Claude Haiku 4.5 เป็นโมเดลภาษาคลาสขนาดเล็กที่ปรับแต่งตามวัตถุประสงค์จาก Anthropic เปิดตัวในช่วงกลางเดือนตุลาคม 2025 วางตำแหน่งเป็นตัวเลือกที่ รวดเร็ว ต้นทุนต่ำ ในไลน์อัป Claude โดยยังคงความสามารถแข็งแกร่งในงานอย่าง การเขียนโค้ด การประสานงานเอเจนต์ และเวิร์กโฟลว์แบบโต้ตอบสำหรับ “การใช้คอมพิวเตอร์” พร้อมรองรับปริมาณงานสูงขึ้นและต้นทุนต่อหน่วยต่ำลงสำหรับการใช้งานระดับองค์กร
คุณสมบัติหลัก
- ความเร็วและความคุ้มค่าด้านต้นทุน: Haiku 4.5 ถูกอธิบายว่ามีความเร็ว มากกว่าสองเท่า ของ Sonnet 4 และมีต้นทุน ประมาณหนึ่งในสาม ของ Sonnet 4 (และถูกกว่า Opus มาก) ทำให้น่าสนใจสำหรับการใช้งานที่ต้องสเกล
- การคิดแบบขยาย: โมเดล Haiku รุ่นแรกที่รองรับ การคิดแบบขยาย (การคิดแบบสรุป/สอดแทรก ปรับงบประมาณการคิดได้) เพื่อการให้เหตุผลหลายขั้นลึกขึ้นพร้อมถ่วงดุลเวลาแฝง
- เครื่องมือและการใช้คอมพิวเตอร์: รองรับเต็มรูปแบบ สำหรับเครื่องมือของ Claude (bash การรันโค้ด ตัวแก้ไขข้อความ การค้นเว็บ และระบบอัตโนมัติสำหรับการใช้คอมพิวเตอร์) ออกแบบมาสำหรับ เวิร์กโฟลว์เชิงเอเจนต์ และสถาปัตยกรรมซับเอเจนต์
- หน้าต่างบริบทขนาดใหญ่: หน้าต่างบริบท 200k โทเคน (มีตัวเลือกบริบท 1M ในโมเดลที่ใหญ่กว่าสำหรับคลาสโมเดลอื่นในสถานะเบต้า)
รายละเอียดทางเทคนิค
- ข้อมูลฝึกและจุดตัด: Haiku 4.5 ถูกฝึกด้วยส่วนผสมของข้อมูลสาธารณะและที่มีไลเซนส์โดยเป็นกรรมสิทธิ์ โดยมี จุดตัดข้อมูลการฝึกประมาณกุมภาพันธ์ 2025
- รองรับ การคิดแบบขยาย (โหมดให้เหตุผลแบบไฮบริด) เพื่อให้โมเดลแลกเวลาแฝงกับการให้เหตุผลที่ลึกขึ้นเมื่อร้องขอ
- หน้าต่างบริบท ณ การเปิดตัวคือ 200,000 โทเคน และโมเดลมีความ ตระหนักรู้บริบท (ติดตามว่ามีการใช้หน้าต่างไปเท่าใด)
- ประสิทธิภาพ/ปริมาณงาน: รายงานจากชุมชนช่วงต้นและการทดสอบของ Anthropic ระบุ OTPS สูงมาก (output tokens/sec) และความเร็วโดยประมาณ ~200+ โทเคน/วินาที ในการทดสอบภายใน/ช่วงแรกบางส่วน — เร็วกว่าหลายโมเดลระดับกลางที่เทียบเคียงกันอย่างมาก
ประสิทธิภาพบนเบนช์มาร์ก
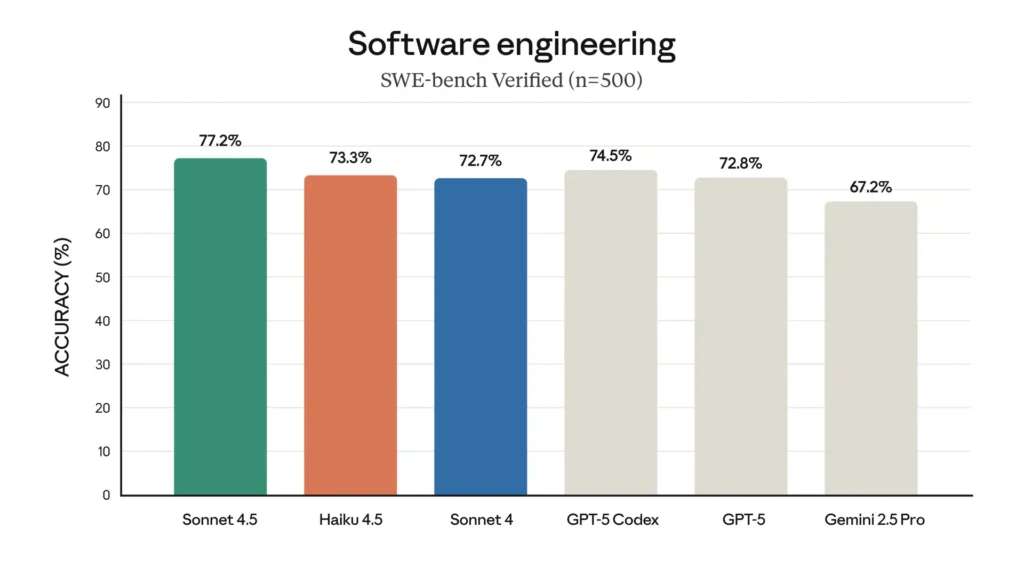
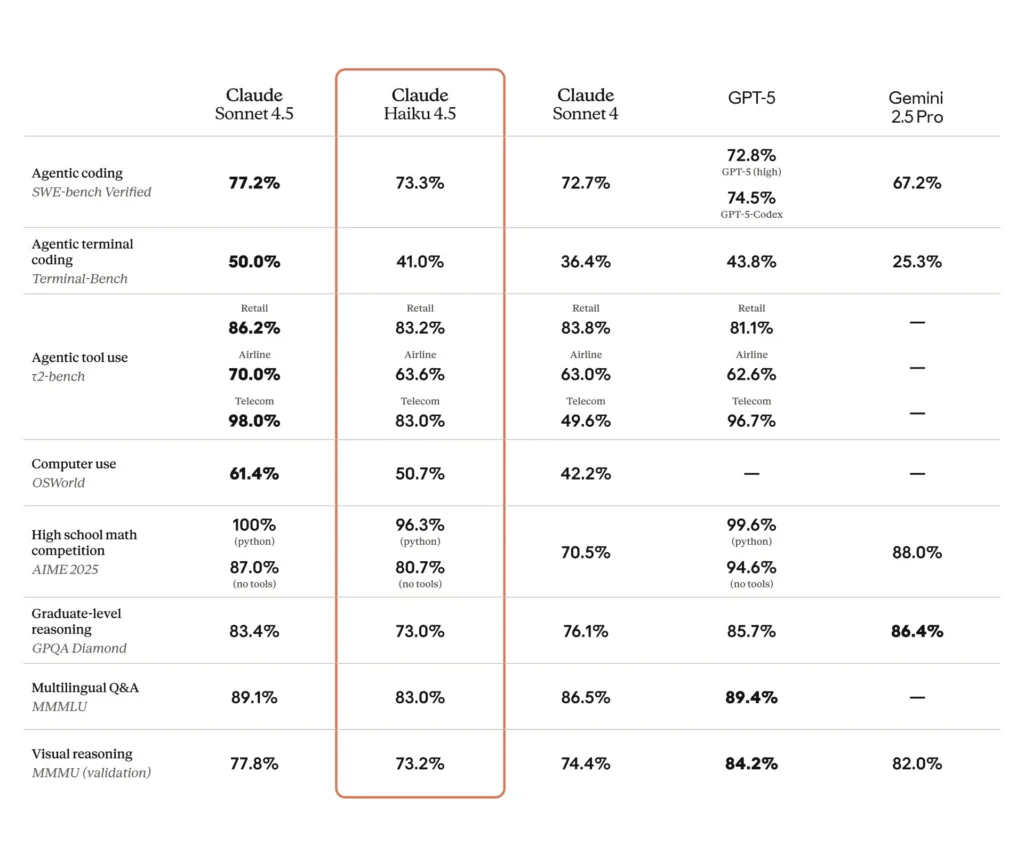
SWE-Bench (การเขียนโค้ด): Haiku 4.5 ได้คะแนน ~73.3% บน SWE-Bench Verified — ผลลัพธ์ที่ Anthropic ชี้ว่าอยู่ในกลุ่มโมเดลเขียนโค้ดที่ดีที่สุดในโลกในคลาสของมัน
การทดสอบเทอร์มินัล/คอมมานด์ไลน์/เครื่องมือ: Anthropic รายงาน ~41% บน Terminal-Bench (เน้นคอมมานด์ไลน์) และผลลัพธ์ที่เทียบเคียงกับ Sonnet 4 และโมเดลแนวหน้าระดับกลางของคู่แข่งหลายตัวบนเบนช์มาร์กการใช้เครื่องมือต่างๆ
การปฏิบัติตามคำสั่งและข้อความสไลด์: ตัวอย่างภายในของ Anthropic ระบุว่า Haiku 4.5 ทำได้ดีกว่าโมเดลก่อนหน้าในบางงานการปฏิบัติตามคำสั่ง (เช่น การสร้างข้อความสไลด์: 65% เทียบกับ 44% สำหรับโมเดลพรีเมียมก่อนหน้านี้ในเบนช์มาร์กของพวกเขา)
งานอัตโนมัติ/เอเจนต์ในโลกจริง: การประเมินจากบุคคลที่สามและผู้ใช้งานระยะแรก รายงาน อัตราความสำเร็จที่แข่งขันได้ ในงาน UI/เอเจนต์อัตโนมัติ (เช่น สไตล์ OSWorld หรือเบนช์มาร์กเอเจนต์ที่รายงานความสำเร็จ ≈50% บนงานอัตโนมัติที่ซับซ้อนในบางการทดสอบ) แสดงให้เห็นถึงประโยชน์ต่อเวิร์กโฟลว์ที่ต้องสเกล แม้ว่ายังมีโหมดความล้มเหลวที่ไม่เล็กน้อย
ข้อจำกัดและหมายเหตุด้านความปลอดภัย
- ไม่ใช่โมเดลแนวหน้า: Anthropic จัดประเภท Haiku 4.5 ว่า ไม่ได้ก้าวหน้าระดับแนวหน้า; โมเดลถูกปรับเพื่อประสิทธิภาพ มากกว่าจะผลักดันขีดสุดของสถานะศิลป์ (Anthropic)
- พฤติกรรมต่อหัวข้ออ่อนไหวเป็นครั้งคราว: ในพรอมป์ททางวิทยาศาสตร์/ความปลอดภัยทางชีวภาพบางกรณี Haiku 4.5 บางครั้งจะตอบกลับเป็น ข้อมูลระดับสูง พร้อมข้อแม้ แทนการปฏิเสธอย่างเข้มงวด; Anthropic ระบุว่าเป็นพื้นที่ที่ยังปรับปรุงต่อเนื่อง
- การคิดแบบขยาย อาจเปลี่ยนพฤติกรรม (บางครั้งเพิ่มความไม่สมมาตรในคำตอบ)
กรณีใช้งานที่แนะนำ
- การเขียนโค้ดแบบเอเจนต์และการประสานงานหลายเอเจนต์: ซับเอเจนต์ที่รวดเร็ว การรีแฟกเตอร์โค้ดแบบวนรอบ การทดสอบอัตโนมัติและการสร้างแพตช์ (เหมาะสม)
- เวิร์กโฟลว์ลูกค้าแบบเรียลไทม์ ปริมาณสูง: แชตผู้ช่วย งานอัตโนมัติภายในที่ต้นทุนต่อคำขอสำคัญ (เหมาะสม)
- เวิร์กโฟลว์ที่มีเครื่องมือและการควบคุมคอมพิวเตอร์: การทำงานอัตโนมัติบน GUI/CLI เวิร์กโฟลว์เอกสาร และเชนเครื่องมือที่ต้องการเวลาแฝงต่ำ (เหมาะสม)
- ไม่แนะนำ (หากไม่มีการควบคุม): บทบาทแบบสแตนด์อโลนที่ต้องการการออกแบบลำดับทางวิทยาศาสตร์ระดับแนวหน้าหรือภารกิจด้านความปลอดภัยทางชีวภาพที่ต้องการความมั่นใจสูง (ควรใช้ความระมัดระวัง)