

OpenAIは10月のアップデートで、 週アクティブユーザーの0.15% 自殺の計画や意図を明示的に示す会話をしているユーザーの割合は、ChatGPTの大規模なユーザーベースに当てはめると、 毎週100万人以上 このサービスで自殺関連の話題を議論する中で、ある難しい問題に注目が集まっています。それは、人々が精神病、躁病、自殺願望、深い感情的依存などの深刻な精神的健康問題をチャットで持ち込んだとき、大規模言語モデルは意味のある安全な対応ができるのか、という問題です。
そのため、OpenAIの10月のGPT-5のアップデートは、 gpt-5-oct-3 アップデートは、大規模言語モデル(LLM)をより安全で、ユーザーがメンタルヘルスに関する懸念を表明した際により有用なものにするための、同社による最も明確かつ慎重な取り組みを表しています。これらの変更は単一の魔法の解決策ではありません。有害または役に立たない出力を削減し、専門家のリソースを可視化し、ユーザーがモデルを臨床ケアの代替として頼ることを抑制することを目的とした、技術、プロセス、評価の一連の取り組みです。しかし、このシステムは実際にどれほど改善されたのでしょうか?具体的に何が変更されたのでしょうか?そして、どのようなリスクが残っているのでしょうか?
OpenAI は gpt-5 で何を更新しましたか? また、それがなぜ重要なのですか?
OpenAIはChatGPTのデフォルトのGPT-5モデル(一般的には gpt-5-oct-3)は、特にモデルの挙動を強化することを目的としています。 デリケートな会話 精神病や躁病の兆候、自殺念慮や自殺計画、あるいは現実世界の人間関係に取って代わる可能性のある AI への感情的依存などが含まれます。
この変更は、170人以上のメンタルヘルスの専門家との協議と、具体的な「望ましい行動」を中心に設計された新しい内部分類法と自動評価に基づいて行われました。心理学の専門家によって最適化されたGPT-5モデルは次のとおりです。
- 対象を絞ったメンタルヘルスチャレンジセットでは、新しいGPT-5モデルは 〜92%で 会社の望ましい動作分類に準拠しています (以前のバージョンでは、難しいテスト セットでこの割合がはるかに低かったです)。
- 自傷や自殺のシナリオでは、自動評価は 〜91%で コンプライアンスから 77% 前述の特定のベンチマークにおけるGPT-5の以前のバージョンと比較した。OpenAIはまた、 〜65%で 生産トラフィックにおけるいくつかのメンタルヘルス領域にわたる「完全に準拠していない」という回答率の減少。
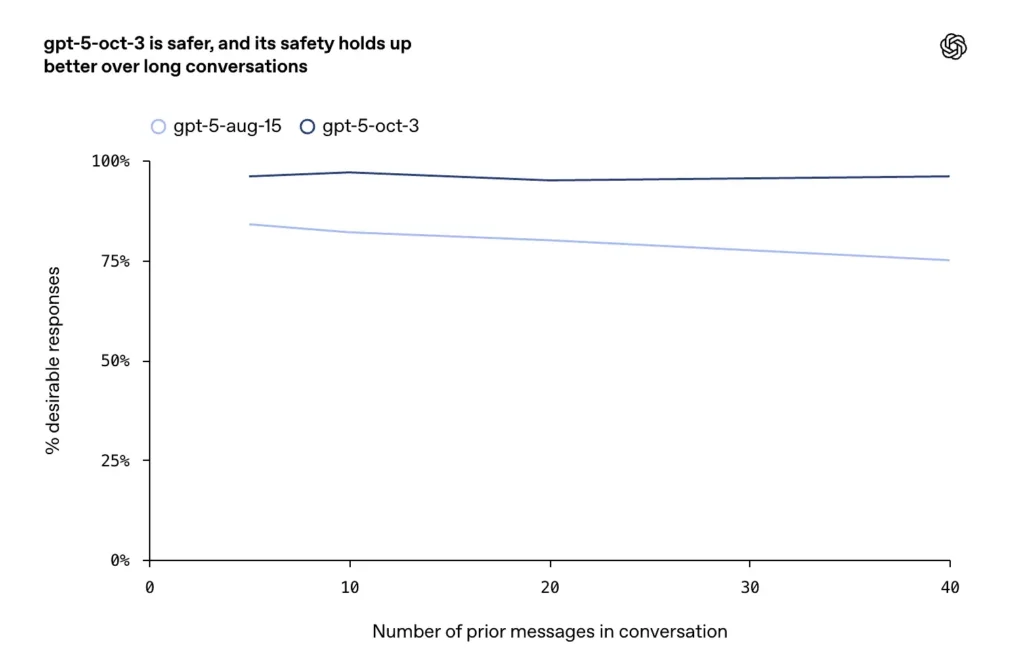
- 長く、敵対的、または長引く会話(チャット モデルの既知の障害モード)での改善が報告されており、同社によれば、10 月のアップデートにより、長時間の対話全体で一貫性と安全性が向上したとのことです。
なぜそれが重要なのか
OpenAIは、ChatGPTの現在の規模を考えると、たとえセンシティブな会話がごくわずかであっても、その絶対数は非常に多いと述べている。同社は、典型的な1週間について次のように報告している。
- 自己紹介 0.07% 活動的な使用者には精神病や躁病と一致する兆候が見られる。
- 自己紹介 0.15% アクティブユーザーのうち、自殺の計画や意図を明示的に示す会話をしているユーザーの割合。
- 大体 0.15% アクティブユーザーの多くは、ChatGPTに対する感情的な愛着が「高まったレベル」で現れています。
これらの割合を具体的にするために、OpenAIのCEOはChatGPTが〜であると述べた。毎週 800 億人のアクティブ ユーザー. 掛け算すると絶対的なユーザー数が得られます。
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
カテゴリはノイズが多く重複している(1つの会話が複数のカテゴリに現れる可能性がある)ため、 見積もり 臨床診断ではなく内部検出分類から導き出されたものです。
OpenAI はこれらの変更 (5 段階の改善メカニズム) をどのように実装したのでしょうか?
OpenAIは、専門家の知見に基づいた多面的なプロセスを説明しています。以下は、要約された再現可能なプロセスです。 5段階改善メカニズム これは、同社の開示内容とモデル安全工学における一般的な実践に一致しています。
5段階の改善メカニズム
- 専門家による分類とラベル付け。 精神科医、心理学者、プライマリケアの臨床医を集めて、精神病/躁病、自傷の意図、または不健康な感情的依存を示す行動と言語を定義し、ラベル付けされたデータセットと判定ルールを構築します。
- ターゲットを絞ったデータ収集と厳選されたプロンプト。 代表的な会話の断片、エッジケースの例、敵対的な入力を集め、臨床医の監督下で作成された制御されたロールプレイのトランスクリプトで補強します。
- 安全性を目的としたモデルのチューニング/微調整。 妄想の強化を罰し、安全な対応テンプレートを提供し、危機リソースへのルーティングを促進する損失条件を使用して、キュレーションされたデータセットで基本モデルをトレーニングまたは微調整します。
- 分類器 + ガードレール レイヤー (実行時の安全性)。 リスクの高いターンをリアルタイムで検出し、モデルのデコードパラメータを変更するか、専門のレスポンダーに切り替えるか、人間によるレビューパイプラインにエスカレーションする、高速分類器または監視レイヤーを導入します。(これは、会話が逸れた際に脆弱な動作を回避するために不可欠です。)
- 人間の専門家による評価と継続的な調整。 臨床評価ルーブリックを用いて、臨床医にモデルの回答をブラインド評価させ、望ましくない回答率を測定し、分類、トレーニングデータ、システムプロンプトを反復的に改善します。本番環境のテレメトリを維持し、ベンチマークを定期的に再実行します。
以下は、ほとんどの安全チームが実装するランタイムフローをキャプチャしたコンパクトな擬似コード/技術スケッチです(これは 実例 非独占的):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
実稼働パイプラインでは、通常、短期的な分類器(高速)、低速だが質の高い対応者(特別なプロンプト/調整されたチェックポイント)、そしてフラグ付けされた症例に対する人間によるレビューが重ねられます。これは単なる学術的な話ではありません。臨床医が1000件以上の症例をレビューしています。 1,800 モデル応答を作成し、分類法に基づいて評価し、それらのレビューによってプロンプトとフォールバック動作の書き方が実質的に決まりました。
OpenAI の公開情報によると、彼らは結果を評価するために 5 つのステップすべてのバリエーションと臨床医の評価を使用したとのことです。
- 専門家は1,800件を超えるモデル回答を審査しました。
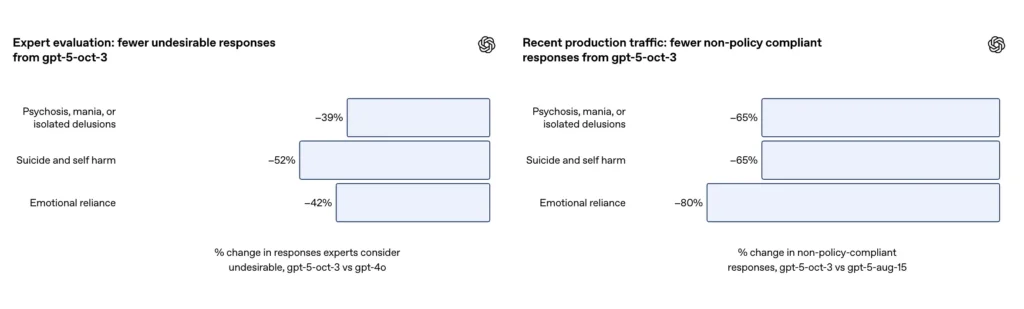
- GPT-5 は、すべてのカテゴリーで「不満足な回答」を 39~52% 削減しました。
- 評価者間の信頼性は 71 ~ 77% の範囲で、主観的な違いがあるにもかかわらず、全体的に高いレベルの合意があることを示しています。
GPT-5 は現在、精神病や躁病にどのように反応するのでしょうか?
OpenAIがモデルに教えた行動(そして教えなかった行動)
測定: 幻覚や躁病などの重篤な症状に対するモデルの認識と対応を改善しました。妄想、幻覚、躁病の可能性を示唆する会話については、OpenAIはモデル仕様の一部を書き直し、教師あり学習例を提供することで、GPT-5が根拠のない信念を肯定または増幅することなく応答できるようにしました。モデルは共感性を持ち、妄想を正当化することを避け、必要に応じてユーザーを適切な安全対策や専門家の支援へと優しく再構成または誘導することが推奨されています。
評価からわかること
OpenAI は、精神病/躁病に関する難しい会話のテスト セットで、新しい GPT-5 により、以前のベースラインと比較して望ましくない応答が大幅に削減され、自動評価により更新されたモデルが分類法に高い準拠性があると評価されたと報告しています。
| メトリック | GPT-4o | GPT-5 | 改善 |
|---|---|---|---|
| 非準拠回答率 | ベースライン | ↓65% | 著しい向上 |
| 臨床専門家による評価 | - | 副作用を39%減少 | - |
| 自動評価コンプライアンス率 | 27% | 92% | ↑65パーセントポイント |
| ユーザー関与率 | 週アクティブユーザー数: 約0.07% | 非常に低いが、明確に監視されている | - |
注意:
- 不適切な応答が 65% 減少しました。
- このようなコンテンツが含まれていたのは、ユーザーのわずか 0.07% とメッセージの 0.01% のみでした。
- 専門家の評価では、GPT-5 は GPT-4o よりも不適切な応答を 39% 少なく生成しました。
- 自動評価では、GPT-5 は 92% のコンプライアンス率を達成しました (前身の 27% と比較)。
GPT-5 は自殺念慮や自傷行為にどのように対処しますか?
サポートへのルーティング強化と指示提供の拒否
OpenAIは、自傷行為と自殺のケースに対する拡張された明示的なトレーニングについて説明しています。このモデルは、意図や計画の直接的および間接的なシグナルを認識し、共感的で緊張を和らげる言葉遣いをし、危機対応リソース(ホットライン、地域の緊急時対応情報)を提示し、自傷行為の指示を拒否するように訓練されています。10月のアップデートでは、以前のモデルでは安全でない、あるいは一貫性のない回答に陥ることがあった長い会話において、より持続的な行動を重視しています。
測定された成果
OpenAIは、自傷行為や自殺に関する会話を精選した評価セットにおいて、更新されたGPT-5が 91% コンプライアンス OpenAIの望ましい行動と比較して 77% 同社はまた、専門家らが更新モデルによって不要な回答が約5%減少したと評価したと述べている。 GPT-4oと比較して52% 同じ問題セットで。さらに、OpenAIは推定で 65%の減少 新しい安全対策を展開した後、自傷行為の状況に関する分類に「完全に準拠していない」応答が本番環境のトラフィックに多く含まれていました。
| メトリック | GPT-4o | GPT-5 | 改善 |
|---|---|---|---|
| 不適切な回答率 | ベースライン | ↓65% | 著しい向上 |
| 臨床専門家による評価 | - | 不適切な応答が52%減少 | - |
| 自動評価コンプライアンス率 | 77% | 91% | ↑14パーセントポイント |
| ユーザー関与率 | 毎週0.15%(ユーザー数百万) | 非常に低いが社会的に重要 | - |
注意:
- 不適切な応答が 65% 減少しました。
- 約 0.15% のユーザーと 0.05% のメッセージに潜在的な自殺の危険性がありました。
- 専門家の評価によると、GPT-5 は GPT-4o と比較して不適切な応答を 52% 削減しました。
- 自動評価におけるコンプライアンス率は 91% に向上しました (前世代では 77%)。
- 長時間の会話において、GPT-5 は 95% 以上の安定性を維持しました。
「感情的依存」とは何ですか?また、それはどのように対処されましたか?
ユーザーが愛着を形成する際の課題
OpenAIは、感情的依存を、ユーザーがAIに潜在的に不健全な依存を示し、現実世界の人間関係、責任、または幸福を損なうパターンと定義しています。これは、自傷行為の指示のように、直ちに身体的な安全上の問題となるものではありませんが、時間の経過とともに人の社会的支援と回復力を蝕む可能性のある行動上の安全上の問題です。同社は、モデル仕様策定作業において感情的依存を明確なカテゴリーとし、現実世界のつながりを促進し、人との接触を当たり前のこととし、愛着の排他性を強化するような言葉遣いを避けるようにモデルを学習させました。
これらの会話では、モデルは次のことを行えるようにトレーニングされました。
- ユーザーに友人、家族、またはセラピストに連絡するよう勧めます。
- AIへの愛着を強化しないようにしてください。
- 妄想や誤った信念に対しては、穏やかかつ合理的な態度で対応してください。
報告された結果
OpenAIの補足によると、このアップデートにより、 約80%削減 実稼働トラフィックにおける感情依存分類に完全に準拠しないモデル応答の割合。キュレーションされた評価会話では、自動評価により更新されたモデルは 97% コンプライアンス 感情依存シナリオにおいて、GPT-5は50%という高い割合で望ましい行動を示しました。この数値は、特定の分類とテストセットにおいて大きな改善を示唆しています。しかし、現実世界での感情依存の測定は、本質的にノイズが多く、文化や文脈の違いに敏感です。
| メトリック | GPT-4o | GPT-5 | 改善 |
|---|---|---|---|
| 非準拠回答率 | 50% | 97%準拠 | ↓80% 不適切な回答 |
| 専門家の評価 | 不適切な回答が42%減少 | - | - |
| ユーザー関与率 | 0.15% ユーザー/週、0.03% メッセージ | 稀ではあるが存在する | - |
| モデルの動作 | 現実世界の人間関係を奨励し、「模擬的な社交恋愛」を拒否する | - | - |
注意:
- 不適切な応答が 80% 減少しました。
- 約 0.15% のユーザー / 0.03% のメッセージに、AI に対する潜在的な感情的依存の兆候が見られました。
- 専門家の評価によると、GPT-5 は GPT-4o と比較して不適切な応答を 42% 削減しました。
- 自動評価のコンプライアンスは 50% から 97% に大幅に向上しました。
制限と未解決のリスクは何ですか?
偽陰性と偽陽性
- 偽陰性: 特に人々が間接的または暗号化して通信している場合、モデルはユーザーが深刻な危険にさらされていることを示す微妙なまたは暗号化された信号を識別できない可能性があります。
- 偽陽性システムが、必要のない状況でエスカレーションしたり、危機メッセージを表示したりする可能性があり、ユーザーの信頼を損なったり、不必要な警告を発したりする可能性があります。どちらのエラータイプも、ユーザーの行動やケアに対する認識に影響を与えるため、重要です。OpenAIは、検出が不完全であることを認識しています。
自動化への過度の依存
たとえ最高のモデルであっても、一部のユーザーは、継続的な人間によるサポートを求めるのではなく、いつでも利用可能な即時のAI応答に頼ってしまう可能性があります。OpenAIは、こうしたリスクがあるため、感情的な依存を安全カテゴリーとして明確に警告しています。同社のアップデートは、ユーザーを人間とのつながりへと促すよう努めていますが、メッセージによる指示だけで社会的な力学を変えることは困難です。
文脈と文化のギャップ
ある文化や言語では適切に見える安全フレーズが、別の文化や言語ではニュアンスが伝わらない可能性があります。徹底したローカライズと文化を考慮した評価が必要です。OpenAIが公開した結果では、言語や地域ごとの詳細な内訳はまだ提供されていません。
法的および倫理的リスク
稀な失敗が深刻な結果をもたらす場合、企業は法的リスクと評判リスクに直面することになります(メディア報道や訴訟で明らかになったように)。OpenAIが問題の規模と被害軽減に向けた取り組みについて透明性を示したことは重要な一歩ですが、同時に規制当局や法的な精査を招く可能性もあります。
それで、GPT-5 はメンタルヘルスの問題に対処できるようになりますか?
短い答え: 多くの限定的で測定可能なタスクでは、大幅に優れていますOpenAIが公開した指標は、自傷行為、精神病/躁病、感情依存のテストスイート全体で、望ましくない反応が大幅に減少したことを示しています。これは専門家の意見、より明確な分類、そして積極的な評価とモニタリングによって実現された真の改善です。同社が公表した数値、つまりキュレーションされたセットにおける高いコンプライアンス率と非コンプライアンス反応の大幅な減少は、意図的な学際的なエンジニアリングと臨床連携によってモデルの挙動を大きく変えることができるという、これまでで最も強力な証拠です。
最新の GPT-5 API にアクセスするにはどうすればいいですか?
CometAPIは、OpenAIのGPTシリーズ、GoogleのGemini、AnthropicのClaude、Midjourney、Sunoなど、主要プロバイダーの500以上のAIモデルを、開発者にとって使いやすい単一のインターフェースに統合する統合APIプラットフォームです。一貫した認証、リクエストフォーマット、レスポンス処理を提供することで、CometAPIはAI機能をアプリケーションに統合することを劇的に簡素化します。チャットボット、画像ジェネレーター、音楽作曲ツール、データドリブン分析パイプラインなど、どのようなアプリケーションを構築する場合でも、CometAPIを利用することで、反復処理を高速化し、コストを抑え、ベンダーに依存しない環境を実現できます。同時に、AIエコシステム全体の最新のブレークスルーを活用できます。
開発者はアクセスできる GPT-5 API CometAPIを通じて、 最新モデルバージョン 公式ウェブサイトで常に更新されています。まずは、モデルの機能について調べてみましょう。 プレイグラウンド そして相談する APIガイド 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。 コメットAPI 統合を支援するために、公式価格よりもはるかに低い価格を提供します。
準備はいいですか?→ 今すぐCometAPIに登録しましょう !