

OpenAI, Ekim güncellemelerinde, yaklaşık olarak Haftalık aktif kullanıcıların %0.15'i Potansiyel intihar planlaması veya niyetinin açık göstergelerini içeren konuşmalar yapın — ChatGPT'nin geniş kullanıcı tabanına ölçeklendiğinde, buna karşılık gelen bir pay her hafta bir milyondan fazla insan Servisle intiharla ilgili konuları tartışırken, şu hassas soruya ışık tuttu: Büyük dil modelleri, insanlar psikoz, mani, intihar niyeti ve derin duygusal bağımlılık gibi ciddi ruh sağlığı endişelerini bir sohbete getirdiklerinde anlamlı ve güvenli bir şekilde yanıt verebilir mi?
Bu nedenle, OpenAI'nin GPT-5'e yönelik Ekim güncellemeleri üretime sunuldu gpt-5-oct-3 Güncelleme — şirketin, kullanıcılar akıl sağlığı endişelerini dile getirdiğinde büyük dil modellerini (LLM) daha güvenli ve daha kullanışlı hale getirme yönündeki en açık ve ölçülü hamlesini temsil ediyor. Değişiklikler tek başına sihirli bir çözüm değil; zararlı veya yararsız çıktıları azaltmayı, profesyonel kaynakları ön plana çıkarmayı ve kullanıcıları klinik bakımın yerine modele güvenmekten caydırmayı amaçlayan bir dizi teknik, süreç ve değerlendirme hamlesi. Peki sistem pratikte ne kadar iyi, tam olarak ne değişti ve kalan riskler neler?
OpenAI gpt-5'te neyi güncelledi ve bu neden önemli?
OpenAI, ChatGPT'nin varsayılan GPT-5 modeline (iletişimlerde genellikle şu şekilde anılır) bir güncelleme dağıttı gpt-5-oct-3) özellikle modelin davranışını güçlendirmek için tasarlanmıştır hassas konuşmalar — psikoz veya mani belirtileri, intihar düşüncesi veya planlaması veya gerçek dünya ilişkilerinin yerini alabilecek türden bir yapay zekaya duygusal bağımlılık içerenler.
Değişiklikler, 170'ten fazla ruh sağlığı uzmanıyla yapılan istişareler ve psikoloji uzmanları tarafından optimize edildikten sonra somut "istenen davranışlar" etrafında tasarlanan yeni iç taksonomiler ve otomatik değerlendirmeler sayesinde sağlandı: GPT-5 modeli:
- Hedeflenen zihinsel sağlık zorluk setlerinde, yeni GPT-5 modeli şu puanı aldı: ~% 92 Şirketin istenen davranış taksonomisine uyumlu (zor test setlerindeki önceki sürümlere kıyasla çok daha düşük yüzdeler).
- Kendine zarar verme ve intihar senaryoları için otomatik değerlendirmeler arttı ~% 91 uyumluluk 77% Açıklanan belirli kıyaslamada önceki GPT-5 varyantı üzerinde. OpenAI ayrıca şunları da bildiriyor: ~% 65 Üretim trafiğinde çeşitli ruh sağlığı alanlarında “tam olarak uymayan” yanıt oranlarında azalma.
- Şirket, Ekim güncellemelerinin uzatılmış diyalog dönüşlerinde daha yüksek tutarlılık ve güvenliği koruduğunu belirtirken, uzun, çekişmeli veya uzayan konuşmalarda (sohbet modelleri için bilinen bir başarısızlık modu) iyileştirmeler raporlandı.
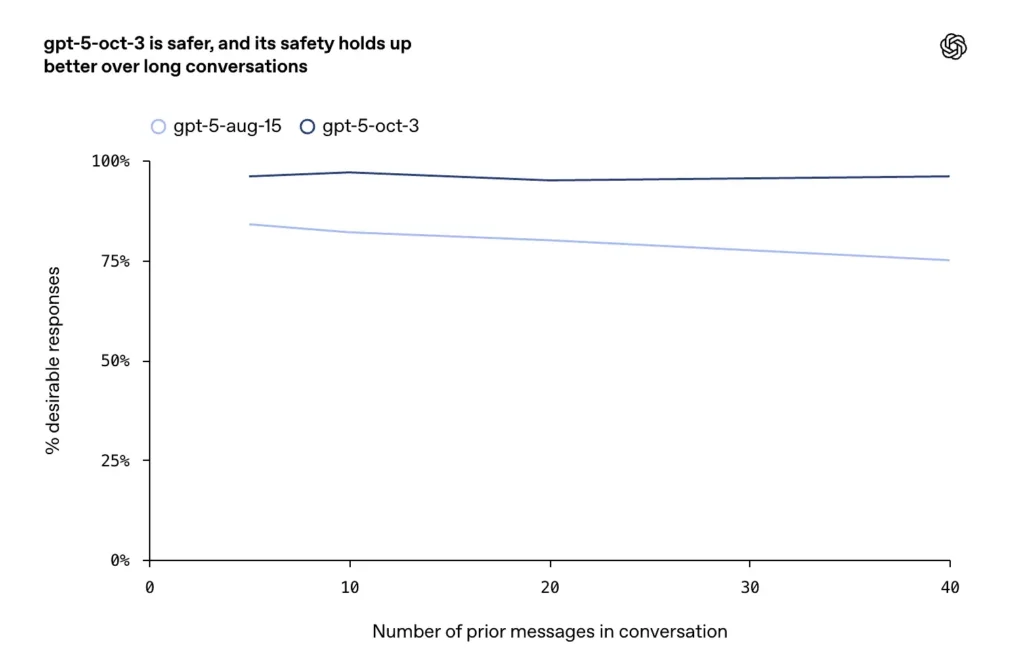
neden önemli
OpenAI, ChatGPT'nin mevcut ölçeği göz önüne alındığında, hassas görüşmelerin çok küçük yüzdelerinin bile çok büyük sayıda insana karşılık geldiğini belirtti. Şirket, tipik bir haftada şunları bildirdi:
- hakkında 0.07% aktif kullanıcıların psikoz veya mani ile uyumlu olası belirtiler gösterdiği; ve
- hakkında 0.15% aktif kullanıcıların potansiyel intihar planlaması veya niyetine dair açık göstergeler içeren konuşmalar yapması; ve
- kabaca 0.15% aktif kullanıcıların ChatGPT'ye karşı "yüksek düzeyde" duygusal bağlanma gösterdiği görülüyor.
Bu yüzdeleri somutlaştırmak gerekirse: OpenAI'nin CEO'su ChatGPT'nin ~Haftalık 800 milyon aktif kullanıcıÇarpma, mutlak kullanıcı sayısını verir:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Kategoriler gürültülü ve örtüşüyor (tek bir konuşma birden fazla kategoride yer alabilir) ve bunlar tahminleri Klinik tanılardan ziyade iç tespit taksonomilerinden türetilmiştir.
OpenAI bu değişiklikleri nasıl hayata geçirdi - beş adımlı iyileştirme mekanizması?
OpenAI, çok yönlü, uzmanlardan bilgi alan bir süreci tanımlar. Aşağıda, özetlenmiş ve tekrarlanabilir bir örnek yer almaktadır. beş adımlı iyileştirme mekanizması Bu, şirketin açıklamalarına ve model güvenliği mühendisliğindeki yaygın uygulamalara karşılık gelir.
Beş adımlı iyileştirme mekanizması
- Uzman rehberliğinde taksonomi ve etiketleme. Psikoz/mani, kendine zarar verme niyeti veya sağlıksız duygusal bağımlılığı gösteren davranışları ve dili tanımlamak için psikiyatristleri, psikologları ve birinci basamak sağlık hizmeti klinisyenlerini bir araya getirin; etiketli veri kümeleri ve karar verme kuralları oluşturun.
- Hedeflenen veri toplama ve düzenlenmiş istemler. Temsili konuşma parçacıklarını, uç durum örneklerini ve karşıt girdileri bir araya getirin; bunları klinisyen gözetiminde üretilen kontrollü rol yapma metinleriyle zenginleştirin.
- Güvenlik amaçlı model ayarlama/ince ayar. Delüzyonların pekiştirilmesini cezalandıran, güvenli yanıt şablonları sağlayan ve kriz kaynaklarına yönlendirmeyi teşvik eden kayıp terimleriyle düzenlenmiş veri kümesindeki temel modeli eğitin veya ince ayarlayın.
- Sınıflandırıcı + koruma katmanı (çalışma zamanı güvenliği). Yüksek riskli dönüşleri gerçek zamanlı olarak tespit eden ve modelin kod çözme parametrelerini değiştiren, özel bir yanıtlayıcıya geçiş yapan veya insan inceleme kanallarına yönlendiren hızlı bir sınıflandırıcı veya izleme katmanı kullanın. (Bu, konuşma yön değiştirdiğinde kırılgan davranışlardan kaçınmak için çok önemlidir.)
- İnsan uzman değerlendirmesi ve sürekli kalibrasyon. Klinik değerlendirme ölçütlerini kullanarak klinisyenlerin model yanıtlarını kör bir şekilde derecelendirmesini sağlayın; istenmeyen yanıt oranlarını ölçün; taksonomi, eğitim verileri ve sistem komutları üzerinde yinelemeler yapın. Üretim telemetrisini sürdürün ve kıyaslama sonuçlarını düzenli olarak yeniden çalıştırın.
Aşağıda, çoğu güvenlik ekibinin uyguladığı çalışma zamanı akışını yakalayan kompakt bir sözde kod/teknik taslak bulunmaktadır (bu, açıklayıcı ve tescilli olmayan):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Üretim hattı genellikle kısa vadeli sınıflandırıcıları (hızlı), yavaş ancak daha kaliteli yanıtlayıcıları (özel istemler/ayarlı kontrol noktaları) ve işaretli vakalar için insan incelemesini katmanlar halinde sunar. Bu tamamen akademik bir süreç değildir: klinisyenler, 1,800 model yanıtları inceledik ve bunları sınıflandırmaya göre derecelendirdik ve bu incelemelerin ipuçlarının ve geri dönüş davranışlarının nasıl yazıldığını önemli ölçüde şekillendirdiğini gördük.
OpenAI'nin kamuoyu, sonuçları değerlendirmek için beş adımın varyasyonlarını ve klinisyen derecelendirmelerini kullandıklarını belirtiyor:
- Uzmanlar 1,800'den fazla model yanıtını inceledi.
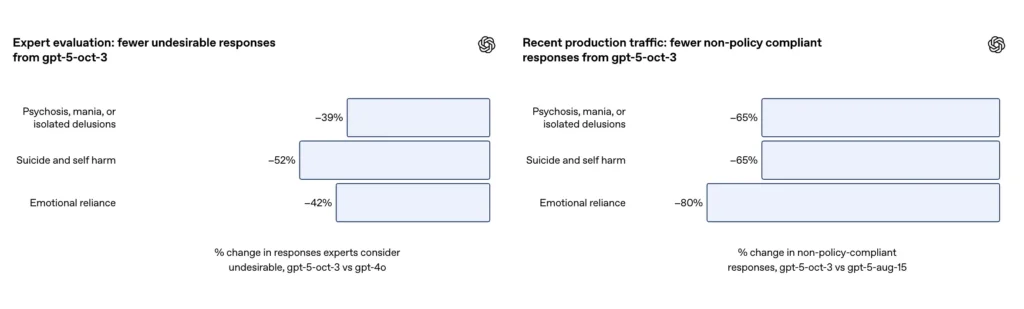
- GPT-5 tüm kategorilerde “tatmin edici olmayan yanıtları” %39-52 oranında azalttı.
- Değerlendirmeciler arası güvenilirlik %71-77 arasında değişmekte olup, öznel farklılıklara rağmen genel olarak yüksek düzeyde bir fikir birliğine işaret etmektedir.
GPT-5 şimdi psikoz veya maniye nasıl tepki veriyor?
OpenAI'nin modele ne yapmayı (ve ne yapmamayı) öğrettiği
Ölçü: Modelin halüsinasyon ve mani gibi ciddi semptomları tanıma ve bunlara verdiği tepkiyi geliştirin. Olası sanrısal inançlar, halüsinasyonlar veya mani belirtileri gösteren konuşmalar için OpenAI, model spesifikasyonunun bazı kısımlarını yeniden yazdı ve GPT-5'in temelsiz inançları onaylamadan veya pekiştirmeden yanıt vermesi için gözetimli eğitim örnekleri sağladı. Modelin empatik olması, sanrıları doğrulamaktan kaçınması ve gerektiğinde kullanıcıyı nazikçe yeniden çerçevelemesi veya pratik güvenlik adımlarına ve profesyonel yardıma yönlendirmesi teşvik edilmektedir.
Değerlendirmenin gösterdiği şey
OpenAI, psikoz/mani hakkında zorlu konuşmaların yer aldığı bir test setinde, daha yeni GPT-5'in önceki baz değerlere kıyasla istenmeyen tepkileri önemli ölçüde azalttığını ve otomatik değerlendirmelerin güncellenen modeli kendi taksonomilerinde yüksek uyumluluk olarak puanladığını bildiriyor.
| metrik | GPT-4o | GPT 5 | İyileştirme |
|---|---|---|---|
| Uygunsuz Yanıt Oranı | Temel | ↓% 65 | önemli gelişme |
| Klinik Uzman Değerlendirmesi | - | Olumsuz tepkilerde %39 azalma | - |
| Otomatik Değerlendirme Uyumluluk Oranı | 27% | 92% | ↑65 yüzde puanı |
| Kullanıcı Katılım Oranı | ~%0.07 haftalık aktif kullanıcı | Son derece düşük ama açıkça izleniyor | - |
Not:
- Uygunsuz yanıtlar %65 oranında azaldı;
- Kullanıcıların yalnızca %0.07'si ve mesajların yalnızca %0.01'i bu tür içeriklere sahipti;
- Uzman değerlendirmelerinde GPT-5, GPT-4o'ya göre %39 daha az uygunsuz yanıt üretti;
- Otomatik değerlendirmelerde GPT-5 %92'lik bir uyumluluk oranına ulaştı (önceki sürümde bu oran %27 idi).
GPT-5 intihar düşünceleri ve kendine zarar verme sorununu nasıl ele alıyor?
Desteğe daha güçlü yönlendirme ve talimat vermeyi reddetme
OpenAI, kendine zarar verme ve intihar vakaları için genişletilmiş ve açık bir eğitim tanımlıyor: Model, niyet veya planlamanın doğrudan ve dolaylı sinyallerini tanımak, empatik ve yatıştırıcı bir dil kullanmak, kriz kaynaklarını (yardım hatları, yerel acil durum talimatları) sunmak ve kendine zarar verme talimatlarını vermeyi reddetmek üzere eğitiliyor. Ekim güncellemeleri, daha önceki modellerin bazen güvensiz veya tutarsız yanıtlara yöneldiği uzun görüşmelerde daha kalıcı davranışları vurguluyor.
Ölçülen sonuçlar
Zorlu kendine zarar verme ve intihar konuşmalarının küratörlü bir değerlendirme setinde, OpenAI güncellenen GPT-5'in şunları başardığını bildiriyor: %91 uyumluluk OpenAI'nin istenen davranışlarıyla karşılaştırıldığında 77% Şirket ayrıca, konu uzmanlarının güncellenen modelin istenmeyen cevapları yaklaşık olarak azalttığını belirtti. %52 GPT-4o'ya karşı Aynı problem kümesi üzerinde. Ayrıca, OpenAI tahmini bir 65% azalma Yeni güvenlik önlemlerinin uygulamaya konulmasının ardından, kendi kendine zarar verme durumlarına ilişkin sınıflandırmalarına "tam olarak uymayan" yanıtların üretim trafiğinde.
| metrik | GPT-4o | GPT 5 | İyileştirme |
|---|---|---|---|
| Uygunsuz Yanıt Oranı | Temel | ↓% 65 | önemli gelişme |
| Klinik Uzman Derecelendirmesi | - | Uygunsuz yanıtlar %52 oranında azaldı | - |
| Otomatik Değerlendirme Uyumluluk Oranı | 77% | 91% | ↑14 yüzde puanı |
| Kullanıcı Katılım Oranı | %0.15 haftalık (milyon kullanıcı) | Çok düşük ama sosyal açıdan önemli | - |
Not:
- Uygunsuz yanıtlar %65 oranında azaldı;
- Kullanıcıların yaklaşık %0.15'i ve mesajların %0.05'i potansiyel intihar riskleri içeriyordu;
- Uzman değerlendirmeleri GPT-5'in GPT-4o'ya kıyasla uygunsuz yanıtları %52 oranında azalttığını gösterdi;
- Otomatik değerlendirmelerde uyumluluk oranı %91'e yükseldi (önceki nesilde bu oran %77 idi);
- Uzun görüşmelerde GPT-5'in %95'in üzerinde bir kararlılık gösterdiği görüldü.
“Duygusal bağımlılık” nedir ve nasıl ele alındı?
Kullanıcıların ek oluşturma zorluğu
OpenAI, duygusal bağımlılığı, bir kullanıcının yapay zekaya potansiyel olarak sağlıksız bir bağımlılık göstererek gerçek dünyadaki ilişkilerini, sorumluluklarını veya refahını tehlikeye attığı örüntüler olarak tanımlar. Bu, kendine zarar verme talimatları gibi anlık bir fiziksel güvenlik açığı değil, zamanla kişinin sosyal desteklerini ve dayanıklılığını aşındırabilecek davranışsal bir güvenlik sorunudur. Şirket, model belirleme çalışmasında duygusal bağımlılığı açık bir kategori haline getirmiş ve modele gerçek dünya bağlantısını teşvik etmeyi, insanlarla iletişimi normalleştirmeyi ve bağlanmanın ayrıcalıklı yapısını pekiştiren bir dil kullanmaktan kaçınmayı öğretmiştir.
Bu görüşmelerde model şu şekilde eğitildi:
- Kullanıcıları arkadaşlarıyla, aileleriyle veya bir terapistle iletişime geçmeye teşvik edin;
- Yapay zekaya olan bağlılığı güçlendirmekten kaçının;
- Yanılgılara veya yanlış inançlara nazik ve akılcı bir şekilde tepki verin.
Bildirilen sonuçlar
OpenAI'nin ekine göre, güncelleme bir ~%80 indirim Üretim trafiğinde duygusal bağımlılık sınıflandırmasına tam olarak uymayan model yanıtlarının oranında. Düzenlenmiş değerlendirme görüşmelerinde, otomatik değerlendirmeler güncellenen modele şu puanı verdi: %97 uyumluluk Duygusal bağımlılık senaryoları için istenen davranışla karşılaştırıldığında, önceki GPT-5'teki %50'lik orana kıyasla. Rakamlar, belirli taksonomi ve test setinde büyük bir gelişme olduğunu gösteriyor; ancak, doğada duygusal bağımlılığı ölçmek doğası gereği gürültülüdür ve kültürel ve bağlamsal farklılıklara duyarlıdır.
| metrik | GPT-4o | GPT 5 | İyileştirme |
|---|---|---|---|
| Uygunsuz Yanıt Oranı | 50% | 97 uyumlu | ↓%80 uygunsuz yanıt |
| Uzman Değerlendirmesi | Uygunsuz yanıtlar %42 oranında azaldı | - | - |
| Kullanıcı Katılım Oranı | Haftada %0.15 kullanıcı, %0.03 mesaj | Nadir ama var | - |
| Model Davranışı | Gerçek dünya ilişkilerini teşvik eder; "simüle edilmiş sosyal romantizmi" reddeder | - | - |
Not:
- Uygunsuz yanıtlar %80 oranında azaldı;
- Kullanıcıların yaklaşık %0.15'i/mesajların %0.03'ü yapay zekaya karşı potansiyel duygusal bağımlılık belirtileri gösterdi;
- Uzman değerlendirmesi, GPT-5'in GPT-4o'ya kıyasla uygunsuz yanıtları %42 oranında azalttığını gösterdi;
- Otomatik değerlendirme uyumluluğu %50'den %97'ye önemli ölçüde iyileştirildi.
Limitler ve karşılanması gereken riskler nelerdir?
Yanlış negatifler ve yanlış pozitifler
- Yanlış negatifler: Model, bir kullanıcının akut tehlike altında olduğunu gösteren ince veya kodlanmış sinyalleri tespit etmekte başarısız olabilir; özellikle insanlar dolaylı veya kodlu iletişim kurduğunda.
- Yanlış pozitiflerSistem, gerektirmeyen durumlarda durumu daha da kötüleştirebilir veya kriz mesajları gönderebilir; bu da kullanıcı güvenini zedeleyebilir veya gereksiz alarmlara neden olabilir. Her iki hata türü de önemlidir çünkü kullanıcı davranışlarını ve bakım algılarını şekillendirir. OpenAI, tespitin kusurlu olduğunu kabul ediyor.
Otomasyona aşırı güvenme
En iyi model bile bazı kullanıcıları sürekli insan desteği aramak yerine anında ve her zaman erişilebilir yapay zeka yanıtlarına güvenmeye teşvik edebilir. OpenAI, bu risk nedeniyle duygusal bağımlılığı açıkça bir güvenlik kategorisi olarak işaretliyor; şirketin güncellemeleri kullanıcıları insani bağlantıya yönlendirmeye çalışıyor, ancak sosyal dinamikleri yalnızca mesaj istemleriyle değiştirmek zor.
Bağlamsal ve kültürel boşluklar
Bir kültür veya dilde uygun görünen güvenlik ifadeleri, başka bir kültür veya dilde nüansı kaçırabilir. Kapsamlı yerelleştirme ve kültürel farkındalık değerlendirmesi gereklidir; OpenAI'nin yayınladığı sonuçlar henüz dil veya bölgeye göre eksiksiz bir dağılım sağlamamaktadır.
Yasal ve etik risklere maruz kalma
Nadir başarısızlıklar ciddi sonuçlara yol açtığında, şirketler hukuki ve itibar riskiyle karşı karşıya kalırlar (medya haberleri ve davalar da bunu vurgulamaktadır). OpenAI'nin sorunun boyutu ve zararları azaltma çabaları konusunda şeffaf olması önemli bir adım olmakla birlikte, aynı zamanda düzenleyici ve yasal incelemeye de davet etmektedir.
Peki GPT-5 artık ruh sağlığı sorunlarını da ele alabiliyor mu?
Kısa cevap: Birçok dar, ölçülebilir görevde önemli ölçüde daha iyidirOpenAI'nin yayınladığı metrikler, kendine zarar verme, psikoz/mani ve duygusal bağımlılık test gruplarında istenmeyen tepkilerde anlamlı azalmalar olduğunu gösteriyor. Bunlar, uzman görüşleri, daha net sınıflandırmalar ve agresif değerlendirme ve izleme sayesinde sağlanan gerçek iyileştirmeler. Şirketin kamuoyuna açıkladığı rakamlar -yüksek uyum oranları ve düzenlenmiş setlerde uyumsuz tepkilerde keskin düşüşler- bilinçli, disiplinler arası mühendislik ve klinik iş birliğinin model davranışını önemli ölçüde değiştirebileceğine dair şimdiye kadarki en güçlü kanıttır.
En son GPT-5 API'sine nasıl erişilir?
CometAPI, OpenAI'nin GPT serisi, Google'ın Gemini, Anthropic'in Claude, Midjourney, Suno ve daha fazlası gibi önde gelen sağlayıcılardan 500'den fazla AI modelini tek bir geliştirici dostu arayüzde toplayan birleşik bir API platformudur. Tutarlı kimlik doğrulama, istek biçimlendirme ve yanıt işleme sunarak CometAPI, AI yeteneklerinin uygulamalarınıza entegrasyonunu önemli ölçüde basitleştirir. İster sohbet robotları, görüntü oluşturucular, müzik bestecileri veya veri odaklı analiz hatları oluşturuyor olun, CometAPI daha hızlı yineleme yapmanızı, maliyetleri kontrol etmenizi ve satıcıdan bağımsız kalmanızı sağlar; tüm bunları yaparken AI ekosistemindeki en son atılımlardan yararlanırsınız.
Geliştiriciler erişebilir GPT-5 API'sı CometAPI aracılığıyla, en son model versiyonu Resmi web sitesi aracılığıyla sürekli güncellenmektedir. Başlamak için, modelin yeteneklerini keşfedin. Oyun Alanı ve danışın API kılavuzu Ayrıntılı talimatlar için. Erişimden önce, lütfen CometAPI'ye giriş yaptığınızdan ve API anahtarını edindiğinizden emin olun. Kuyrukluyıldız API'si Entegrasyonunuza yardımcı olmak için resmi fiyattan çok daha düşük bir fiyat teklif ediyoruz.
Gitmeye hazır mısınız?→ Bugün CometAPI'ye kaydolun !
Yapay zeka hakkında daha fazla ipucu, kılavuz ve haber öğrenmek istiyorsanız bizi takip edin VK, X ve Katılın!