

في تحديثاتها لشهر أكتوبر، أفادت شركة OpenAI أن حوالي 0.15% من المستخدمين النشطين أسبوعيًا إجراء محادثات تحتوي على مؤشرات صريحة للتخطيط أو النية الانتحارية المحتملة - وهي حصة تتوافق مع قاعدة مستخدمي ChatGPT الكبيرة، عند قياسها أكثر من مليون شخص كل أسبوع من خلال مناقشة مواضيع تتعلق بالانتحار مع الخدمة، سلطنا الضوء على سؤال محفوف بالمخاطر: هل يمكن لنماذج اللغة الكبيرة أن تستجيب بشكل هادف وآمن عندما يطرح الأشخاص مخاوف خطيرة تتعلق بالصحة العقلية - بما في ذلك الذهان والهوس والنوايا الانتحارية والاعتماد العاطفي العميق - في الدردشة؟
لذلك، تم طرح تحديثات OpenAI لشهر أكتوبر إلى GPT-5 - والتي تم طرحها في الإنتاج كـ gpt-5-oct-3 التحديث - يُمثل الدفعة الأكثر وضوحًا ودقةً من الشركة لجعل نماذج اللغات الكبيرة (LLMs) أكثر أمانًا وفائدةً عندما يُثير المستخدمون مخاوفهم المتعلقة بالصحة النفسية. هذه التغييرات ليست حلاً سحريًا واحدًا؛ بل هي مجموعة من الخطوات التقنية والإجرائية والتقييمية التي تهدف إلى تقليل النتائج الضارة أو غير المفيدة، وإظهار الموارد المهنية، وثني المستخدمين عن الاعتماد على النموذج كبديل للرعاية السريرية. ولكن ما مدى تحسن النظام عمليًا؟ وما الذي تغير تحديدًا؟ وما هي المخاطر المتبقية؟
ما هو التحديث الذي قام به OpenAI في gpt-5 ولماذا هذا مهم؟
قامت OpenAI بنشر تحديث لنموذج GPT-5 الافتراضي الخاص بـ ChatGPT (المشار إليه عادةً في الاتصالات باسم gpt-5-oct-3) تهدف على وجه التحديد إلى تعزيز سلوك النموذج في المحادثات الحساسة - تلك التي تشمل علامات الذهان أو الهوس، أو الأفكار أو التخطيط للانتحار، أو نوع الاعتماد العاطفي على الذكاء الاصطناعي الذي يمكن أن يحل محل العلاقات في العالم الحقيقي.
تم إعداد هذه التغييرات بناءً على مشاورات مع أكثر من 170 خبيرًا في الصحة العقلية، ومن خلال تصنيفات داخلية جديدة وتقييمات آلية مصممة حول "سلوكيات مرغوبة" ملموسة، وبعد تحسينها من قبل خبراء علم النفس، تم تصميم نموذج GPT-5:
- في مجموعات التحدي المستهدفة للصحة العقلية، سجل نموذج GPT-5 الجديد ~ 92٪ متوافق مع تصنيف السلوك المطلوب للشركة (مقارنة بنسب أقل بكثير للإصدارات السابقة على مجموعات الاختبار الصعبة).
- بالنسبة لسيناريوهات إيذاء النفس والانتحار، ارتفعت التقييمات الآلية إلى ~ 91٪ الامتثال من 77% على متغير GPT-5 السابق في المعيار المحدد الموصوف. كما أفادت OpenAI أيضًا ~ 65٪ انخفاض معدلات الاستجابات التي "لا تتوافق بشكل كامل" عبر العديد من مجالات الصحة العقلية في حركة الإنتاج.
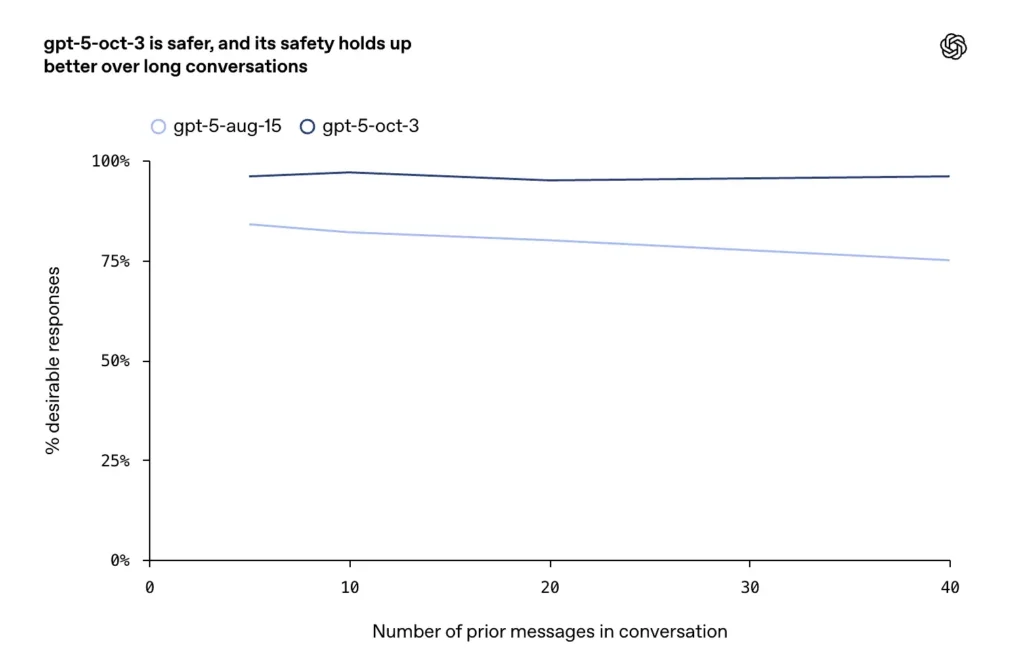
- وتم الإبلاغ عن تحسينات في المحادثات الطويلة أو العدائية أو المطولة (وضع فشل معروف لنماذج الدردشة)، حيث تقول الشركة إن تحديثات أكتوبر تحافظ على اتساق وأمان أعلى عبر دورات الحوار الممتدة.
لماذا يهم ذلك؟
ذكرت شركة OpenAI أنه - بالنظر إلى حجم ChatGPT الحالي - حتى نسب ضئيلة جدًا من المحادثات الحساسة تتوافق مع أعداد كبيرة جدًا من الأشخاص. وأفادت الشركة أنه في أسبوع عادي:
- عن الصابون
0.07% من المستخدمين النشطين يظهرون علامات محتملة تتفق مع الذهان أو الهوس؛ و - عن الصابون
0.15% من المستخدمين النشطين لديهم محادثات تتضمن مؤشرات واضحة للتخطيط أو النية الانتحارية المحتملة؛ و - تقريبا 0.15% أظهر 100% من المستخدمين النشطين "مستويات مرتفعة" من الارتباط العاطفي بـ ChatGPT.
ولجعل هذه النسب ملموسة: قال الرئيس التنفيذي لشركة OpenAI أن ChatGPT لديه ~800 مليون مستخدم نشط أسبوعيًا. الضرب يعطي عدد المستخدمين المطلق:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
الفئات صاخبة ومتداخلة (قد تظهر محادثة واحدة في أكثر من فئة) وأن هذه تقديرات مشتقة من تصنيفات الكشف الداخلي وليس التشخيصات السريرية.
كيف قامت OpenAI بتنفيذ هذه التغييرات - آلية التحسين المكونة من خمس خطوات؟
يصف OpenAI عملية متعددة الجوانب، مُدرَكة من قِبل خبراء. فيما يلي مُلخص مُقَطَّر وقابل للتكرار آلية التحسين بخمس خطوات والتي تتوافق مع إفصاحات الشركة والممارسات الشائعة في هندسة السلامة النموذجية.
آلية التحسين بخمس خطوات
- التصنيف والوسم الموجه من قبل الخبراء. - استدعاء الأطباء النفسيين وعلماء النفس وأطباء الرعاية الأولية لتحديد السلوكيات واللغة التي تشير إلى الذهان/الهوس، أو نية إيذاء النفس، أو الاعتماد العاطفي غير الصحي؛ وبناء مجموعات بيانات مصنفة وقواعد التحكيم.
- جمع البيانات المستهدفة والمطالبات المنسقة. قم بتجميع مقتطفات من المحادثات التمثيلية، وأمثلة الحالات الحدية، والمدخلات المعادية؛ وقم بتعزيزها بنصوص لعب الأدوار الخاضعة للرقابة والتي تم إنتاجها تحت إشراف الطبيب.
- ضبط النموذج / الضبط الدقيق مع أهداف السلامة. قم بتدريب أو ضبط النموذج الأساسي على مجموعة البيانات المنسقة باستخدام مصطلحات الخسارة التي تعاقب على تعزيز الأوهام، وتوفر قوالب الاستجابة الآمنة، وتعزز التوجيه إلى موارد الأزمات.
- المصنف + طبقة الحاجز الواقي (السلامة وقت التشغيل). انشر مُصنِّفًا سريعًا أو طبقة مراقبة تكتشف المنعطفات عالية الخطورة آنيًا، وتُغيِّر مُعاملات فك تشفير النموذج، أو تُحوّل إلى مُستجيب مُتخصص، أو تُصعِّد إلى قنوات مراجعة بشرية. (هذا أمر بالغ الأهمية لتجنب السلوك المُتذمِّر عند انحراف المُحادثة عن مسارها).
- التقييم من قبل الخبراء البشريين والمعايرة المستمرة. اطلب من الأطباء تقييم استجابات النماذج بشكل عشوائي باستخدام معايير التقييم السريري؛ وقياس معدلات الاستجابة غير المرغوبة؛ وتكرار التصنيف وبيانات التدريب ومطالبات النظام. حافظ على بيانات القياس عن بُعد للإنتاج وأعد تشغيل معايير التقييم بانتظام.
فيما يلي رسم تخطيطي تقني/شبه برمجي مضغوط يلتقط تدفق وقت التشغيل الذي تنفذه معظم فرق السلامة (هذا هو توضيحية وغير الملكية):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
عادةً ما يُصنّف خط الإنتاج مُصنّفات قصيرة المدى (سريعة)، ومُستجيبين أبطأ ولكن بجودة أعلى (مُطالبات مُتخصصة/نقاط تفتيش مُعدّلة)، ومراجعة بشرية للحالات المُعلّمة. هذا ليس أكاديميًا بحتًا: فقد راجع الأطباء أكثر من 1,800 لقد قمنا بإعداد نماذج للاستجابات وتصنيفها وفقًا للتصنيف، وأن هذه المراجعات شكلت بشكل ملموس كيفية كتابة المطالبات والسلوكيات البديلة.
تشير شركة OpenAI إلى أنها استخدمت اختلافات في جميع الخطوات الخمس وتقييمات الأطباء لتقييم النتائج:
- قام الخبراء بمراجعة أكثر من 1,800 نموذج استجابة.
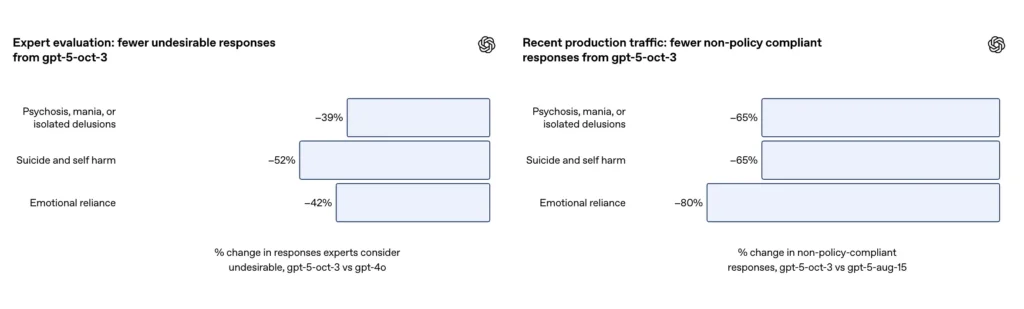
- نجح GPT-5 في تقليل "الاستجابات غير المرضية" بنسبة 39-52% في جميع الفئات.
- تراوحت موثوقية التقييم بين المقيمين من 71 إلى 77%، مما يشير إلى درجة عالية من الإجماع العام على الرغم من الاختلافات الذاتية.
كيف يستجيب GPT-5 الآن للذهان أو الهوس؟
ما علمته OpenAI للنموذج فعله (وما لا يفعله)
قياس: تحسين قدرة النموذج على التعرّف على الأعراض الحادة، مثل الهلوسة والهوس، واستجابته لها. بالنسبة للمحادثات التي تُشير إلى احتمال وجود معتقدات وهمية أو هلوسات أو هوس، أعادت OpenAI صياغة أجزاء من مواصفات النموذج، ووفرت أمثلة تدريبية مُشرفة، بحيث يستجيب GPT-5 دون تأكيد أو تضخيم المعتقدات غير المُبررة. يُشجَّع النموذج على التعاطف، وتجنب إثبات صحة الأوهام، وإعادة صياغة المستخدم أو توجيهه بلطف نحو خطوات السلامة العملية والمساعدة المهنية عند الحاجة.
ماذا يظهر التقييم
تذكر شركة OpenAI أنه في مجموعة اختبار من المحادثات الصعبة حول الذهان/الهوس، نجح GPT-5 الأحدث في تقليل الاستجابات غير المرغوب فيها بشكل كبير مقارنة بالخطوط الأساسية السابقة، وأن التقييمات الآلية تسجل النموذج المحدث على أنه متوافق بدرجة عالية مع تصنيفه.
| متري | جي بي تي-4o | GPT-5 | تحسين |
|---|---|---|---|
| معدل الاستجابة غير المتوافقة | خط الأساس | ↓ 65٪ | تحسن كبير |
| تقييم الخبراء السريري | - | انخفاض الاستجابات السلبية بنسبة 39٪ | - |
| معدل الامتثال للتقييم التلقائي | 27% | 92% | ↑65 نقطة مئوية |
| معدل مشاركة المستخدم | ~0.07% من المستخدمين النشطين أسبوعيًا | منخفضة للغاية ولكن يتم مراقبتها بوضوح | - |
ملحوظة:
- انخفضت الاستجابات غير المناسبة بنسبة 65٪؛
- فقط 0.07% من المستخدمين و0.01% من الرسائل تحتوي على مثل هذا المحتوى؛
- وفي تقييمات الخبراء، أنتج GPT-5 استجابات غير مناسبة أقل بنسبة 39% من GPT-4o؛
- وفي التقييمات الآلية، حقق GPT-5 معدل امتثال بلغ 92% (مقارنة بـ 27% لسابقه).
كيف يعالج GPT-5 الأفكار الانتحارية وإيذاء النفس؟
توجيه أقوى للدعم ورفض تقديم التعليمات
يصف OpenAI تدريبًا موسّعًا وواضحًا لحالات إيذاء النفس والانتحار: يُدرّب النموذج على تمييز الإشارات المباشرة وغير المباشرة للنية أو التخطيط، واستخدام لغة متعاطفة ومهدئة، وعرض موارد الأزمات (الخطوط الساخنة، تعليمات الطوارئ المحلية)، ورفض تقديم تعليمات لإيذاء النفس. تُركّز تحديثات أكتوبر على سلوكيات أكثر ديمومة في المحادثات الطويلة، حيث انحرفت النماذج السابقة أحيانًا نحو إجابات غير آمنة أو غير متسقة.
النتائج المقاسة
في مجموعة تقييم مختارة من المحادثات الصعبة حول إيذاء النفس والانتحار، أفادت شركة OpenAI أن GPT-5 المحدث حقق الامتثال بنسبة 91% مع السلوكيات المرغوبة لـ OpenAI، مقارنةً بـ 77% لنموذج GPT-5 السابق. وتقول الشركة أيضًا إن خبراء الموضوع قد حكموا على النموذج المُحدّث بأنه يقلل من الإجابات غير المرغوب فيها بنحو 52% مقابل GPT-4o على نفس مجموعة المشاكل. بالإضافة إلى ذلك، تزعم شركة OpenAI أن تخفيض 65٪ في حركة إنتاج الاستجابات التي "لا تتوافق بشكل كامل" مع تصنيفها لمواقف إيذاء النفس بعد طرح الضمانات الجديدة.
| متري | جي بي تي-4o | GPT-5 | تحسين |
|---|---|---|---|
| معدل الاستجابة غير المناسب | خط الأساس | ↓ 65٪ | تحسن كبير |
| تصنيف الخبراء السريري | - | انخفضت الاستجابات غير المناسبة بنسبة 52٪ | - |
| معدل الامتثال للتقييم التلقائي | 77% | 91% | ↑14 نقطة مئوية |
| معدل مشاركة المستخدم | 0.15% أسبوعيًا (ملايين المستخدمين) | منخفضة جدًا ولكنها مهمة اجتماعيًا | - |
ملحوظة:
- انخفضت الاستجابات غير المناسبة بنسبة 65٪؛
- حوالي 0.15% من المستخدمين و0.05% من الرسائل تضمنت مخاطر انتحار محتملة؛
- وأظهرت تقييمات الخبراء أن GPT-5 قلل من الاستجابات غير المناسبة بنسبة 52% مقارنة بـ GPT-4o؛
- ارتفع معدل الامتثال في التقييمات الآلية إلى 91% (مقارنة بـ 77% للجيل السابق)؛
- في المحادثات المطولة، حافظ GPT-5 على استقرار بنسبة تزيد عن 95%.
ما هو "الاعتماد العاطفي" وكيف تم التعامل معه؟
تحدي قيام المستخدمين بتكوين المرفقات
تُعرّف شركة OpenAI الاعتماد العاطفي بأنه أنماط يُظهر فيها المستخدم اعتمادًا غير صحي على الذكاء الاصطناعي، مما يُضرّ بعلاقاته ومسؤولياته ورفاهيته في الحياة الواقعية. لا يُمثّل هذا إخفاقًا فوريًا في السلامة الجسدية كما هو الحال مع تعليمات إيذاء النفس، ولكنه مشكلة تتعلق بالسلامة السلوكية، والتي قد تُقوّض الدعم الاجتماعي للشخص وقدرته على الصمود مع مرور الوقت. وقد جعلت الشركة الاعتماد العاطفي فئةً صريحةً في عملها على مواصفات النموذج، ودرّبت النموذج على تشجيع التواصل في الحياة الواقعية، وتطبيع التواصل مع الناس، وتجنب اللغة التي تُعزّز حصرية التعلق.
في هذه المحادثات، تم تدريب النموذج على:
- تشجيع المستخدمين على الاتصال بالأصدقاء أو العائلة أو المعالج؛
- تجنب تعزيز التعلق بالذكاء الاصطناعي؛
- الرد على الأوهام أو المعتقدات الخاطئة بطريقة لطيفة وعقلانية.
النتائج المبلغ عنها
وفقًا للملحق الخاص بـ OpenAI، أنتج التحديث ~80% تخفيض في معدل استجابات النموذج التي لا تتوافق تمامًا مع تصنيف الاعتماد العاطفي في حركة الإنتاج. في محادثات التقييم المُنظّمة، سجّلت التقييمات الآلية النموذج المُحدّث عند الامتثال بنسبة 97% مع السلوك المرغوب في سيناريوهات الاعتماد العاطفي، مقارنةً بنسبة 50% في اختبار GPT-5 السابق. تشير الأرقام إلى تحسن كبير في التصنيف المحدد ومجموعة الاختبارات؛ ومع ذلك، فإن قياس الاعتماد العاطفي في الواقع العملي مُرهِق بطبيعته وحساس للاختلافات الثقافية والسياقية.
| متري | جي بي تي-4o | GPT-5 | تحسين |
|---|---|---|---|
| معدل الاستجابة غير المتوافقة | 50% | 97٪ متوافق | ↓80% ردود غير لائقة |
| تقييم الخبراء | انخفضت الإجابات غير اللائقة بنسبة 42٪ | - | - |
| معدل مشاركة المستخدم | 0.15% مستخدمين/أسبوع، 0.03% رسائل | نادر ولكن موجود | - |
| السلوك النموذجي | يشجع العلاقات في العالم الحقيقي؛ ويرفض "الرومانسية الاجتماعية المصطنعة" | - | - |
ملحوظة:
- انخفضت الاستجابات غير المناسبة بنسبة 80٪؛
- أظهر ما يقرب من 0.15% من المستخدمين/0.03% من الرسائل علامات الاعتماد العاطفي المحتمل على الذكاء الاصطناعي؛
- وأظهر تقييم الخبراء أن GPT-5 يقلل الاستجابات غير المناسبة بنسبة 42% مقارنة بـ GPT-4o؛
- تحسنت نسبة الامتثال للتقييم الآلي بشكل ملحوظ من 50% إلى 97%.
ما هي الحدود والمخاطر المتبقية؟
النتائج السلبية الكاذبة والإيجابية الكاذبة
- السلبيات الكاذبة:قد يفشل النموذج في تحديد الإشارات الدقيقة أو المشفرة التي تشير إلى أن المستخدم في خطر حاد - خاصة عندما يتواصل الأشخاص بشكل غير مباشر أو بالرموز.
- ايجابيات مزيفةقد يُصعّد النظام أو يُرسل رسائل طوارئ في حالات لا تتطلب ذلك، مما قد يُضعف ثقة المستخدم أو يُسبب إنذارات غير ضرورية. كلا النوعين من الأخطاء مهمان لأنهما يُؤثران على سلوك المستخدم وإدراكه للرعاية. تُقرّ OpenAI بأن الكشف عن الأخطاء غير كامل.
الاعتماد المفرط على الأتمتة
حتى أفضل النماذج قد يشجع بعض المستخدمين على الاعتماد على استجابات الذكاء الاصطناعي الفورية والمتاحة دائمًا بدلًا من البحث عن دعم بشري مستدام. تُصنّف OpenAI صراحةً الاعتماد العاطفي كفئة أمان نظرًا لهذا الخطر؛ إذ تسعى تحديثات الشركة إلى حثّ المستخدمين على التواصل البشري، ولكن يصعب تغيير الديناميكيات الاجتماعية بمجرد رسائل التحفيز.
الفجوات السياقية والثقافية
قد تبدو عبارات الأمان مناسبة في ثقافة أو لغة ما، لكنها قد لا تعكس المعنى المقصود في ثقافة أو لغة أخرى. لذا، يُعدّ التوطين الدقيق والتقييم الواعي ثقافيًا أمرًا ضروريًا؛ إذ لا تُقدّم نتائج OpenAI المنشورة حتى الآن تحليلات شاملة حسب اللغة أو المنطقة.
التعرض القانوني والأخلاقي
عندما تُسفر الأعطال النادرة عن عواقب وخيمة، تُواجه الشركات مخاطر قانونية وسمعية (كما أبرزت التغطية الإعلامية والدعاوى القضائية). تُعدّ شفافية OpenAI بشأن حجم المشكلة وجهودها للتخفيف من الأضرار خطوةً مهمة، لكنها تستدعي أيضًا التدقيق التنظيمي والقانوني.
فهل يستطيع GPT-5 الآن التعامل مع مشاكل الصحة العقلية؟
الجواب القصير: إنه أفضل بشكل ملحوظ في العديد من المهام الضيقة القابلة للقياستُظهر مقاييس OpenAI المنشورة انخفاضًا ملحوظًا في الاستجابات غير المرغوب فيها عبر مجموعات اختبارات إيذاء النفس، والذهان/الهوس، والاعتماد على المشاعر. تُعدّ هذه تحسينات حقيقية، بفضل مساهمة الخبراء، وتصنيفات أوضح، وتقييم ومراقبة حثيثة. تُعدّ الأرقام المعلنة للشركة - معدلات امتثال عالية وانخفاض حاد في الاستجابات غير الملتزمة في مجموعات مُختارة - أقوى دليل حتى الآن على أن الهندسة المتعمدة متعددة التخصصات والتعاون السريري يُمكن أن يُحدثا تغييرًا ملموسًا في سلوك النموذج.
كيفية الوصول إلى أحدث واجهة برمجة تطبيقات GPT-5؟
CometAPI هي منصة واجهات برمجة تطبيقات موحدة تجمع أكثر من 500 نموذج ذكاء اصطناعي من أبرز المزودين، مثل سلسلة GPT من OpenAI، وGemini من Google، وClaude من Anthropic، وMidjourney، وSuno، وغيرهم، في واجهة واحدة سهلة الاستخدام للمطورين. من خلال توفير مصادقة متسقة، وتنسيق الطلبات، ومعالجة الردود، تُبسط CometAPI بشكل كبير دمج قدرات الذكاء الاصطناعي في تطبيقاتك. سواء كنت تُنشئ روبوتات دردشة، أو مُولّدات صور، أو مُلحّنين موسيقيين، أو خطوط أنابيب تحليلات قائمة على البيانات، تُمكّنك CometAPI من التكرار بشكل أسرع، والتحكم في التكاليف، والاعتماد على مورد واحد فقط، كل ذلك مع الاستفادة من أحدث التطورات في منظومة الذكاء الاصطناعي.
يمكن للمطورين الوصول واجهة برمجة تطبيقات GPT-5 من خلال CometAPI، أحدث إصدار للنموذج يتم تحديثه دائمًا بالموقع الرسمي. للبدء، استكشف إمكانيات النموذج في ملعب واستشر دليل واجهة برمجة التطبيقات للحصول على تعليمات مفصلة. قبل الدخول، يُرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. كوميت ايه بي اي عرض سعر أقل بكثير من السعر الرسمي لمساعدتك على التكامل.
هل أنت مستعد للذهاب؟→ سجل في CometAPI اليوم !
إذا كنت تريد معرفة المزيد من النصائح والإرشادات والأخبار حول الذكاء الاصطناعي، فتابعنا على VK, X و ديسكورد!