

W październikowych aktualizacjach OpenAI poinformowało, że około 0.15% aktywnych użytkowników tygodniowo prowadzić rozmowy zawierające wyraźne oznaki potencjalnego planowania lub zamiaru popełnienia samobójstwa — udział ten, w przeliczeniu na dużą bazę użytkowników ChatGPT, odpowiada ponad milion osób tygodniowo Podczas dyskusji z tą służbą na tematy związane z samobójstwem zwrócono uwagę na trudne pytanie: czy duże modele językowe mogą w sposób znaczący i bezpieczny reagować, gdy ludzie w rozmowie poruszają poważne problemy ze zdrowiem psychicznym — w tym psychozę, manię, zamiary samobójcze i głębokie uzależnienie emocjonalne?
Dlatego październikowe aktualizacje OpenAI dla GPT-5 zostały wdrożone do produkcji jako gpt-5-oct-3 Aktualizacja — to najbardziej wyraźny i przemyślany krok firmy mający na celu zwiększenie bezpieczeństwa i użyteczności dużych modeli językowych (LLM) w przypadku użytkowników zgłaszających problemy ze zdrowiem psychicznym. Zmiany nie są jednorazowym magicznym rozwiązaniem; to zestaw działań technicznych, procesowych i ewaluacyjnych, mających na celu ograniczenie szkodliwych lub nieprzydatnych wyników, uwidocznienie zasobów profesjonalnych i zniechęcenie użytkowników do polegania na modelu jako substytucie opieki klinicznej. Ale o ile system jest lepszy w praktyce, co dokładnie się zmieniło i jakie pozostają zagrożenia?
Co zaktualizował OpenAI w gpt-5 i dlaczego to ma znaczenie?
Firma OpenAI wdrożyła aktualizację domyślnego modelu GPT-5 ChatGPT (często określanego w komunikacji jako gpt-5-oct-3) mający na celu wzmocnienie zachowania modelu w delikatne rozmowy — te, które obejmują objawy psychozy lub manii, myśli lub plany samobójcze albo rodzaj emocjonalnego uzależnienia od sztucznej inteligencji, który może zastąpić relacje w świecie rzeczywistym.
Zmiany wprowadzono na podstawie konsultacji z ponad 170 ekspertami w dziedzinie zdrowia psychicznego oraz nowych wewnętrznych taksonomii i zautomatyzowanych ocen opracowanych wokół konkretnych „pożądanych zachowań”. Po ich optymalizacji przez ekspertów psychologii powstał model GPT-5:
- W przypadku zestawów wyzwań ukierunkowanych na zdrowie psychiczne nowy model GPT-5 uzyskał wyniki ~% 92 zgodne z pożądaną w firmie taksonomią zachowań (w porównaniu ze znacznie niższymi procentami dla poprzednich wersji w przypadku trudnych zestawów testowych).
- W przypadku scenariuszy samookaleczenia i samobójstwa automatyczne oceny wzrosły ~% 91 zgodność z 77% na poprzednim wariancie GPT-5 w opisanym konkretnym benchmarku. OpenAI również raportuje ~% 65 zmniejszenie wskaźników odpowiedzi, które „nie są w pełni zgodne” w kilku domenach zdrowia psychicznego w ruchu produkcyjnym.
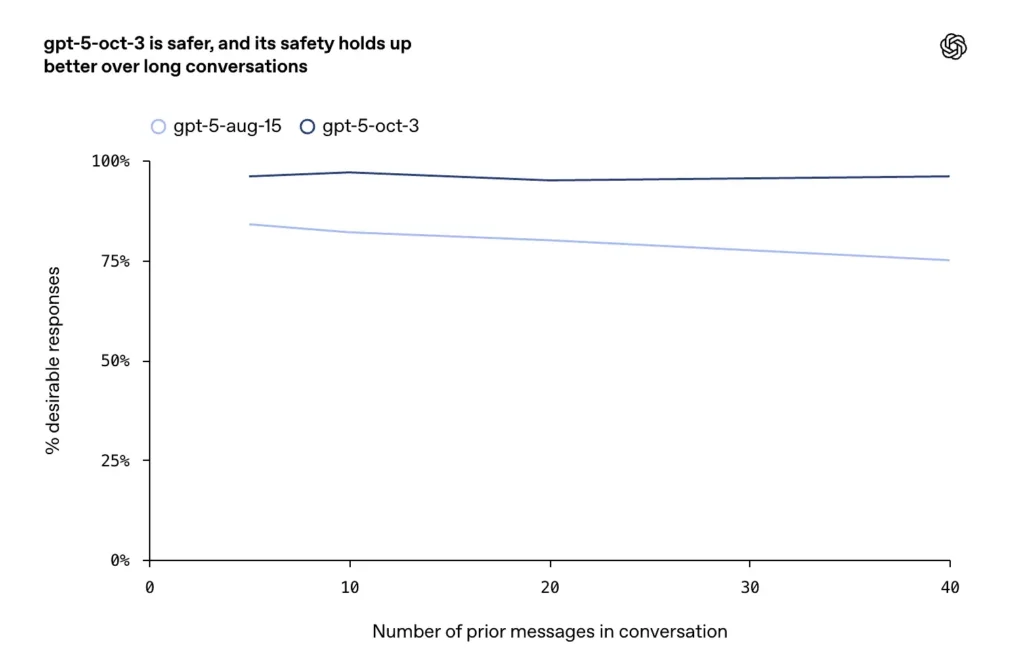
- Zgłoszono ulepszenia dotyczące długich, antagonistycznych lub przedłużających się konwersacji (znany sposób na uniknięcie błędów w modelach czatu). Firma twierdzi, że aktualizacje z października zapewniają większą spójność i bezpieczeństwo podczas dłuższych tur dialogowych.
dlaczego to ma znaczenie
OpenAI stwierdziło, że – biorąc pod uwagę obecną skalę ChatGPT – nawet bardzo niewielki odsetek wrażliwych rozmów odpowiada bardzo dużej liczbie osób. Firma podała, że w ciągu typowego tygodnia:
- Parę słów o 0.07% aktywnych użytkowników wykazuje możliwe objawy odpowiadające psychozie lub manii; i
- Parę słów o 0.15% aktywnych użytkowników prowadzi rozmowy, które zawierają wyraźne oznaki potencjalnych planów lub zamiarów samobójczych; i
- w przybliżeniu 0.15% aktywnych użytkowników wykazuje „podwyższony poziom” przywiązania emocjonalnego do ChatGPT.
Aby przedstawić te procenty konkretnie: dyrektor generalny OpenAI powiedział, że ChatGPT ma ~800 milionów aktywnych użytkowników tygodniowo. Mnożenie daje całkowitą liczbę użytkowników:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Kategorie są chaotyczne i nakładają się na siebie (jedna rozmowa może pojawić się w więcej niż jednej kategorii) i są Szacunki wynikają z wewnętrznych taksonomii wykrywania, a nie diagnoz klinicznych.
W jaki sposób OpenAI wdrożyło te zmiany — pięcioetapowy mechanizm ulepszeń?
OpenAI opisuje wielotorowy proces, oparty na wiedzy ekspertów. Poniżej znajduje się skrócony, powtarzalny pięcioetapowy mechanizm poprawy która jest zgodna z ujawnieniami firmy i powszechną praktyką w zakresie modelowej inżynierii bezpieczeństwa.
Pięcioetapowy mechanizm poprawy
- Taksonomia i etykietowanie pod okiem ekspertów. Zwołaj psychiatrów, psychologów i lekarzy podstawowej opieki zdrowotnej w celu zdefiniowania zachowań i języka, które wskazują na psychozę/manię, zamiar samookaleczenia lub niezdrową zależność emocjonalną; opracuj opisane zestawy danych i zasady orzekania.
- Celowe zbieranie danych i starannie dobrane podpowiedzi. Zbierz reprezentatywne fragmenty rozmów, przykłady skrajnych przypadków i informacje od przeciwników; uzupełnij je o kontrolowane transkrypcje odgrywanych ról, sporządzone pod nadzorem lekarza.
- Strojenie/dostrajanie modelu w celu zapewnienia bezpieczeństwa. Przeszkol lub dostosuj model bazowy na wybranym zestawie danych, stosując terminy strat, które penalizują wzmacnianie urojeń, dostarczają szablony bezpiecznych reakcji i ułatwiają kierowanie do zasobów kryzysowych.
- Klasyfikator + warstwa ochronna (bezpieczeństwo w czasie wykonywania). Wdróż szybki klasyfikator lub warstwę monitorującą, która wykrywa ryzykowne zwroty w czasie rzeczywistym i albo zmienia parametry dekodowania modelu, albo przełącza się na wyspecjalizowanego respondenta, albo eskaluje do ludzkich procesów weryfikacji. (Jest to kluczowe, aby uniknąć niestabilnego zachowania, gdy rozmowa zbacza z tematu).
- Ocena ekspercka i ciągła kalibracja. Zleć klinicystom ocenę odpowiedzi modelu w trybie ślepym za pomocą rubryk oceny klinicznej; zmierz wskaźniki niepożądanych odpowiedzi; iteruj taksonomię, dane szkoleniowe i komunikaty systemowe. Utrzymuj dane telemetryczne produkcji i regularnie przeprowadzaj testy porównawcze.
Poniżej znajduje się zwarty pseudokod/szkic techniczny, który odzwierciedla przepływ czasu wykonania wdrażany przez większość zespołów ds. bezpieczeństwa (to jest ilustracyjny i niebędące własnością):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Proces produkcyjny zazwyczaj obejmuje klasyfikatory krótkoterminowe (szybkie), wolniejsze, ale lepszej jakości odpowiedzi (specjalistyczne monity / dostrojone punkty kontrolne) oraz ocenę ludzką dla oznaczonych przypadków. Nie jest to kwestia czysto akademicka: klinicyści oceniają ponad 1,800 modelowe odpowiedzi i oceniano je na podstawie taksonomii; przeglądy te w istotny sposób ukształtowały sposób pisania monitów i zachowań awaryjnych.
Przedstawiciele OpenAI poinformowali, że do oceny wyników wykorzystali warianty wszystkich pięciu etapów i oceny lekarzy:
- Eksperci przeanalizowali ponad 1,800 odpowiedzi modeli.
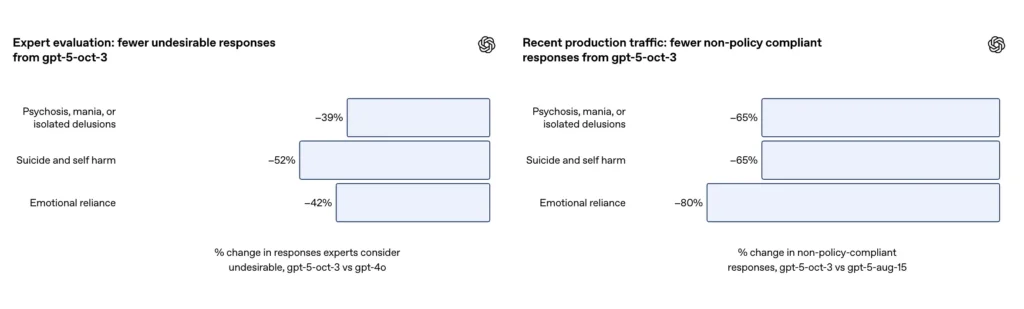
- GPT-5 zmniejszyło liczbę „niezadowalających odpowiedzi” o 39–52% we wszystkich kategoriach.
- Niezawodność między oceniającymi mieściła się w przedziale 71–77%, co wskazuje na wysoki stopień ogólnej jednomyślności, pomimo subiektywnych różnic.
Jak GPT-5 reaguje obecnie na psychozę lub manię?
Czego OpenAI nauczył model robić (a czego nie)
Zmierzyć: Poprawa rozpoznawania i reakcji modelu na poważne objawy, takie jak halucynacje i mania. W przypadku rozmów sygnalizujących potencjalne urojenia, halucynacje lub manię, OpenAI przepisał fragmenty specyfikacji modelu i udostępnił nadzorowane przykłady treningowe, dzięki czemu GPT-5 reaguje bez potwierdzania ani wzmacniania nieuzasadnionych przekonań. Model powinien być empatyczny, unikać potwierdzania urojeń i delikatnie przeformułowywać lub kierować użytkownika w stronę praktycznych środków bezpieczeństwa i profesjonalnej pomocy, gdy jest to uzasadnione.
Co pokazuje ocena
Firma OpenAI podaje, że w testowym zestawie trudnych rozmów na temat psychozy/manii nowszy model GPT-5 znacząco zmniejszył liczbę niepożądanych reakcji w porównaniu z poprzednimi modelami bazowymi, a zautomatyzowane oceny wykazały wysoką zgodność zaktualizowanego modelu z jego taksonomią.
| metryczny | GPT-4o | GPT-5 | Poprawa |
|---|---|---|---|
| Współczynnik odpowiedzi niezgodnych | Baseline | ↓ 65% | Znaczna poprawa |
| Ocena eksperta klinicznego | - | Zmniejszenie działań niepożądanych o 39% | - |
| Współczynnik zgodności automatycznej oceny | 27% | 92% | ↑65 punktów procentowych |
| Wskaźnik zaangażowania użytkowników | ~0.07% aktywnych użytkowników tygodniowo | Bardzo niski, ale wyraźnie monitorowany | - |
Uwaga:
- Liczba niewłaściwych odpowiedzi spadła o 65%;
- Tylko 0.07% użytkowników i 0.01% wiadomości zawierało taką treść;
- W ocenach ekspertów GPT-5 wywołał o 39% mniej niewłaściwych reakcji niż GPT-4o;
- W ocenach zautomatyzowanych GPT-5 osiągnął 92% wskaźnik zgodności (w porównaniu do 27% w przypadku poprzedniego systemu).
W jaki sposób GPT-5 pomaga w walce z myślami samobójczymi i samookaleczeniem?
Silniejsze kierowanie do wsparcia i odmowa udzielania instrukcji
OpenAI opisuje rozszerzone i szczegółowe szkolenie w zakresie przypadków samookaleczenia i samobójstwa: model jest szkolony w zakresie rozpoznawania bezpośrednich i pośrednich sygnałów intencji lub planowania, stosowania języka empatycznego i deeskalującego, udostępniania zasobów kryzysowych (infolinie, lokalne instrukcje dotyczące sytuacji awaryjnych) oraz odmowy udzielania instrukcji dotyczących samookaleczenia. Aktualizacje z października kładą nacisk na bardziej trwałe zachowania w długich rozmowach, podczas gdy wcześniejsze modele czasami dryfowały w kierunku odpowiedzi niebezpiecznych lub niespójnych.
Zmierzone wyniki
W starannie dobranym zestawie ewaluacyjnym trudnych rozmów na temat samookaleczenia i samobójstwa firma OpenAI informuje, że zaktualizowany test GPT-5 osiągnął 91% zgodności z pożądanymi zachowaniami OpenAI w porównaniu z 77% dla poprzedniego modelu GPT-5. Firma twierdzi również, że eksperci w tej dziedzinie ocenili, że zaktualizowany model zmniejsza liczbę niepożądanych odpowiedzi o około 52% w porównaniu z GPT-4o na tym samym zestawie problemów. Ponadto OpenAI twierdzi, że szacunkowo 65% redukcja w ruchu produkcyjnym odpowiedzi, które „nie są w pełni zgodne” z ich taksonomią sytuacji samookaleczenia po wdrożeniu nowych zabezpieczeń.
| metryczny | GPT-4o | GPT-5 | Poprawa |
|---|---|---|---|
| Wskaźnik niewłaściwej odpowiedzi | Baseline | ↓ 65% | Znaczna poprawa |
| Ocena eksperta klinicznego | - | Niewłaściwe odpowiedzi zmniejszone o 52% | - |
| Współczynnik zgodności automatycznej oceny | 77% | 91% | ↑14 punktów procentowych |
| Wskaźnik zaangażowania użytkowników | 0.15% tygodniowo (miliony użytkowników) | Bardzo niski, ale społecznie znaczący | - |
Uwaga:
- Liczba niewłaściwych odpowiedzi spadła o 65%;
- Około 0.15% użytkowników i 0.05% wiadomości zawierało potencjalne ryzyko samobójstwa;
- Oceny ekspertów wykazały, że GPT-5 zmniejszyło liczbę niewłaściwych reakcji o 52% w porównaniu z GPT-4o;
- Wskaźnik zgodności w przypadku ocen automatycznych wzrósł do 91% (w porównaniu do 77% w przypadku poprzedniej generacji);
- Podczas dłuższych rozmów GPT-5 utrzymywał stabilność na poziomie ponad 95%.
Czym jest „zależenie emocjonalne” i jak jest ono rozwiązywane?
Wyzwanie związane z tworzeniem załączników przez użytkowników
OpenAI definiuje zależność emocjonalną jako wzorce, w których użytkownik wykazuje potencjalnie niezdrową zależność od sztucznej inteligencji, szkodzącą realnym relacjom, obowiązkom lub dobremu samopoczuciu. Nie jest to natychmiastowe naruszenie bezpieczeństwa fizycznego, jak instrukcje dotyczące samookaleczenia, ale problem bezpieczeństwa behawioralnego, który z czasem może osłabić wsparcie społeczne i odporność psychiczną danej osoby. Firma wyraźnie określiła zależność emocjonalną jako kategorię w swoich pracach nad specyfikacją modelu i nauczyła go, jak zachęcać do kontaktów w realnym świecie, normalizować kontakt z ludźmi i unikać języka wzmacniającego wyłączność przywiązania.
Podczas tych rozmów model został wytrenowany w celu:
- Zachęcaj użytkowników do kontaktu ze znajomymi, rodziną lub terapeutą;
- Unikaj wzmacniania przywiązania do AI;
- Na urojenia i fałszywe przekonania należy reagować w sposób łagodny i racjonalny.
Zgłoszono wyniki
Według dodatku OpenAI aktualizacja wygenerowała ~80% redukcji w tempie odpowiedzi modelu, które nie są w pełni zgodne z taksonomią zależności emocjonalnej w ruchu produkcyjnym. W przypadku starannie dobranych rozmów ewaluacyjnych, automatyczne oceny oceniały zaktualizowany model na poziomie 97% zgodności z pożądanym zachowaniem w scenariuszach zależności emocjonalnej, w porównaniu z 50% w poprzednim GPT-5. Liczby sugerują znaczną poprawę w stosunku do konkretnej taksonomii i zestawu testowego; jednak pomiar zależności emocjonalnej w środowisku naturalnym jest z natury obarczony błędami i wrażliwy na różnice kulturowe i kontekstowe.
| metryczny | GPT-4o | GPT-5 | Poprawa |
|---|---|---|---|
| Współczynnik odpowiedzi niezgodnych | 50% | 97% zgodny | ↓80% niewłaściwych odpowiedzi |
| Ocena eksperta | Liczba nieodpowiednich odpowiedzi zmniejszyła się o 42% | - | - |
| Wskaźnik zaangażowania użytkowników | 0.15% użytkowników/tydzień, 0.03% wiadomości | Rzadkie, ale istnieje | - |
| Zachowanie modelu | Zachęca do realnych relacji, odrzuca „symulowany romans społeczny” | - | - |
Uwaga:
- Liczba niewłaściwych odpowiedzi spadła o 80%;
- Około 0.15% użytkowników/0.03% wiadomości wykazało oznaki potencjalnego uzależnienia emocjonalnego od sztucznej inteligencji;
- Ocena ekspertów wykazała, że GPT-5 zmniejszyło liczbę niewłaściwych reakcji o 42% w porównaniu z GPT-4o;
- Zgodność z automatyczną oceną znacznie wzrosła – z 50% do 97%.
Jakie są ograniczenia i potencjalne ryzyka?
Fałszywie negatywy i fałszywie pozytywne wyniki
- Fałszywe negatywy:model może nie być w stanie zidentyfikować subtelnych lub skodyfikowanych sygnałów świadczących o tym, że użytkownik znajduje się w poważnym niebezpieczeństwie — zwłaszcza gdy ludzie komunikują się pośrednio lub za pomocą kodu.
- Fałszywie pozytywne:System może eskalować lub wysyłać komunikaty kryzysowe w przypadkach, które tego nie wymagają, co może podważyć zaufanie użytkowników lub wywołać niepotrzebny alarm. Oba typy błędów są istotne, ponieważ kształtują zachowania użytkowników i postrzeganie opieki. OpenAI uznaje, że detekcja jest niedoskonała.
Nadmierne poleganie na automatyzacji
Nawet najlepszy model może zachęcać niektórych użytkowników do polegania na natychmiastowych i zawsze dostępnych odpowiedziach sztucznej inteligencji zamiast szukania stałego wsparcia ze strony człowieka. OpenAI wyraźnie oznacza zależność emocjonalną jako kategorię bezpieczeństwa ze względu na to ryzyko; aktualizacje firmy starają się zachęcać użytkowników do kontaktów międzyludzkich, ale dynamikę społeczną trudno zmienić za pomocą samych komunikatów.
Luki kontekstowe i kulturowe
Frazy bezpieczeństwa, które wydają się odpowiednie w jednej kulturze lub języku, mogą nie być zrozumiałe w innej. Konieczna jest dokładna lokalizacja i ocena uwzględniająca kontekst kulturowy; opublikowane wyniki OpenAI nie zawierają jeszcze pełnego podziału według języka lub regionu.
Ekspozycja prawna i etyczna
Gdy rzadkie awarie pociągają za sobą poważne konsekwencje, firmy stają w obliczu ryzyka prawnego i utraty reputacji (co podkreślają doniesienia medialne i pozwy sądowe). Przejrzystość OpenAI w zakresie skali problemu i działań na rzecz minimalizacji szkód jest ważnym krokiem, ale jednocześnie wymaga kontroli regulacyjnej i prawnej.
Czy GPT-5 może teraz poradzić sobie z problemami zdrowia psychicznego?
Krótka odpowiedź: Znacznie lepiej radzi sobie z wieloma wąskimi, mierzalnymi zadaniamiOpublikowane wskaźniki OpenAI wskazują na znaczącą redukcję niepożądanych reakcji w zestawach testów dotyczących samookaleczenia, psychozy/manii i uzależnienia emocjonalnego. To realna poprawa, możliwa dzięki opiniom ekspertów, bardziej przejrzystym taksonomiom oraz intensywnej ocenie i monitorowaniu. Publiczne dane firmy – wysokie wskaźniki zgodności i znaczna redukcja liczby odpowiedzi niezgodnych z wymaganiami w zestawach testowych – stanowią jak dotąd najsilniejszy dowód na to, że celowa, interdyscyplinarna inżynieria i współpraca kliniczna mogą znacząco zmienić zachowanie modeli.
Jak uzyskać dostęp do najnowszego API GPT-5?
CometAPI to ujednolicona platforma API, która agreguje ponad 500 modeli AI od wiodących dostawców — takich jak seria GPT firmy OpenAI, Gemini firmy Google, Claude firmy Anthropic, Midjourney, Suno i innych — w jednym, przyjaznym dla programistów interfejsie. Oferując spójne uwierzytelnianie, formatowanie żądań i obsługę odpowiedzi, CometAPI radykalnie upraszcza integrację możliwości AI z aplikacjami. Niezależnie od tego, czy tworzysz chatboty, generatory obrazów, kompozytorów muzycznych czy oparte na danych potoki analityczne, CometAPI pozwala Ci szybciej iterować, kontrolować koszty i pozostać niezależnym od dostawcy — wszystko to przy jednoczesnym korzystaniu z najnowszych przełomów w ekosystemie AI.
Deweloperzy mogą uzyskać dostęp API GPT-5 poprzez CometAPI, najnowsza wersja modelu jest zawsze aktualizowany na oficjalnej stronie internetowej. Na początek zapoznaj się z możliwościami modelu w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. Interfejs API Comet zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
Gotowy do drogi?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości na temat sztucznej inteligencji, obserwuj nas na VK, X oraz Discord!