

- juni 2025 lanserte den Shanghai-baserte AI-lederen MiniMax (også kjent som Xiyu Technology) offisielt MiniMax-M1 (heretter kalt «M1») – verdens første åpne, storskala hybrid-oppmerksomhetsmodell. Ved å kombinere en blanding av eksperter (MoE)-arkitektur med en innovativ Lightning Attention-mekanisme, oppnår M1 bransjeledende ytelse i produktivitetsorienterte oppgaver, og konkurrerer med topp lukkede systemer samtidig som den opprettholder enestående kostnadseffektivitet. I denne dyptgående artikkelen utforsker vi hva M1 er, hvordan det fungerer, dets definerende funksjoner og praktisk veiledning om tilgang til og bruk av modellen.
Hva er MiniMax-M1?
MiniMax-M1 representerer kulminasjonen av MiniMaxAIs forskning på skalerbare, effektive oppmerksomhetsmekanismer. M01-iterasjonen bygger på MiniMax-Text-1-fundamentet og integrerer lynoppmerksomhet med et MoE-rammeverk for å oppnå enestående effektivitet under både trening og inferens. Denne kombinasjonen gjør det mulig for modellen å opprettholde høy ytelse selv når den behandler ekstremt lange sekvenser – et nøkkelkrav for oppgaver som involverer omfattende kodebaser, juridiske dokumenter eller vitenskapelig litteratur.
Kjernearkitektur og parameterisering
I kjernen bruker MiniMax-M1 et hybrid MoE-system som dynamisk ruter tokener gjennom et delsett av ekspertnettverk. Selv om modellen omfatter totalt 456 milliarder parametere, aktiveres bare 45.9 milliarder for hvert token, noe som optimaliserer ressursbruken. Denne designen henter inspirasjon fra tidligere MoE-implementeringer, men forbedrer rutingslogikken for å minimere kommunikasjonsoverhead mellom GPU-er under distribuert inferens.
Lynrask oppmerksomhet og støtte for lang kontekst
Et definerende trekk ved MiniMax-M1 er dens lynraske oppmerksomhetsmekanisme, som drastisk reduserer den beregningsmessige byrden av selvoppmerksomhet for lange sekvenser. Ved å tilnærme oppmerksomhetsmatriser gjennom en kombinasjon av lokale og globale kjerner, kutter modellen FLOP-er med opptil 75 % sammenlignet med tradisjonelle transformatorer når den behandler 100 XNUMX tokensekvenser. Denne effektiviteten akselererer ikke bare inferens, men åpner også døren for å håndtere kontekstvinduer på opptil én million tokens uten uoverkommelige maskinvarekrav.
Hvordan oppnår MiniMax-M1 databehandlingseffektivitet?
MiniMax-M1s effektivitetsgevinster stammer fra to primære innovasjoner: den hybride Mixture-of-Experts-arkitekturen og den nye CISPO-forsterkningslæringsalgoritmen som brukes under trening. Sammen reduserer disse elementene både treningstid og inferenskostnader, noe som muliggjør rask eksperimentering og utrulling.
Hybrid blanding av eksperter-ruting
MoE-komponenten benytter 32 ekspert-undernettverk, som hvert spesialiserer seg på forskjellige aspekter ved resonnement eller domenespesifikke oppgaver. Under inferens velger en lært portmekanisme dynamisk de mest relevante ekspertene for hvert token, og aktiverer kun de undernettverkene som trengs for å behandle inputen. Denne selektive aktiveringen reduserer redundante beregninger og reduserer kravene til minnebåndbredde, noe som gir MiniMax-M1 en betydelig fordel i kostnadseffektivitet i forhold til monolittiske transformatormodeller.
CISPO: En ny algoritme for forsterkning av læring
For å ytterligere styrke treningseffektiviteten utviklet MiniMaxAI CISPO (Clipped Importance Sampling with Partial Overrides), en RL-algoritme som erstatter vektoppdateringer på tokennivå med klipping basert på viktighetssampling. CISPO reduserer problemer med vekteksplosjon som er vanlige i store RL-oppsett, akselererer konvergens og sikrer stabil policyforbedring på tvers av ulike benchmarks. Som et resultat fullføres MiniMax-M1s fulle RL-trening på 512 H800 GPU-er på bare tre uker, og koster omtrent $534,700 4 – en brøkdel av kostnaden som er rapportert for sammenlignbare GPT-XNUMX-treningskjøringer.
Hva er ytelsesstandardene til MiniMax-M1?
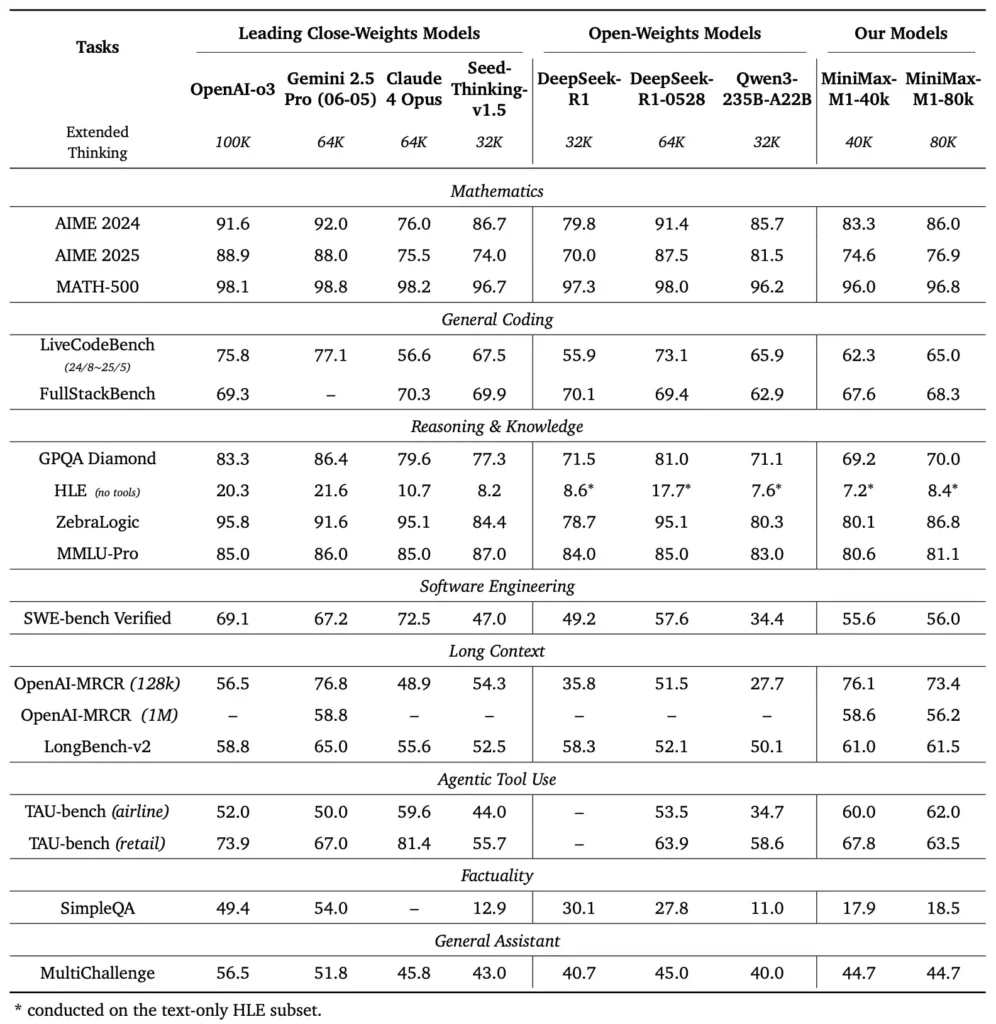
MiniMax-M1 utmerker seg på tvers av en rekke standard- og domenespesifikke benchmarks, og demonstrerer sin dyktighet i håndtering av langkontekstresonnement, matematisk problemløsning og kodegenerering.
Oppgaver med lang kontekstbasert resonnering
I omfattende dokumentforståelsestester behandler MiniMax-M1 kontekstvinduer på opptil 1,000,000 1 100 tokens, og overgår dermed DeepSeek-RXNUMX med en faktor på åtte i maksimal kontekstlengde og halverer beregningskravene for sekvenser på XNUMX XNUMX tokens. På benchmarks som den utvidede kontekstevalueringen NarrativeQA oppnår modellen toppmoderne forståelsespoeng, noe som tilskrives dens lynraske oppmerksomhetsevne til å fange opp både lokale og globale avhengigheter effektivt.
Programvareutvikling og verktøybruk
MiniMax-M1 ble spesifikt trent i sandkassebaserte programvareutviklingsmiljøer ved bruk av storskala RL, noe som gjorde det mulig å generere og feilsøke kode med bemerkelsesverdig nøyaktighet. I kodebenchmarks som HumanEval og MBPP oppnår modellen beståttrater som er sammenlignbare med eller overgår Qwen3-235B og DeepSeek-R1, spesielt i kodebaser med flere filer og oppgaver som krever kryssreferanser til lange kodesegmenter. Videre viser MiniMaxAIs tidlige demonstrasjoner modellens evne til å integreres med utviklerverktøy, fra å generere CI/CD-pipelines til automatiske dokumentasjonsarbeidsflyter.
Hvordan kan utviklere få tilgang til MiniMax-M1?
For å fremme bred adopsjon har MiniMaxAI gjort MiniMax-M1 fritt tilgjengelig som en åpen vektmodell. Utviklere kan få tilgang til forhåndstrente kontrollpunkter, modellvekter og inferenskode via det offisielle GitHub-depotet.
Åpen utgivelse på GitHub
MiniMaxAI publiserte MiniMax-M1s modellfiler og tilhørende skript under en permissiv åpen kildekode-lisens på GitHub. Interesserte brukere kan klone depotet på https://github.com/MiniMax-AI/MiniMax-M1, som er vert for sjekkpunkter for både 40K- og 80K-tokenbudsjettvariantene, samt integrasjonseksempler for vanlige ML-rammeverk som PyTorch og TensorFlow.
API-endepunkter og skyintegrasjon
Utover lokal distribusjon har MiniMaxAI inngått samarbeid med store skyleverandører for å tilby administrerte API-tjenester. Gjennom disse partnerskapene kan utviklere kalle MiniMax-M1 via RESTful-endepunkter, med SDK-er tilgjengelig for Python, JavaScript og Java. API-ene inkluderer konfigurerbare parametere for kontekstlengde, ekspertrutingsterskler og tokenbudsjetter, slik at brukerne kan skreddersy ytelsen til sine brukstilfeller samtidig som de overvåker beregningsforbruket i sanntid.
Hvordan integrere og bruke MiniMax-M1 i virkelige applikasjoner?
Å utnytte MiniMax-M1s funksjoner krever forståelse av API-mønstrene, beste praksis for lange kontekstforespørsler og strategier for verktøyorkestrering.
Eksempel på grunnleggende API-bruk
Et typisk API-kall innebærer å sende en JSON-nyttelast som inneholder inndatateksten og valgfrie konfigurasjonsoverstyringer. For eksempel:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Svaret returnerer en strukturert JSON med generert tekst, statistikk for tokenbruk og rutingslogger, noe som muliggjør finjustert overvåking av ekspertaktiveringer.
Verktøybruk og MiniMax Agent
Ved siden av kjernemodellen har MiniMaxAI introdusert MiniMax Agent, et beta-agentrammeverk som kan kalle eksterne verktøy – alt fra kodekjøringsmiljøer til webskrapere – under panseret. Utviklere kan instansiere en agentøkt som kjeder modellresonnement med verktøyanrop, for eksempel for å hente sanntidsdata, utføre beregninger eller oppdatere databaser. Dette agentparadigmet forenkler ende-til-ende-applikasjonsutvikling, slik at MiniMax-M1 kan fungere som orkestrator i komplekse arbeidsflyter.
Beste praksis og fallgruver
- Rask konstruksjon for lange konteksterDel opp innspill i sammenhengende segmenter, legg inn sammendrag med logiske intervaller, og bruk strategier for å «oppsummer og resonner» for å opprettholde modellfokus.
- Avveininger mellom beregning og ytelseEksperimenter med lavere ekspertterskler eller reduserte tenkebudsjetter (f.eks. 40K-varianten) for latensfølsomme applikasjoner.
- Overvåking og styringBruk rutingslogger og tokenstatistikk for å revidere ekspertutnyttelsen og sikre samsvar med kostnadsbudsjetter, spesielt i produksjonsmiljøer.
Ved å følge disse retningslinjene kan utviklere utnytte MiniMax-M1s styrker – omfattende konteksthåndtering og effektiv resonnering – samtidig som de reduserer risikoen forbundet med storskala modelldistribusjoner.
Hvordan bruker du MiniMax-M1?
Når M1 er installert, kan den kalles via enkle Python-skript eller interaktive notatbøker.
Hvordan ser et grunnleggende inferensskript ut?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Dette eksemplet aktiverer varianten med et budsjett på 40 XNUMX; bytter til "MiniMax-AI/MiniMax-M1-80k" låser opp hele resonneringsbudsjettet på 80 6 ().
Hvordan håndterer du ultralange kontekster?
For innganger som overstiger typiske bufferstørrelser, støtter M1 strømmetokenisering. Bruk stream=True flagg i tokenizeren for å mate tokener i deler, og utnytt slutning for omstart av kontrollpunkt for å opprettholde ytelse over sekvenser på millioner av tokener.
Hvordan kan du finjustere eller tilpasse M1?
Selv om basissjekkpunktene er tilstrekkelige for de fleste oppgaver, kan forskere bruke finjustering av RL ved hjelp av CISPO-koden som er inkludert i repositoriet. Ved å tilby tilpassede belønningsfunksjoner – alt fra kodekorrekthet til semantisk gjengivelse – kan utøvere tilpasse M1 til domenespesifikke arbeidsflyter.
Konklusjon
MiniMax-M1 skiller seg ut som en banebrytende AI-modell som flytter grensene for forståelse og resonnering av språk i lang kontekst. Med sin hybride MoE-arkitektur, lynraske oppmerksomhetsmekanisme og CISPO-støttede opplæringsprogram leverer modellen høy ytelse på oppgaver som spenner fra juridisk analyse til programvareutvikling, samtidig som den reduserer beregningskostnadene dramatisk. Takket være den åpne versjonen og skybaserte API-tilbudene er MiniMax-M1 tilgjengelig for et bredt spekter av utviklere og organisasjoner som er ivrige etter å bygge neste generasjons AI-drevne applikasjoner. Etter hvert som AI-fellesskapet fortsetter å utforske potensialet til modeller i stor kontekst, er MiniMax-M1s innovasjoner klare til å påvirke fremtidig forskning og produktutvikling i hele bransjen.
Komme i gang
CometAPI tilbyr et enhetlig REST-grensesnitt som samler hundrevis av AI-modeller – inkludert ChatGPT-familien – under et konsistent endepunkt, med innebygd API-nøkkeladministrasjon, brukskvoter og faktureringsdashboards. I stedet for å sjonglere flere leverandør-URL-er og legitimasjonsinformasjon.
For å begynne, utforsk modellenes muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen.
Den nyeste integrasjonen av MiniMax-M1 API vil snart dukke opp på CometAPI, så følg med! Mens vi ferdigstiller opplastingen av MiniMax-M1-modellen, kan du utforske de andre modellene våre på Modeller-siden eller prøv dem i AI lekeplassMiniMaxs nyeste modell i CometAPI er Minimax ABAB7-Preview API og MiniMax Video-01 API ,se til:
