars kunnen een agentsessie instantiëren die modelredeneringen koppelt aan het aanroepen van tools, bijvoorbeeld om realtime data op te halen, berekeningen uit te voeren of databases bij te werken. Dit agentparadigma vereenvoudigt end-to-end applicatieontwikkeling, waardoor MiniMax-M1 kan functioneren als orkestrator in complexe workflows.
Best practices en valkuilen
- Snelle engineering voor lange contexten: Verdeel de invoer in samenhangende segmenten, voeg samenvattingen in op logische intervallen en maak gebruik van strategieën van ‘eerst samenvatten, dan redeneren’ om de focus van het model te behouden.
- Compute versus prestatie-afwegingenExperimenteer met lagere drempels voor experts of beperkte denkbudgetten (bijvoorbeeld de 40K-variant) voor toepassingen die gevoelig zijn voor latentie.
- Monitoring en governance:Gebruik routeringslogboeken en tokenstatistieken om het gebruik van experts te controleren en naleving van kostenbegrotingen te garanderen, met name in productieomgevingen.
Door deze richtlijnen te volgen, kunnen ontwikkelaars de sterke punten van MiniMax-M1 (uitgebreide contextverwerking en efficiënte redenering) optimaal benutten en tegelijkertijd de risico's beperken die gepaard gaan met grootschalige implementaties van modellen.
Hoe gebruik je MiniMax-M1?
Nadat M1 is geïnstalleerd, kan het worden aangeroepen via eenvoudige Python-scripts of interactieve notebooks.
Hoe ziet een eenvoudig inferentiescript eruit?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
In dit voorbeeld wordt de variant met een budget van 40 k aangeroepen; er wordt overgeschakeld naar "MiniMax-AI/MiniMax-M1-80k" ontgrendelt het volledige 80 k redeneerbudget ().
Hoe ga je om met extreem lange contexten?
Voor inputs die de typische buffergroottes overschrijden, ondersteunt M1 streaming tokenisatie. Gebruik de stream=True vlag in de tokenizer om tokens in delen aan te bieden en gebruik te maken van checkpoint-restart inferentie om de prestaties over een reeks van een miljoen tokens te behouden.
Hoe kun je M1 verfijnen of aanpassen?
Hoewel de basiscontrolepunten voor de meeste taken voldoende zijn, kunnen onderzoekers RL-finetuning toepassen met behulp van de CISPO-code in de repository. Door aangepaste beloningsfuncties te leveren – variërend van codecorrectheid tot semantische betrouwbaarheid – kunnen professionals M1 aanpassen aan domeinspecifieke workflows.
Conclusie
MiniMax-M1 onderscheidt zich als een baanbrekend AI-model dat de grenzen verlegt van het begrijpen en redeneren van lange-context taal. Met zijn hybride MoE-architectuur, Lightning Attention-mechanisme en CISPO-ondersteunde trainingsprogramma levert het model hoge prestaties bij taken variërend van juridische analyse tot software engineering, terwijl de rekenkosten aanzienlijk worden verlaagd. Dankzij de open-weight release en cloud API-aanbiedingen is MiniMax-M1 toegankelijk voor een breed spectrum aan ontwikkelaars en organisaties die graag AI-applicaties van de volgende generatie willen bouwen. Terwijl de AI-community het potentieel van grootschalige modellen blijft verkennen, zullen de innovaties van MiniMax-M1 naar verwachting toekomstig onderzoek en productontwikkeling in de sector beïnvloeden.
Beginnen
CometAPI biedt een uniforme REST-interface die honderden AI-modellen, waaronder de ChatGPT-familie, samenvoegt onder één consistent eindpunt, met ingebouwd API-sleutelbeheer, gebruiksquota's en factureringsdashboards. Dit voorkomt het gebruik van meerdere leveranciers-URL's en inloggegevens.
Om te beginnen, verken de mogelijkheden van modellen in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt.
De nieuwste integratie MiniMax‑M1 API zal binnenkort verschijnen op CometAPI, dus blijf op de hoogte! Terwijl we de upload van het MiniMax‑M1-model afronden, kunt u onze andere modellen bekijken op de Modellenpagina of probeer ze in de AI-speeltuinHet nieuwste model van MiniMax in CometAPI is Minimax ABAB7-Preview-API en MiniMax Video-01 API ,verwijzen naar:
