

17 جون، 2025 کو، شنگھائی میں مقیم AI لیڈر MiniMax (جسے Xiyu ٹیکنالوجی بھی کہا جاتا ہے) نے باضابطہ طور پر MiniMax-M1 (اس کے بعد "M1") - دنیا کا پہلا اوپن ویٹ، بڑے پیمانے پر، ہائبرڈ توجہ دلانے والا ماڈل جاری کیا۔ ایک اختراعی لائٹننگ اٹینشن میکانزم کے ساتھ مکسچر آف ایکسپرٹس (MoE) فن تعمیر کا امتزاج کرتے ہوئے، M1 بے مثال لاگت کی تاثیر کو برقرار رکھتے ہوئے پیداواری صلاحیت پر مبنی کاموں میں صنعت کی سرکردہ کارکردگی کو حاصل کرتا ہے۔ اس گہرائی والے مضمون میں، ہم دریافت کرتے ہیں کہ M1 کیا ہے، یہ کیسے کام کرتا ہے، اس کی وضاحتی خصوصیات، اور ماڈل تک رسائی اور استعمال کرنے کے بارے میں عملی رہنمائی۔
MiniMax-M1 کیا ہے؟
MiniMax-M1 توسیع پذیر، موثر توجہ کے طریقہ کار میں MiniMaxAI کی تحقیق کے اختتام کی نمائندگی کرتا ہے۔ MiniMax-Text-01 فاؤنڈیشن پر تعمیر کرتے ہوئے، M1 تکرار بجلی کی توجہ کو MoE فریم ورک کے ساتھ مربوط کرتا ہے تاکہ تربیت اور اندازہ دونوں کے دوران بے مثال کارکردگی حاصل کی جا سکے۔ یہ امتزاج ماڈل کو اعلیٰ کارکردگی کو برقرار رکھنے کے قابل بناتا ہے یہاں تک کہ انتہائی طویل ترتیب پر کارروائی کرتے ہوئے بھی - وسیع کوڈ بیسز، قانونی دستاویزات، یا سائنسی لٹریچر پر مشتمل کاموں کے لیے ایک اہم ضرورت۔
بنیادی فن تعمیر اور پیرامیٹرائزیشن
اپنے بنیادی طور پر، MiniMax-M1 ایک ہائبرڈ MoE سسٹم کا فائدہ اٹھاتا ہے جو ماہر ذیلی نیٹ ورکس کے سب سیٹ کے ذریعے ٹوکن کو متحرک طور پر روٹ کرتا ہے۔ جبکہ ماڈل میں مجموعی طور پر 456 بلین پیرامیٹرز شامل ہیں، وسائل کے استعمال کو بہتر بناتے ہوئے ہر ٹوکن کے لیے صرف 45.9 بلین کو چالو کیا جاتا ہے۔ یہ ڈیزائن پہلے سے MoE کے نفاذ سے متاثر ہوتا ہے لیکن تقسیم شدہ تخمینہ کے دوران GPUs کے درمیان مواصلات کو کم سے کم کرنے کے لیے روٹنگ منطق کو بہتر کرتا ہے۔
بجلی کی توجہ اور طویل سیاق و سباق کی حمایت
MiniMax-M1 کی ایک واضح خصوصیت اس کا بجلی پر توجہ دینے کا طریقہ کار ہے، جو لمبے سلسلے کے لیے خود پر توجہ دینے کے کمپیوٹیشنل بوجھ کو کافی حد تک کم کرتا ہے۔ مقامی اور عالمی کرنل کے امتزاج کے ذریعے توجہ کے میٹرکس کا تخمینہ لگا کر، ماڈل 75K ٹوکن سیکونسز پر کارروائی کرتے وقت روایتی ٹرانسفارمرز کے مقابلے میں FLOPs کو 100% تک کم کرتا ہے۔ یہ کارکردگی نہ صرف اندازہ کو تیز کرتی ہے بلکہ ہارڈ ویئر کی ممنوعہ ضروریات کے بغیر XNUMX لاکھ ٹوکن تک کی سیاق و سباق کی کھڑکیوں کو سنبھالنے کا دروازہ بھی کھولتی ہے۔
MiniMax-M1 کمپیوٹ کی کارکردگی کیسے حاصل کرتا ہے؟
MiniMax-M1 کی کارکردگی دو بنیادی اختراعات سے حاصل ہوتی ہے: اس کا ہائبرڈ مکسچر آف ایکسپرٹس فن تعمیر اور ناول CISPO ریانفورسمنٹ لرننگ الگورتھم جو تربیت کے دوران استعمال ہوتا ہے۔ ایک ساتھ، یہ عناصر ٹریننگ کے وقت اور تخمینہ لاگت دونوں کو کم کرتے ہیں، تیز تجربہ اور تعیناتی کو قابل بناتے ہیں۔
ہائبرڈ مکسچر آف ایکسپرٹس روٹنگ
ایم او ای جزو 32 ماہر ذیلی نیٹ ورکس کو ملازمت دیتا ہے، ہر ایک استدلال کے مختلف پہلوؤں یا ڈومین سے متعلق مخصوص کاموں میں مہارت رکھتا ہے۔ اندازہ لگانے کے دوران، ایک سیکھا ہوا گیٹنگ میکانزم متحرک طور پر ہر ٹوکن کے لیے انتہائی متعلقہ ماہرین کا انتخاب کرتا ہے، صرف ان ذیلی نیٹ ورکس کو فعال کرتا ہے جن کو ان پٹ پر کارروائی کرنے کی ضرورت ہوتی ہے۔ یہ سلیکٹیو ایکٹیویشن بے کار کمپیوٹیشنز کو کم کرتا ہے اور میموری بینڈوڈتھ کے مطالبات کو کم کرتا ہے، جس سے MiniMax-M1 کو یک سنگی ٹرانسفارمر ماڈلز کے مقابلے لاگت کی کارکردگی میں کافی برتری حاصل ہوتی ہے۔
CISPO: ایک نیا کمک سیکھنے کا الگورتھم
ٹریننگ کی کارکردگی کو مزید تقویت دینے کے لیے، MiniMaxAI نے CISPO (جزوی اوور رائیڈز کے ساتھ کلپڈ امپورٹنس سیمپلنگ) تیار کیا، ایک RL الگورتھم جو ٹوکن لیول ویٹ اپڈیٹس کو اہمیت کے نمونے پر مبنی کلپنگ سے بدل دیتا ہے۔ CISPO بڑے پیمانے پر RL سیٹ اپ میں عام وزن کے دھماکے کے مسائل کو کم کرتا ہے، کنورجنسی کو تیز کرتا ہے، اور متنوع بینچ مارکس میں مستحکم پالیسی میں بہتری کو یقینی بناتا ہے۔ نتیجتاً، 1 H512 GPUs پر MiniMax-M800 کی مکمل RL ٹریننگ صرف تین ہفتوں میں مکمل ہو جاتی ہے، جس کی لاگت تقریباً $534,700 ہے — جو کہ GPT-4 ٹریننگ کے مقابلے کے لیے رپورٹ کی گئی لاگت کا ایک حصہ ہے۔
MiniMax-M1 کے کارکردگی کے معیارات کیا ہیں؟
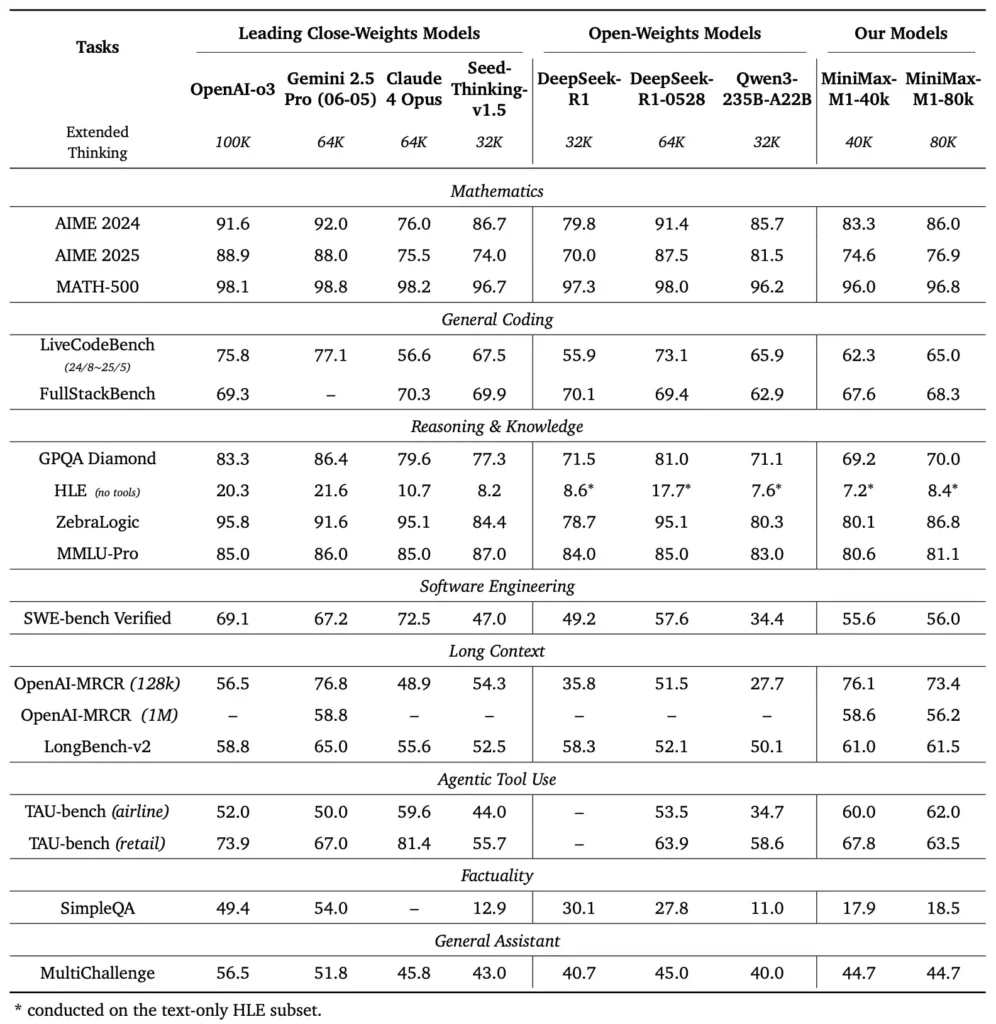
MiniMax-M1 مختلف قسم کے معیاری اور ڈومین کے مخصوص معیارات پر سبقت لے جاتا ہے، طویل سیاق و سباق کے استدلال، ریاضی کے مسائل حل کرنے، اور کوڈ جنریشن کو سنبھالنے میں اپنی صلاحیت کا مظاہرہ کرتا ہے۔
طویل سیاق و سباق کے استدلال کے کام
دستاویز کو سمجھنے کے وسیع ٹیسٹوں میں، MiniMax-M1 1,000,000 ٹوکنز تک سیاق و سباق کی ونڈوز پر کارروائی کرتا ہے، زیادہ سے زیادہ سیاق و سباق کی لمبائی میں آٹھ کے عنصر سے DeepSeek-R1 کو پیچھے چھوڑتا ہے اور 100K ٹوکنز کے سلسلے کے لیے کمپیوٹ کی ضروریات کو آدھا کر دیتا ہے۔ NarrativeQA توسیعی سیاق و سباق کی تشخیص جیسے معیارات پر، ماڈل جدید ترین فہم سکور حاصل کرتا ہے، جس کی وجہ مقامی اور عالمی دونوں انحصاروں کو مؤثر طریقے سے حاصل کرنے کی اس کی بجلی کی توجہ کی صلاحیت ہے۔
سافٹ ویئر انجینئرنگ اور ٹول کا استعمال
MiniMax-M1 کو خاص طور پر بڑے پیمانے پر RL کا استعمال کرتے ہوئے سینڈ باکسڈ سافٹ ویئر انجینئرنگ ماحول پر تربیت دی گئی تھی، جس سے یہ قابل ذکر درستگی کے ساتھ کوڈ تیار کرنے اور ڈیبگ کرنے کے قابل بنا۔ ہیومن ایول اور ایم بی پی پی جیسے کوڈنگ بینچ مارکس میں، ماڈل Qwen3-235B اور DeepSeek-R1 کے مقابلے یا اس سے زیادہ پاس ریٹ حاصل کرتا ہے، خاص طور پر ملٹی فائل کوڈ بیسز اور کاموں میں جن میں کراس ریفرنسنگ لانگ کوڈ سیگمنٹس کی ضرورت ہوتی ہے۔ مزید برآں، MiniMaxAI کے ابتدائی مظاہرے CI/CD پائپ لائنز بنانے سے لے کر آٹو ڈاکومینٹیشن ورک فلوز تک، ڈویلپر ٹولز کے ساتھ انضمام کی ماڈل کی صلاحیت کو ظاہر کرتے ہیں۔
ڈویلپرز MiniMax-M1 تک کیسے رسائی حاصل کر سکتے ہیں؟
بڑے پیمانے پر اپنانے کو فروغ دینے کے لیے، MiniMaxAI نے MiniMax-M1 کو کھلے وزن کے ماڈل کے طور پر آزادانہ طور پر دستیاب کرایا ہے۔ ڈویلپرز پہلے سے تربیت یافتہ چیک پوائنٹس، ماڈل وزن، اور انفرنس کوڈ تک سرکاری GitHub ریپوزٹری کے ذریعے رسائی حاصل کر سکتے ہیں۔
GitHub پر اوپن ویٹ ریلیز
MiniMaxAI نے GitHub پر اجازت دینے والے اوپن سورس لائسنس کے تحت MiniMax-M1 کی ماڈل فائلیں اور اس کے ساتھ اسکرپٹس شائع کیں۔ دلچسپی رکھنے والے صارفین https://github.com/MiniMax-AI/MiniMax-M1 پر ریپوزٹری کا کلون کر سکتے ہیں، جو 40K اور 80K ٹوکن بجٹ دونوں قسموں کے لیے چیک پوائنٹس کی میزبانی کرتا ہے، نیز عام ML فریم ورکس جیسے PyTorch اور TensorFlow کے لیے انضمام کی مثالیں۔
API اینڈ پوائنٹس اور کلاؤڈ انضمام
مقامی تعیناتی کے علاوہ، MiniMaxAI نے مینیجڈ API خدمات پیش کرنے کے لیے بڑے کلاؤڈ فراہم کنندگان کے ساتھ شراکت داری کی ہے۔ ان شراکتوں کے ذریعے، ڈیولپرز MiniMax-M1 کو RESTful endpoints کے ذریعے کال کر سکتے ہیں، SDKs کے ساتھ Python، JavaScript اور Java کے لیے دستیاب ہیں۔ APIs میں سیاق و سباق کی لمبائی، ماہر روٹنگ تھریشولڈز، اور ٹوکن بجٹ کے لیے قابل ترتیب پیرامیٹرز شامل ہیں، جو صارفین کو ریئل ٹائم میں کمپیوٹ کی کھپت کی نگرانی کرتے ہوئے اپنے استعمال کے معاملات کے مطابق کارکردگی کے مطابق کرنے کی اجازت دیتے ہیں۔
حقیقی ایپلی کیشنز میں MiniMax-M1 کو کیسے ضم اور استعمال کیا جائے؟
MiniMax-M1 کی صلاحیتوں کا فائدہ اٹھانے کے لیے اس کے API پیٹرنز، طویل سیاق و سباق کے اشارے کے لیے بہترین طریقوں، اور ٹول آرکیسٹریشن کے لیے حکمت عملیوں کو سمجھنے کی ضرورت ہے۔
بنیادی API کے استعمال کی مثال
ایک عام API کال میں JSON پے لوڈ بھیجنا شامل ہوتا ہے جس میں ان پٹ ٹیکسٹ اور اختیاری کنفیگریشن اوور رائیڈ ہوتے ہیں۔ مثال کے طور پر:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
جواب جنریٹڈ ٹیکسٹ، ٹوکن کے استعمال کے اعدادوشمار، اور روٹنگ لاگز کے ساتھ ایک منظم JSON واپس کرتا ہے، جس سے ماہر ایکٹیویشنز کی نفیس نگرانی کو قابل بنایا جا سکتا ہے۔
ٹول کا استعمال اور MiniMax ایجنٹ
بنیادی ماڈل کے ساتھ ساتھ، MiniMaxAI نے MiniMax Agent متعارف کرایا ہے، ایک بیٹا ایجنٹ فریم ورک جو بیرونی ٹولز کو کال کر سکتا ہے — کوڈ پر عمل درآمد کرنے والے ماحول سے لے کر ویب سکریپر تک — ہڈ کے نیچے۔ ڈویلپرز ایک ایجنٹ سیشن کو شروع کر سکتے ہیں جو ماڈل استدلال کو ٹول کی درخواست کے ساتھ زنجیروں میں ڈال سکتا ہے، مثال کے طور پر، ریئل ٹائم ڈیٹا کو بازیافت کرنے، کمپیوٹنگ انجام دینے، یا ڈیٹا بیس کو اپ ڈیٹ کرنے کے لیے۔ یہ ایجنٹ پیراڈائم اینڈ ٹو اینڈ ایپلیکیشن ڈیولپمنٹ کو آسان بناتا ہے، جس سے MiniMax-M1 پیچیدہ ورک فلو میں آرکیسٹریٹر کے طور پر کام کر سکتا ہے۔
بہترین طریقے اور نقصانات
- طویل سیاق و سباق کے لیے فوری انجینئرنگ: ان پٹ کو مربوط حصوں میں توڑیں، سمریوں کو منطقی وقفوں پر سرایت کریں، اور ماڈل فوکس کو برقرار رکھنے کے لیے "خلاصہ پھر دلیل" کی حکمت عملیوں کا استعمال کریں۔
- کمپیوٹ بمقابلہ کارکردگی ٹریڈ آف: تاخیر سے متعلق حساس ایپلی کیشنز کے لیے کم ماہر کی حد یا کم سوچ والے بجٹ (مثلاً 40K ویرینٹ) کے ساتھ تجربہ کریں۔
- مانیٹرنگ اور گورننس: ماہرین کے استعمال کا آڈٹ کرنے اور خاص طور پر پیداواری ماحول میں لاگت کے بجٹ کی تعمیل کو یقینی بنانے کے لیے روٹنگ لاگز اور ٹوکن کے اعدادوشمار کا استعمال کریں۔
ان رہنما خطوط پر عمل کر کے، ڈویلپرز MiniMax-M1 کی طاقتوں کو بروئے کار لا سکتے ہیں—وسیع سیاق و سباق سے نمٹنے اور موثر استدلال—جبکہ بڑے پیمانے پر ماڈل کی تعیناتیوں سے وابستہ خطرات کو کم کرتے ہیں۔
آپ MiniMax-M1 کیسے استعمال کرتے ہیں؟
ایک بار انسٹال ہونے کے بعد، M1 کو سادہ Python اسکرپٹس یا انٹرایکٹو نوٹ بک کے ذریعے طلب کیا جا سکتا ہے۔
ایک بنیادی انفرنس اسکرپٹ کیسا لگتا ہے؟
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
یہ نمونہ 40 k-بجٹ کی مختلف حالتوں کا مطالبہ کرتا ہے۔ میں تبادلہ "MiniMax-AI/MiniMax-M1-80k" مکمل 80 k استدلال بجٹ کو کھولتا ہے ()۔
آپ الٹرا لانگ سیاق و سباق کو کیسے ہینڈل کرتے ہیں؟
عام بفر سائز سے زیادہ ان پٹ کے لیے، M1 اسٹریمنگ ٹوکنائزیشن کو سپورٹ کرتا ہے۔ استعمال کریں۔ stream=True ٹوکنائزر میں جھنڈا لگائیں تاکہ ٹوکن کو ٹکڑوں میں فیڈ کیا جا سکے، اور ملین ٹوکن سیکوئنسز پر کارکردگی کو برقرار رکھنے کے لیے چیک پوائنٹ دوبارہ شروع کرنے کا اندازہ لگائیں۔
آپ M1 کو کیسے ٹھیک یا موافق بنا سکتے ہیں؟
اگرچہ بیس چیک پوائنٹس زیادہ تر کاموں کے لیے کافی ہیں، محققین ریپوزٹری میں شامل CISPO کوڈ کا استعمال کرتے ہوئے RL فائن ٹیوننگ کا اطلاق کر سکتے ہیں۔ کوڈ کی درستگی سے لے کر سیمنٹک فیڈیلیٹی تک کے حسب ضرورت انعامی افعال کی فراہمی کے ذریعے- پریکٹیشنرز M1 کو ڈومین کے مخصوص ورک فلو کے مطابق ڈھال سکتے ہیں۔
نتیجہ
MiniMax-M1 طویل سیاق و سباق کی زبان کی تفہیم اور استدلال کی حدود کو آگے بڑھاتے ہوئے ایک اہم AI ماڈل کے طور پر نمایاں ہے۔ اپنے ہائبرڈ MoE فن تعمیر، بجلی پر توجہ دینے کے طریقہ کار، اور CISPO کی حمایت یافتہ تربیتی نظام کے ساتھ، ماڈل قانونی تجزیہ سے لے کر سافٹ ویئر انجینئرنگ تک کے کاموں پر اعلیٰ کارکردگی پیش کرتا ہے، یہ سب کچھ ڈرامائی طور پر کمپیوٹیشنل اخراجات کو کم کرتا ہے۔ اس کے اوپن ویٹ ریلیز اور کلاؤڈ API کی پیشکشوں کی بدولت، MiniMax-M1 ڈیولپرز اور تنظیموں کے وسیع میدان عمل کے لیے قابل رسائی ہے جو اگلی نسل کی AI سے چلنے والی ایپلی کیشنز بنانے کے خواہشمند ہیں۔ چونکہ AI کمیونٹی بڑے سیاق و سباق کے ماڈلز کی صلاحیت کو تلاش کرنا جاری رکھے ہوئے ہے، MiniMax-M1 کی اختراعات پوری صنعت میں مستقبل کی تحقیق اور مصنوعات کی ترقی کو متاثر کرنے کے لیے تیار ہیں۔
شروع
CometAPI ایک متحد REST انٹرفیس فراہم کرتا ہے جو کہ سیکڑوں AI ماڈلز کو جمع کرتا ہے — بشمول ChatGPT فیملی — ایک مستقل اختتامی نقطہ کے تحت، بلٹ ان API-کی مینجمنٹ، استعمال کوٹہ، اور بلنگ ڈیش بورڈز کے ساتھ۔ متعدد وینڈر یو آر ایل اور اسناد کو جگانے کے بجائے۔
شروع کرنے کے لیے، میں ماڈلز کی صلاحیتوں کو دریافت کریں۔ کھیل کے میدان اور مشورہ کریں API گائیڈ تفصیلی ہدایات کے لیے۔ رسائی کرنے سے پہلے، براہ کرم یقینی بنائیں کہ آپ نے CometAPI میں لاگ ان کیا ہے اور API کلید حاصل کر لی ہے۔
تازہ ترین انٹیگریشن MiniMax‑M1 API جلد ہی CometAPI پر ظاہر ہو گا، اس لیے دیکھتے رہیں!جب تک ہم MiniMax‑M1 ماڈل اپ لوڈ کو حتمی شکل دے رہے ہیں، ہمارے دوسرے ماڈلز کو دیکھیں ماڈلز کا صفحہ یا میں ان کی کوشش کریں AI کھیل کا میدان. CometAPI میں MiniMax کا تازہ ترین ماڈل ہیں۔ Minimax ABAB7-Preview API اور MiniMax Video-01 API رجوع کریں:
