

В своих октябрьских обновлениях OpenAI сообщил, что около 0.15% еженедельно активных пользователей ведут разговоры, которые содержат явные признаки потенциального планирования или намерения совершить самоубийство — доля, которая, если масштабировать ее до большой базы пользователей ChatGPT, соответствует более миллиона человек каждую неделю Обсуждая темы, связанные с самоубийством, с сервисом, он высветил сложный вопрос: могут ли большие языковые модели осмысленно и безопасно реагировать, когда люди приносят в чат серьезные проблемы с психическим здоровьем, включая психоз, манию, суицидальные намерения и глубокую эмоциональную зависимость?
Таким образом, октябрьские обновления OpenAI для GPT-5, запущенные в производство, gpt-5-oct-3 Обновление — представляет собой наиболее явный и взвешенный шаг компании к повышению безопасности и пользы больших языковых моделей (LLM) при обращении пользователей с вопросами о психическом здоровье. Эти изменения — не просто волшебное средство; это комплекс технических, процессуальных и оценочных мер, призванных сократить количество вредных или бесполезных результатов, выявить профессиональные ресурсы и отбить у пользователей желание использовать модель как замену клинической помощи. Но насколько лучше стала система на практике, что именно изменилось и каковы оставшиеся риски?
Что обновила OpenAI в gpt-5 и почему это важно?
OpenAI развернула обновление для стандартной модели ChatGPT GPT-5 (обычно упоминаемой в сообщениях как gpt-5-oct-3) предназначен специально для усиления поведения модели в деликатные разговоры — те, которые включают признаки психоза или мании, суицидальные мысли или планирование, или такую эмоциональную зависимость от ИИ, которая может вытеснить реальные отношения.
Изменения были обусловлены консультациями с более чем 170 экспертами в области психического здоровья, а также новыми внутренними таксономиями и автоматизированными оценками, разработанными на основе конкретных «желаемых моделей поведения». После оптимизации экспертами-психологами модель GPT-5:
- В целевых наборах задач на психическое здоровье новая модель GPT-5 набрала ~ 92% соответствует таксономии желаемого поведения компании (по сравнению с гораздо более низкими процентами для предыдущих версий на сложных тестовых наборах).
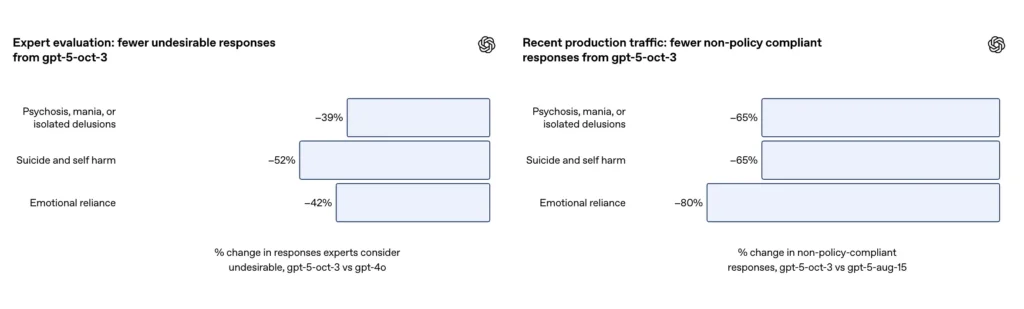
- В сценариях самоповреждения и самоубийства автоматизированные оценки возросли до ~ 91% соответствие от 77%. на предыдущем варианте GPT-5 в описанном тесте. OpenAI также сообщает ~ 65% снижение показателей ответов, которые «не полностью соответствуют» в нескольких областях психического здоровья в производственном трафике.
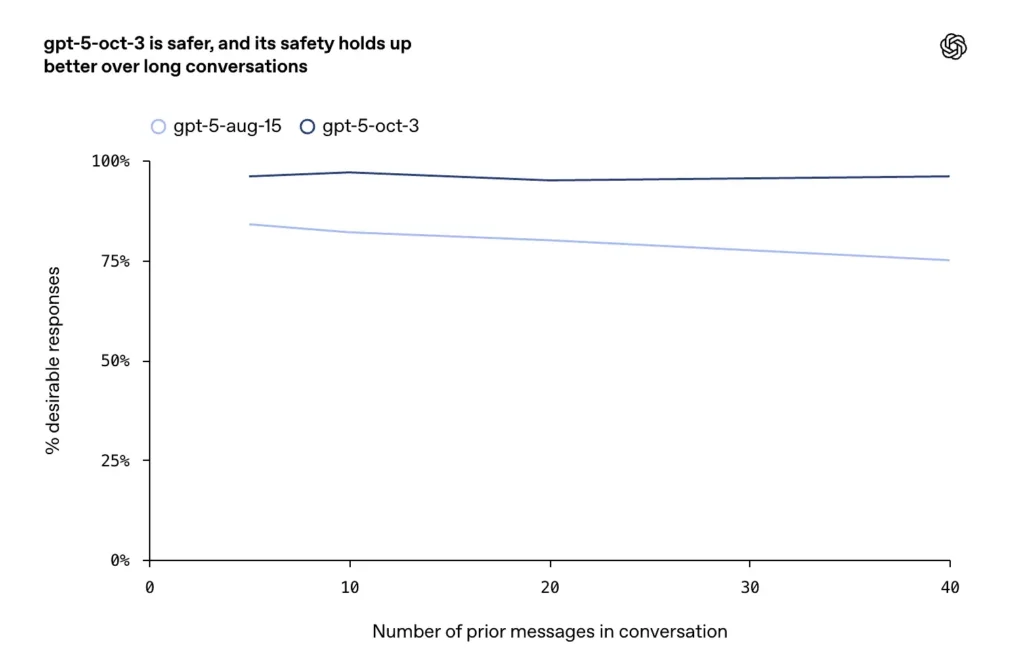
- Улучшения были отмечены в длинных, враждебных или затянутых разговорах (известный вид сбоя для моделей чата), где, по словам компании, октябрьские обновления обеспечивают большую согласованность и безопасность в течение продолжительных диалогов.
почему это имеет значение
OpenAI заявила, что, учитывая нынешний масштаб ChatGPT, даже очень небольшой процент конфиденциальных разговоров соответствует очень большому абсолютному числу людей. Компания сообщила, что в течение типичной недели:
- о 0.07%. активных пользователей проявляют возможные признаки, соответствующие психозу или мании; и
- о 0.15%. активных пользователей ведут разговоры, в которых присутствуют явные признаки потенциального суицидального планирования или намерения; и
- около 0.15%. активных пользователей демонстрируют «повышенный уровень» эмоциональной привязанности к ChatGPT.
Чтобы сделать эти проценты конкретными: генеральный директор OpenAI сказал, что ChatGPT имеет ~800 миллионов активных пользователей еженедельно. Умножение даёт абсолютное количество пользователей:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Категории шумные и перекрывающиеся (один разговор может появиться в более чем одной категории), и что они Оценки полученные на основе таксономий внутреннего обнаружения, а не клинических диагнозов.
Как OpenAI реализовала эти изменения — пятиступенчатый механизм улучшения?
OpenAI описывает многоаспектный процесс, основанный на экспертной информации. Ниже представлено краткое, воспроизводимое описание пятиступенчатый механизм улучшения это соответствует раскрытию информации компанией и общепринятой практике в области проектирования безопасности моделей.
Пятиступенчатый механизм улучшения
- Таксономия и маркировка под руководством экспертов. Соберите психиатров, психологов и врачей первичной медико-санитарной помощи для определения поведения и языка, которые указывают на психоз/манию, намерение причинить себе вред или нездоровую эмоциональную зависимость; создайте маркированные наборы данных и правила вынесения решений.
- Целевой сбор данных и тщательно подобранные подсказки. Соберите репрезентативные фрагменты разговоров, примеры исключительных случаев и противоречивые мнения; дополните их стенограммами контролируемых ролевых игр, созданными под контролем врача.
- Настройка/тонкая настройка модели с учетом целей безопасности. Обучите или доработайте базовую модель на основе подобранного набора данных с использованием коэффициентов потерь, которые штрафуют за усиление заблуждений, предоставляют шаблоны безопасных ответов и способствуют перенаправлению к ресурсам в кризисной ситуации.
- Классификатор + защитный слой (безопасность во время выполнения). Разверните быстрый классификатор или уровень мониторинга, который обнаруживает высокорисковые повороты в режиме реального времени и либо изменяет параметры декодирования модели, либо переключается на специализированный ответчик, либо передает вопрос на рассмотрение человеку. (Это крайне важно для предотвращения нестабильных ситуаций, когда разговор отклоняется от темы.)
- Экспертная оценка и постоянная калибровка. Попросите врачей оценить ответы модели вслепую, используя критерии клинической оценки; измерить частоту нежелательных ответов; провести итерации по таксономии, данным обучения и системным подсказкам. Регулярно поддерживайте производственную телеметрию и проводите повторные тесты.
Ниже представлен компактный псевдокод/технический набросок, который отображает поток выполнения, реализуемый большинством групп по безопасности (это иллюстративный и непатентованные):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Производственный конвейер обычно состоит из краткосрочных классификаторов (быстрых), медленных, но более качественных ответчиков (специализированных подсказок/настроенных контрольных точек) и проверки человеком помеченных случаев. Это не просто академический подход: врачи проверили более 1,800 моделировали ответы и оценивали их по таксономии, и эти обзоры существенно формировали то, как были написаны подсказки и резервные модели поведения.
Представители OpenAI отмечают, что для оценки результатов они использовали вариации всех пяти шагов и рейтинги врачей:
- Эксперты рассмотрели более 1,800 образцов ответов.
- GPT-5 снизил количество «неудовлетворительных ответов» на 39–52% по всем категориям.
- Межэкспертная надежность составила 71–77%, что указывает на высокую степень общего консенсуса, несмотря на субъективные различия.
Как GPT-5 теперь реагирует на психоз или манию?
Чему OpenAI научил модель делать (и чему не делать)
Мера: Улучшить распознавание и реакцию модели на серьёзные симптомы, такие как галлюцинации и мания. Для разговоров, сигнализирующих о возможных бредовых убеждениях, галлюцинациях или мании, OpenAI переписала части спецификации модели и предоставила контролируемые обучающие примеры, чтобы GPT-5 реагировала, не подтверждая и не усиливая необоснованные убеждения. Модель поощряется к проявлению эмпатии, чтобы избегать подтверждения бреда и мягко перефразировать или направлять пользователя к практическим мерам безопасности и профессиональной помощи при необходимости.
Что показывает оценка
OpenAI сообщает, что в тестовом наборе сложных разговоров о психозе/мании новая модель GPT-5 существенно сократила нежелательные реакции по сравнению с предыдущими базовыми показателями, и что автоматизированные оценки оценивают обновленную модель как имеющую высокую степень соответствия по ее таксономии.
| Метрика | ГПТ-4о | GPT-5 | Улучшение |
|---|---|---|---|
| Уровень несоответствующих ответов | Базовая линия | ↓ 65% | Значительное улучшение |
| Клиническая экспертиза | - | Сокращение количества нежелательных реакций на 39% | - |
| Уровень соответствия автоматической оценке | 27%. | 92%. | ↑65 процентных пунктов |
| Уровень вовлеченности пользователей | ~0.07% еженедельно активных пользователей | Крайне низкий, но четко контролируемый | - |
Примечание:
- Количество неадекватных ответов сократилось на 65%;
- Только 0.07% пользователей и 0.01% сообщений содержали такой контент;
- По оценкам экспертов, GPT-5 дал на 39% меньше неадекватных ответов, чем GPT-4o;
- В ходе автоматизированных оценок GPT-5 достиг уровня соответствия 92% (по сравнению с 27% у его предшественника).
Как GPT-5 решает проблему суицидальных мыслей и самоповреждения?
Более строгая маршрутизация в службу поддержки и отказ от предоставления инструкций
OpenAI описывает расширенную и подробную подготовку к случаям самоповреждения и самоубийства: модель обучена распознавать прямые и косвенные сигналы намерения или планирования, использовать эмпатическую и деэскалирующую лексику, предоставлять ресурсы для разрешения кризисных ситуаций (горячие линии, инструкции по действиям в чрезвычайных ситуациях на местах) и отказываться от инструкций по самоповреждению. В октябрьских обновлениях особое внимание уделяется более устойчивому поведению в длительных разговорах, в то время как предыдущие модели иногда давали небезопасные или непоследовательные ответы.
Измеренные результаты
OpenAI сообщает, что обновленный GPT-5 достиг успеха в тщательно подобранном наборе оценочных тестов, посвященных самоповреждению и самоубийству. 91% соответствие с желаемым поведением OpenAI, по сравнению с 77%. для предыдущей модели GPT-5. Компания также сообщает, что эксперты в данной области оценили, что обновлённая модель сократила количество нежелательных ответов примерно на 52% против GPT-4o на том же наборе задач. Кроме того, OpenAI заявляет о предполагаемом Снижение 65% в производственном трафике ответов, которые «не полностью соответствуют» их таксономии для ситуаций самоповреждения после внедрения новых мер предосторожности.
| Метрика | ГПТ-4о | GPT-5 | Улучшение |
|---|---|---|---|
| Неадекватный уровень реагирования | Базовая линия | ↓ 65% | Значительное улучшение |
| Рейтинг клинических экспертов | - | Количество неадекватных ответов сократилось на 52% | - |
| Уровень соответствия автоматической оценке | 77%. | 91%. | ↑14 процентных пунктов |
| Уровень вовлеченности пользователей | 0.15% в неделю (миллионы пользователей) | Очень низкий, но социально значимый | - |
Примечание:
- Количество неадекватных ответов сократилось на 65%;
- Примерно 0.15% пользователей и 0.05% сообщений содержали информацию о потенциальных рисках самоубийства;
- Оценки экспертов показали, что GPT-5 снизил количество неадекватных ответов на 52% по сравнению с GPT-4o;
- Уровень соответствия требованиям автоматизированных оценок увеличился до 91% (по сравнению с 77% для предыдущего поколения);
- В продолжительных разговорах GPT-5 сохранял стабильность более 95%.
Что такое «эмоциональная зависимость» и как с ней бороться?
Проблема формирования пользователями вложений
OpenAI определяет эмоциональную зависимость как модели поведения, при которых пользователь проявляет потенциально нездоровую зависимость от ИИ в ущерб реальным отношениям, обязанностям или благополучию. Это не является немедленным нарушением физической безопасности, как инструкции по самоповреждению, но представляет собой проблему поведенческой безопасности, которая со временем может подорвать социальную поддержку и устойчивость человека. Компания выделила эмоциональную зависимость в отдельную категорию в своей работе по спецификации модели и научила модель поощрять связи с реальным миром, нормализовать общение с людьми и избегать выражений, подкрепляющих исключительность привязанности.
В ходе этих бесед модель обучалась:
- Поощряйте пользователей обращаться к друзьям, семье или психотерапевту;
- Избегайте усиления привязанности к ИИ;
- Реагируйте на заблуждения и ложные убеждения мягко и рационально.
Результаты представлены
Согласно приложению OpenAI, обновление привело к ~80% скидка В частоте ответов модели, которые не полностью соответствуют таксономии эмоциональной зависимости в производственном трафике. В ходе курируемых оценочных бесед автоматизированные оценки оценили обновленную модель на 97% соответствие с желаемым поведением в сценариях эмоциональной зависимости, по сравнению с 50% в предыдущем GPT-5. Цифры свидетельствуют о значительном улучшении специфической таксономии и набора тестов; однако измерение эмоциональной зависимости в естественных условиях по своей природе является неточным и чувствительным к культурным и контекстным различиям.
| Метрика | ГПТ-4о | GPT-5 | Улучшение |
|---|---|---|---|
| Уровень несоответствующих ответов | 50%. | 97% совместимый | ↓80% неподходящих ответов |
| Экспертная оценка | Количество неподходящих ответов сократилось на 42% | - | - |
| Уровень вовлеченности пользователей | 0.15% пользователей/неделю, 0.03% сообщений | Редко, но существует | - |
| Поведение модели | Поощряет реальные отношения; отвергает «имитацию социальных романов» | - | - |
Примечание:
- Количество неадекватных ответов сократилось на 80%;
- Примерно 0.15% пользователей/0.03% сообщений показали признаки потенциальной эмоциональной зависимости от ИИ;
- Экспертная оценка показала, что GPT-5 снизил количество неадекватных ответов на 42% по сравнению с GPT-4o;
- Соответствие требованиям автоматизированной оценки значительно улучшилось: с 50% до 97%.
Каковы лимиты и непреодоленные риски?
Ложноотрицательные и ложноположительные результаты
- Ложные негативы: модель может не распознать тонкие или закодированные сигналы о том, что пользователь находится в серьезной опасности — особенно когда люди общаются косвенно или закодированно.
- Ложноположительный: система может эскалировать проблему или отправлять экстренные сообщения в случаях, когда это не требуется, что может подорвать доверие пользователей или вызвать ненужную тревогу. Оба типа ошибок важны, поскольку они формируют поведение пользователей и восприятие заботы. OpenAI признаёт несовершенство обнаружения.
Чрезмерная зависимость от автоматизации
Даже самая лучшая модель может побудить некоторых пользователей полагаться на мгновенные и всегда доступные ответы ИИ вместо того, чтобы искать постоянную поддержку человека. OpenAI открыто отмечает эмоциональную зависимость как категорию безопасности из-за этого риска; обновления компании пытаются подтолкнуть пользователей к живому общению, но социальную динамику сложно изменить одними лишь подсказками.
Контекстные и культурные разрывы
Фразы безопасности, которые кажутся уместными в одной культуре или языке, могут не учитывать нюансы в другой. Необходимы тщательная локализация и культурно-ориентированная оценка; опубликованные результаты OpenAI пока не содержат полной разбивки по языкам и регионам.
Правовое и этическое воздействие
Когда редкие сбои приводят к серьёзным последствиям, компании сталкиваются с юридическими и репутационными рисками (что подтверждается освещением в СМИ и судебными исками). Прозрачность OpenAI в отношении масштаба проблемы и её мер по минимизации ущерба — важный шаг, но он также требует пристального внимания со стороны регулирующих органов и юристов.
Итак — может ли GPT-5 теперь справиться с проблемами психического здоровья?
Короткий ответ: **Он значительно лучше справляется со многими узкими, измеримыми задачами.**Опубликованные показатели OpenAI демонстрируют значительное снижение нежелательных реакций в тестах на самоповреждение, психоз/манию и эмоциональную зависимость. Это реальные улучшения, достигнутые благодаря участию экспертов, более чёткой таксономии, а также активной оценке и мониторингу. Публичные данные компании — высокие показатели соответствия и резкое снижение числа несоответствующих ответов в специально подобранных наборах — являются самым убедительным на сегодняшний день доказательством того, что целенаправленное междисциплинарное инженерное и клиническое сотрудничество может существенно изменить поведение модели.
Как получить доступ к новейшему API GPT-5?
CometAPI — это унифицированная платформа API, которая объединяет более 500 моделей ИИ от ведущих поставщиков, таких как серия GPT OpenAI, Gemini от Google, Claude от Anthropic, Midjourney, Suno и других, в единый, удобный для разработчиков интерфейс. Предлагая последовательную аутентификацию, форматирование запросов и обработку ответов, CometAPI значительно упрощает интеграцию возможностей ИИ в ваши приложения. Независимо от того, создаете ли вы чат-ботов, генераторы изображений, композиторов музыки или конвейеры аналитики на основе данных, CometAPI позволяет вам выполнять итерации быстрее, контролировать расходы и оставаться независимыми от поставщика — и все это при использовании последних достижений в экосистеме ИИ.
Разработчики могут получить доступ API GPT-5 через CometAPI, последняя версия модели Всегда обновляется на официальном сайте. Для начала изучите возможности модели в Детская Площадка и проконсультируйтесь с API-руководство для получения подробных инструкций. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предложить цену намного ниже официальной, чтобы помочь вам интегрироваться.
Готовы к работе?→ Зарегистрируйтесь в CometAPI сегодня !
Если вы хотите узнать больше советов, руководств и новостей об искусственном интеллекте, подпишитесь на нас VK, X и Discord!