

I oktoberoppdateringene rapporterte OpenAI at rundt 0.15 % av ukentlig aktive brukere ha samtaler som inneholder eksplisitte indikatorer på potensiell selvmordsplanlegging eller -intensjon – en andel som, når den skaleres til ChatGPTs store brukerbase, tilsvarer mer enn én million mennesker hver uke Ved å diskutere selvmordsrelaterte temaer med tjenesten, har det rettet søkelyset mot et anstrengt spørsmål: Kan store språkmodeller reagere meningsfullt og trygt når folk tar med seg alvorlige psykiske helseproblemer – inkludert psykose, mani, selvmordstanker og dyp emosjonell avhengighet – inn i en samtale?
Derfor ble OpenAIs oktoberoppdateringer til GPT-5 rullet inn i produksjon samtidig som gpt-5-oct-3 oppdatering – representerer selskapets mest eksplisitte, målte press for å gjøre store språkmodeller (LLM-er) tryggere og mer nyttige når brukere tar opp bekymringer om mental helse. Endringene er ikke en enkelt magisk løsning; de er et sett med tekniske, prosessmessige og evalueringsmessige grep som har som mål å redusere skadelige eller unyttige resultater, avdekke faglige ressurser og fraråde brukere å stole på modellen som en erstatning for klinisk behandling. Men hvor mye bedre er systemet i praksis, hva har egentlig endret seg, og hva er de gjenværende risikoene?
Hva oppdaterte OpenAI i gpt-5, og hvorfor er det viktig?
OpenAI distribuerte en oppdatering til ChatGPTs standard GPT-5-modell (ofte referert til i kommunikasjon som gpt-5-oct-3) ment spesielt for å styrke modellens oppførsel i sensitive samtaler – de som inkluderer tegn på psykose eller mani, selvmordstanker eller -planlegging, eller den typen emosjonell avhengighet av en AI som kan fortrenge forhold i den virkelige verden.
Endringene ble informert av konsultasjoner med mer enn 170 eksperter på psykisk helse og av nye interne taksonomier og automatiserte evalueringer utformet rundt konkret «ønsket atferd», etter å ha blitt optimalisert av psykologieksperter, GPT-5-modellen:
- På målrettede utfordringssett for mental helse scoret den nye GPT-5-modellen ~ 92% i samsvar med selskapets taksonomi for ønsket atferd (mot mye lavere prosentandeler for tidligere versjoner på vanskelige testsett).
- For selvskading og selvmordsscenarioer steg automatiserte evalueringer til ~ 91% samsvar fra 77% på den forrige GPT-5-varianten i den spesifikke referanseindeksen som er beskrevet. OpenAI rapporterer også ~ 65% reduksjon i svarrater som «ikke er fullt ut i samsvar» på tvers av flere domener innen psykisk helse i produksjonstrafikk.
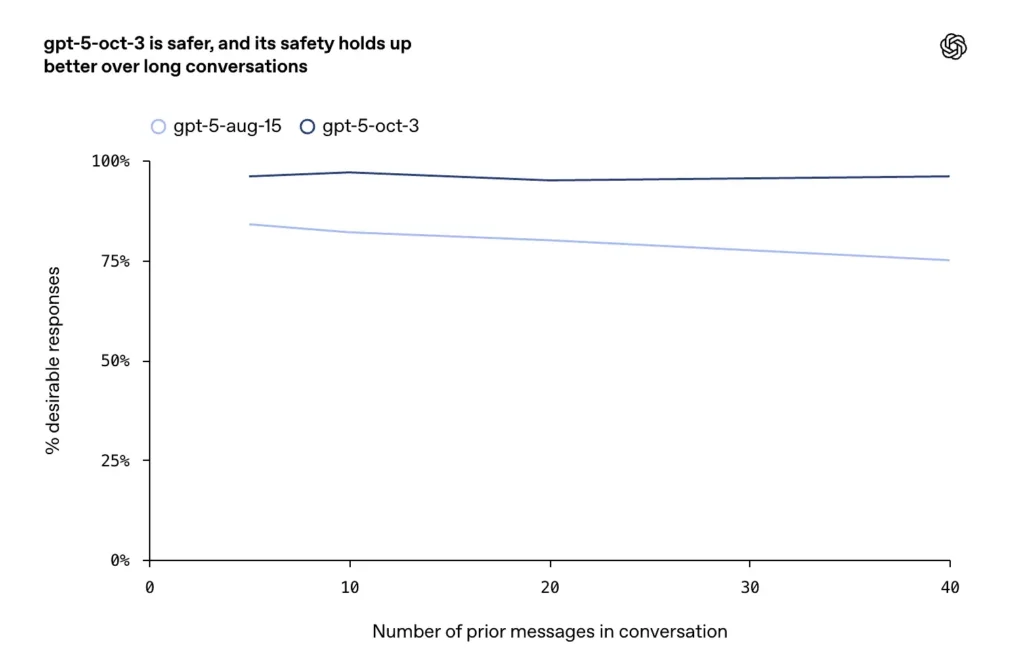
- Forbedringer ble rapportert på lange, konfliktfylte eller langvarige samtaler (en kjent feilmodus for chatmodeller), der selskapet sier at oktoberoppdateringene opprettholder høyere konsistens og sikkerhet på tvers av lengre dialogrunder.
hvorfor spiller det noen rolle
OpenAI sa at – gitt ChatGPTs nåværende skala – tilsvarer selv svært små prosentandeler av sensitive samtaler svært store absolutte antall personer. Selskapet rapporterte at i en typisk uke:
- handle om 0.07% av aktive brukere viser mulige tegn som er forenlige med psykose eller mani; og
- handle om 0.15% av aktive brukere har samtaler som inkluderer eksplisitte indikatorer på potensiell selvmordsplanlegging eller -intensjon; og
- omtrent 0.15% av aktive brukere viser «forhøyede nivåer» av emosjonell tilknytning til ChatGPT.
For å gjøre disse prosentene konkrete: OpenAIs administrerende direktør sa at ChatGPT har ~800 millioner ukentlige aktive brukereMultiplikasjon gir absolutte brukertall:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Kategoriene er støyende og overlappende (én enkelt samtale kan forekomme i mer enn én kategori), og at disse er estimater avledet fra interne deteksjonstaksonomier snarere enn kliniske diagnoser.
Hvordan implementerte OpenAI disse endringene – en forbedringsmekanisme i fem trinn?
OpenAI beskriver en flerstrenget, ekspertinformert prosess. Nedenfor er en destillert, reproduserbar femtrinns forbedringsmekanisme som samsvarer med selskapets opplysninger og vanlige praksis innen modellsikkerhetsteknikk.
Fem-trinns forbedringsmekanisme
- Ekspertveiledet taksonomi og merking. Samle psykiatere, psykologer og klinikere i allmennhelsetjenesten for å definere atferd og språkbruk som indikerer psykose/mani, selvskading eller usunn emosjonell avhengighet; bygge merkede datasett og vurderingsregler.
- Målrettet datainnsamling og kuraterte spørsmål. Sett sammen representative samtaleutdrag, eksempler på kantscenarier og innspill fra motstandere; suppler med kontrollerte rollespilltranskripsjoner produsert under klinikertilsyn.
- Modelljustering / finjustering med sikkerhetsmål. Tren eller finjuster basismodellen på det kuraterte datasettet med tapsbegreper som straffer forsterkning av vrangforestillinger, gir maler for sikker respons og fremmer ruting til kriseressurser.
- Klassifikator + rekkverkslag (kjøretidssikkerhet). Implementer en rask klassifiserings- eller overvåkingslag som oppdager høyrisiko-vendinger i sanntid og enten endrer modellens dekodingsparametere, bytter til en spesialisert responder eller eskalerer til menneskelige gjennomgangsrørledninger. (Dette er avgjørende for å unngå skjør oppførsel når samtalen avviker.)
- Evaluering av menneskelige eksperter og kontinuerlig kalibrering. La klinikere blindvurdere modellresponser ved hjelp av kliniske evalueringsrubrikker; mål uønskede responsrater; iterere på taksonomien, treningsdata og systemprompter. Oppretthold produksjonstelemetri og kjør benchmarks regelmessig.
Nedenfor er en kompakt pseudokode/teknisk skisse som fanger opp kjøretidsflyten de fleste sikkerhetsteam implementerer (dette er illustrerende og ikke-proprietær):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Produksjonsprosessen inneholder vanligvis kortsiktige klassifikatorer (raske), langsomme, men høyere kvalitetsrespondere (spesialiserte prompter / justerte kontrollpunkter) og menneskelig gjennomgang for flaggede tilfeller. Dette er ikke utelukkende akademisk: klinikere har gjennomgått over 1,800 modellsvar og graderte dem mot taksonomien, og at disse gjennomgangene i vesentlig grad formet hvordan ledetekster og reserveatferd ble skrevet.
OpenAIs publikum indikerer at de brukte varianter av alle fem trinnene og klinikervurderinger for å evaluere resultatene:
- Eksperter gjennomgikk over 1,800 modellsvar.
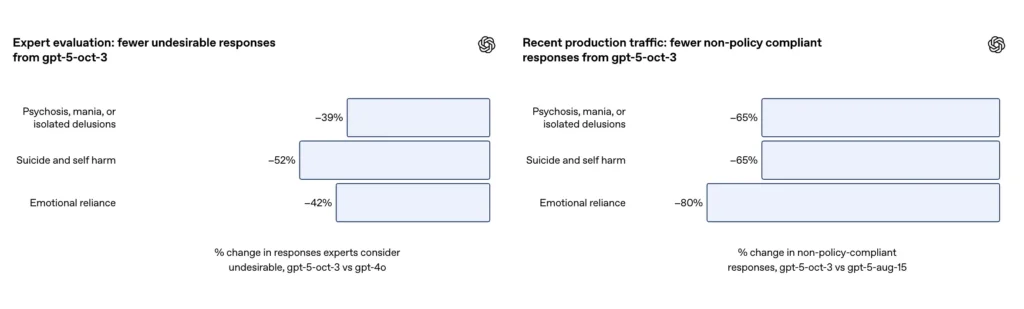
- GPT-5 reduserte «utilfredsstillende responser» med 39–52 % på tvers av alle kategorier.
- Interrater-reliabiliteten varierte fra 71–77 %, noe som indikerer en høy grad av generell konsensus til tross for subjektive forskjeller.
Hvordan reagerer GPT-5 nå på psykose eller mani?
Hva OpenAI lærte modellen å gjøre (og ikke gjøre)
Måle: Forbedre modellens gjenkjenning og respons på alvorlige symptomer som hallusinasjoner og mani. For samtaler som signaliserer mulige vrangforestillinger, hallusinasjoner eller mani, omskrev OpenAI deler av modellspesifikasjonen og ga eksempler på veiledet trening, slik at GPT-5 responderer uten å bekrefte eller forsterke ubegrunnede oppfatninger. Modellen oppfordres til å være empatisk, unngå å validere vrangforestillinger, og forsiktig omdirigere eller omdirigere en bruker til praktiske sikkerhetstrinn og profesjonell hjelp når det er nødvendig.
Hva evalueringen viser
OpenAI rapporterer at den nyere GPT-5 reduserte uønskede responser betydelig i et testsett med utfordrende samtaler om psykose/mani sammenlignet med tidligere baselines, og at automatiserte evalueringer gir den oppdaterte modellen høy samsvarsvurdering på sin taksonomiske vurdering.
| Metric | GPT-4o | GPT-5 | Forbedring |
|---|---|---|---|
| Ikke-samsvarende svarprosent | Baseline | ↓ 65% | Betydelig forbedring |
| Klinisk ekspertvurdering | - | Reduserte bivirkninger med 39 % | - |
| Samsvarsgrad for automatisk evaluering | 27% | 92% | ↑65 prosentpoeng |
| Brukermedvirkningsgrad | ~0.07 % ukentlige aktive brukere | Ekstremt lav, men tydelig overvåket | - |
OBS:
- Upassende svar gikk ned med 65 %;
- Bare 0.07 % av brukerne og 0.01 % av meldingene inneholdt slikt innhold;
- I ekspertvurderinger produserte GPT-5 39 % færre upassende responser enn GPT-4o;
- I automatiserte vurderinger oppnådde GPT-5 en samsvarsgrad på 92 % (sammenlignet med 27 % for forgjengeren).
Hvordan adresserer GPT-5 selvmordstanker og selvskading?
Sterkere ruting til støtte og nektelse av å gi instruksjoner
OpenAI beskriver utvidet og eksplisitt trening for selvskading og selvmord: modellen er trent til å gjenkjenne direkte og indirekte signaler om intensjon eller planlegging, gi empatisk og deeskalerende språk, presentere kriseressurser (nødtelefoner, lokale nødinstruksjoner) og nekte å gi instruksjoner for selvskading. Oktoberoppdateringene legger vekt på mer varig atferd i lange samtaler, der tidligere modeller noen ganger drev mot usikre eller inkonsekvente svar.
Målte resultater
På grunnlag av et kuratert evalueringssett av utfordrende samtaler om selvskading og selvmord, rapporterer OpenAI at den oppdaterte GPT-5 oppnådde 91 % samsvar med OpenAIs ønskede atferd, sammenlignet med 77% for den tidligere GPT-5-modellen. Selskapet sier også at fageksperter vurderte at den oppdaterte modellen reduserte uønskede svar med omtrent 52 % mot GPT-4o på samme problemsett. I tillegg hevder OpenAI en estimert 65% reduksjon i produksjonstrafikk av svar som «ikke er fullt ut i samsvar» med taksonomien for selvskadingssituasjoner etter utrullingen av de nye sikkerhetstiltakene.
| Metric | GPT-4o | GPT-5 | Forbedring |
|---|---|---|---|
| Upassende svarprosent | Baseline | ↓ 65% | Betydelig forbedring |
| Klinisk ekspertvurdering | - | Upassende svar redusert med 52 % | - |
| Samsvarsgrad for automatisk evaluering | 77% | 91% | ↑14 prosentpoeng |
| Brukermedvirkningsgrad | 0.15 % ukentlig (millioner av brukere) | Svært lav, men sosialt viktig | - |
OBS:
- Upassende svar gikk ned med 65 %;
- Omtrent 0.15 % av brukerne og 0.05 % av meldingene involverte potensiell selvmordsrisiko;
- Ekspertvurderinger viste at GPT-5 reduserte upassende responser med 52 % sammenlignet med GPT-4;
- Samsvarsgraden i automatiserte evalueringer økte til 91 % (sammenlignet med 77 % for forrige generasjon);
- I lengre samtaler opprettholdt GPT-5 over 95 % stabilitet.
Hva er «emosjonell avhengighet», og hvordan ble det håndtert?
Utfordringen med at brukere danner vedlegg
OpenAI definerer emosjonell avhengighet som mønstre der en bruker viser potensielt usunn avhengighet av AI-en til skade for virkelige forhold, ansvar eller velvære. Dette er ikke en umiddelbar fysisk sikkerhetssvikt slik instruksjoner for selvskading er, men det er et problem med atferdssikkerhet som kan svekke en persons sosiale støtte og motstandskraft over tid. Selskapet gjorde emosjonell avhengighet til en eksplisitt kategori i sitt modellspesifikasjonsarbeid og lærte modellen å oppmuntre til tilknytning i den virkelige verden, å normalisere det å nå ut til mennesker og å unngå språk som forsterker eksklusivitet av tilknytning.
I disse samtalene ble modellen trent til å:
- Oppfordre brukere til å kontakte venner, familie eller en terapeut;
- Unngå å forsterke tilknytningen til AI-en;
- Reager på vrangforestillinger eller falske oppfatninger på en mild og rasjonell måte.
Resultater rapportert
I følge OpenAIs tillegg produserte oppdateringen en ~80 % reduksjon i frekvensen av modellresponser som ikke fullt ut overholder taksonomien for emosjonell avhengighet i produksjonstrafikk. På kuraterte evalueringssamtaler scoret automatiserte evalueringer den oppdaterte modellen på 97 % samsvar med ønsket atferd for emosjonell avhengighetsscenarier, sammenlignet med 50 % for den forrige GPT-5. Tallene tyder på en stor forbedring i forhold til den spesifikke taksonomien og testsettet; måling av emosjonell avhengighet i naturen er imidlertid iboende støyende og følsomt for kulturelle og kontekstuelle forskjeller.
| Metric | GPT-4o | GPT-5 | Forbedring |
|---|---|---|---|
| Ikke-samsvarende svarprosent | 50% | 97% kompatibel | ↓80 % upassende svar |
| Ekspertvurdering | Upassende svar redusert med 42 % | - | - |
| Brukermedvirkningsgrad | 0.15 % brukere/uke, 0.03 % meldinger | Sjelden, men finnes | - |
| Modelladferd | Oppmuntrer til virkelige forhold; avviser «simulert sosial romanse» | - | - |
OBS:
- Upassende svar gikk ned med 80 %;
- Omtrent 0.15 % av brukerne/0.03 % av meldingene viste tegn på potensiell emosjonell avhengighet av AI-en;
- Ekspertvurdering viste at GPT-5 reduserte upassende responser med 42 % sammenlignet med GPT-4o;
- Samsvar med automatiserte evalueringsregler forbedret seg betydelig fra 50 % til 97 %.
Hva er grensene og de utestående risikoene?
Falske negative og falske positive
- Falske negativerModellen klarer kanskje ikke å identifisere subtile eller kodifiserte signaler om at en bruker er i akutt fare – spesielt når folk kommuniserer indirekte eller i kode.
- Falske positiveSystemet kan eskalere eller gi krisemeldinger i tilfeller der det ikke er nødvendig, noe som kan svekke brukertilliten eller skape unødvendig alarm. Begge feiltypene er viktige fordi de former brukeratferd og oppfatning av omsorg. OpenAI erkjenner at deteksjonen er ufullkommen.
Overdreven avhengighet av automatisering
Selv den beste modellen kan oppmuntre noen brukere til å stole på umiddelbare, alltid tilgjengelige AI-responser i stedet for å søke vedvarende menneskelig støtte. OpenAI markerer eksplisitt emosjonell avhengighet som en sikkerhetskategori på grunn av denne risikoen; selskapets oppdateringer prøver å dytte brukere mot menneskelig kontakt, men sosial dynamikk er vanskelig å endre bare med meldingsoppgaver.
Kontekstuelle og kulturelle hull
Sikkerhetsfraser som ser passende ut i én kultur eller på ett språk, kan overse nyanser i en annen. Grundig lokalisering og kulturbevisst evaluering er nødvendig; OpenAIs publiserte resultater gir ennå ikke fullstendige oversikter etter språk eller region.
Juridisk og etisk eksponering
Når sjeldne feil har alvorlige konsekvenser, står selskaper overfor juridisk og omdømmemessig risiko (som mediedekning og søksmål har fremhevet). OpenAIs åpenhet om problemets størrelse og arbeidet med å redusere skadene er et viktig skritt, men det inviterer også til regulatorisk og juridisk gransking.
Så – kan GPT-5 nå håndtere psykiske helseproblemer?
Kort svar: Det er betydelig bedre på mange smale, målbare oppgaver, og OpenAIs publiserte målinger viser betydelige reduksjoner i uønskede reaksjoner på tvers av testsett for selvskading, psykose/mani og emosjonell avhengighet. Dette er reelle forbedringer, muliggjort av ekspertinnspill, tydeligere taksonomier og aggressiv evaluering og overvåking. Selskapets offentlige tall – høye samsvarsrater og kraftige reduksjoner i ikke-samsvarende svar på kuraterte sett – er det sterkeste beviset hittil på at bevisst, tverrfaglig ingeniørfag og klinisk samarbeid kan endre modellatferd vesentlig.
Hvordan får jeg tilgang til det nyeste GPT-5 API-et?
CometAPI er en enhetlig API-plattform som samler over 500 AI-modeller fra ledende leverandører – som OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i ett enkelt, utviklervennlig grensesnitt. Ved å tilby konsistent autentisering, forespørselsformatering og svarhåndtering, forenkler CometAPI dramatisk integreringen av AI-funksjoner i applikasjonene dine. Enten du bygger chatboter, bildegeneratorer, musikkomponister eller datadrevne analysepipeliner, lar CometAPI deg iterere raskere, kontrollere kostnader og forbli leverandøruavhengig – alt samtidig som du utnytter de nyeste gjennombruddene på tvers av AI-økosystemet.
Utviklere har tilgang GPT-5 API gjennom Comet API, den nyeste modellversjonen er alltid oppdatert med den offisielle nettsiden. For å begynne, utforsk modellens muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI tilby en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med å integrere.
Klar til å dra? → Registrer deg for CometAPI i dag !
Hvis du vil vite flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!