

Vào ngày 17 tháng 2025 năm 1, công ty AI hàng đầu tại Thượng Hải MiniMax (còn được gọi là Xiyu Technology) đã chính thức phát hành MiniMax-M1 (sau đây gọi là “M1”)—mô hình lý luận chú ý lai, quy mô lớn, có trọng lượng mở đầu tiên trên thế giới. Kết hợp kiến trúc Hỗn hợp chuyên gia (MoE) với cơ chế Lightning Attention sáng tạo, M1 đạt được hiệu suất hàng đầu trong ngành trong các tác vụ hướng đến năng suất, sánh ngang với các hệ thống nguồn đóng hàng đầu trong khi vẫn duy trì hiệu quả về chi phí vô song. Trong bài viết chuyên sâu này, chúng tôi sẽ khám phá MXNUMX là gì, cách thức hoạt động, các tính năng xác định và hướng dẫn thực tế về cách truy cập và sử dụng mô hình.
MiniMax-M1 là gì?
MiniMax-M1 đại diện cho đỉnh cao của nghiên cứu của MiniMaxAI về các cơ chế chú ý có thể mở rộng và hiệu quả. Dựa trên nền tảng MiniMax-Text-01, lần lặp M1 tích hợp sự chú ý chớp nhoáng với một khuôn khổ MoE để đạt được hiệu quả chưa từng có trong cả quá trình đào tạo và suy luận. Sự kết hợp này cho phép mô hình duy trì hiệu suất cao ngay cả khi xử lý các chuỗi cực dài — một yêu cầu chính đối với các tác vụ liên quan đến cơ sở dữ liệu mã, tài liệu pháp lý hoặc tài liệu khoa học mở rộng.
Kiến trúc cốt lõi và tham số hóa
Về cốt lõi, MiniMax-M1 tận dụng hệ thống MoE lai định tuyến động các mã thông báo thông qua một tập hợp con các mạng con chuyên gia. Trong khi mô hình bao gồm tổng cộng 456 tỷ tham số, chỉ có 45.9 tỷ được kích hoạt cho mỗi mã thông báo, tối ưu hóa việc sử dụng tài nguyên. Thiết kế này lấy cảm hứng từ các triển khai MoE trước đó nhưng tinh chỉnh logic định tuyến để giảm thiểu chi phí truyền thông giữa các GPU trong quá trình suy luận phân tán.
Sự chú ý chớp nhoáng và hỗ trợ ngữ cảnh dài
Một tính năng xác định của MiniMax-M1 là cơ chế chú ý chớp nhoáng, giúp giảm đáng kể gánh nặng tính toán của sự chú ý tự thân đối với các chuỗi dài. Bằng cách xấp xỉ các ma trận chú ý thông qua sự kết hợp của các hạt nhân cục bộ và toàn cục, mô hình cắt giảm FLOP tới 75% so với các máy biến áp truyền thống khi xử lý 100K chuỗi mã thông báo. Hiệu quả này không chỉ tăng tốc suy luận mà còn mở ra cánh cửa để xử lý các cửa sổ ngữ cảnh lên tới một triệu mã thông báo mà không cần yêu cầu phần cứng quá mức.
MiniMax-M1 đạt được hiệu quả tính toán như thế nào?
Hiệu quả tăng lên của MiniMax-M1 bắt nguồn từ hai cải tiến chính: kiến trúc Mixture-of-Experts lai và thuật toán học tăng cường CISPO mới được sử dụng trong quá trình đào tạo. Cùng nhau, các yếu tố này làm giảm cả thời gian đào tạo và chi phí suy luận, cho phép thử nghiệm và triển khai nhanh chóng.
Lộ trình hỗn hợp chuyên gia lai
Thành phần MoE sử dụng 32 mạng con chuyên gia, mỗi mạng chuyên về các khía cạnh khác nhau của lý luận hoặc các nhiệm vụ cụ thể theo miền. Trong quá trình suy luận, một cơ chế gating đã học sẽ chọn động các chuyên gia có liên quan nhất cho mỗi mã thông báo, chỉ kích hoạt những mạng con cần thiết để xử lý đầu vào. Kích hoạt có chọn lọc này cắt giảm các phép tính dư thừa và giảm nhu cầu về băng thông bộ nhớ, mang lại cho MiniMax-M1 lợi thế đáng kể về hiệu quả chi phí so với các mô hình máy biến áp đơn khối.
CISPO: Một thuật toán học tăng cường mới
Để tăng cường hiệu quả đào tạo hơn nữa, MiniMaxAI đã phát triển CISPO (Clipped Importance Sampling with Partial Overrides), một thuật toán RL thay thế các bản cập nhật trọng số cấp mã thông báo bằng cắt dựa trên lấy mẫu quan trọng. CISPO giảm thiểu các vấn đề bùng nổ trọng số thường gặp trong các thiết lập RL quy mô lớn, đẩy nhanh quá trình hội tụ và đảm bảo cải thiện chính sách ổn định trên nhiều chuẩn mực khác nhau. Do đó, toàn bộ quá trình đào tạo RL của MiniMax-M1 trên 512 GPU H800 chỉ hoàn thành trong ba tuần, với chi phí khoảng 534,700 đô la — chỉ bằng một phần nhỏ chi phí được báo cáo cho các lần chạy đào tạo GPT-4 tương đương.
Tiêu chuẩn hiệu suất của MiniMax-M1 là gì?
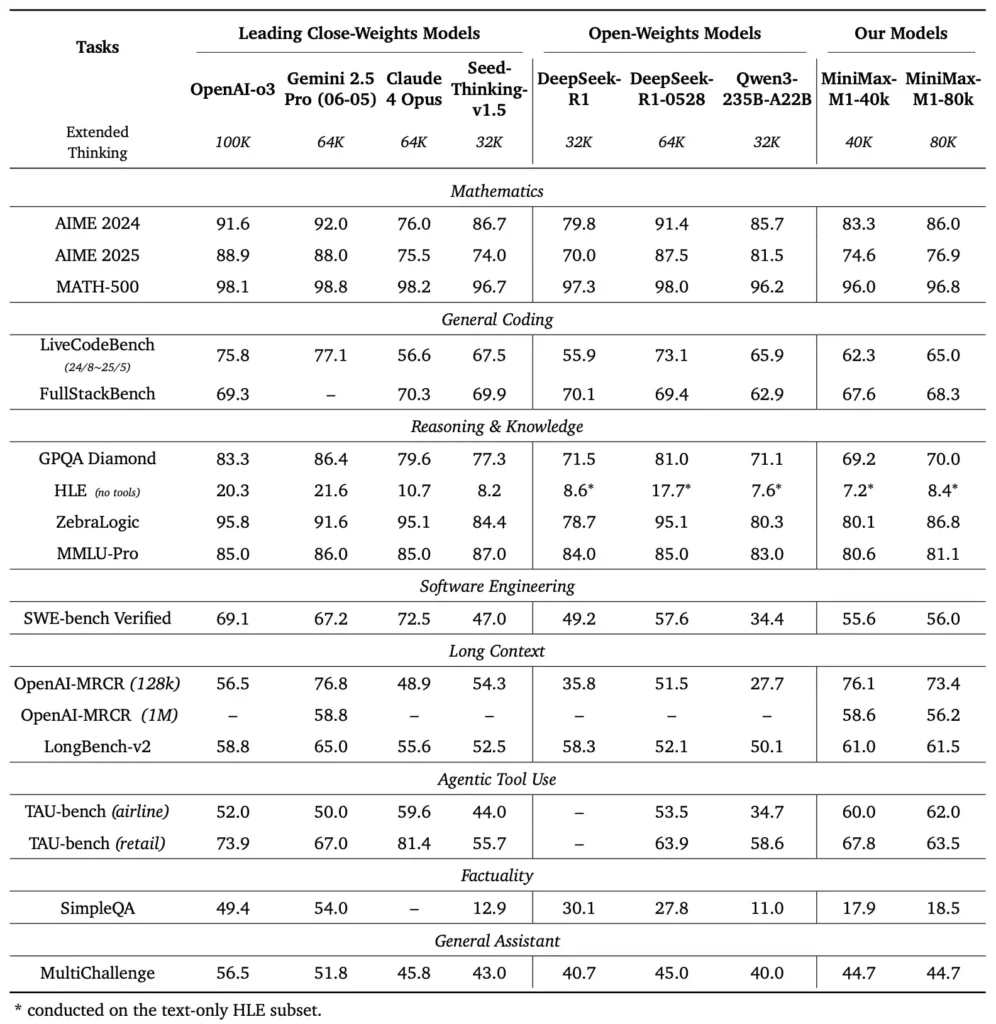
MiniMax-M1 vượt trội trên nhiều tiêu chuẩn chuẩn mực và tiêu chuẩn chuyên biệt, chứng minh khả năng xử lý lý luận ngữ cảnh dài, giải quyết vấn đề toán học và tạo mã.
Nhiệm vụ suy luận ngữ cảnh dài
Trong các bài kiểm tra hiểu tài liệu mở rộng, MiniMax-M1 xử lý các cửa sổ ngữ cảnh lên đến 1,000,000 mã thông báo, vượt trội hơn DeepSeek-R1 gấp tám lần về độ dài ngữ cảnh tối đa và giảm một nửa yêu cầu tính toán cho các chuỗi 100 mã thông báo. Trên các điểm chuẩn như đánh giá ngữ cảnh mở rộng NarrativeQA, mô hình đạt được điểm hiểu hiện đại, nhờ khả năng chú ý nhanh chóng của nó trong việc nắm bắt hiệu quả cả các phụ thuộc cục bộ và toàn cục.
Kỹ thuật phần mềm và sử dụng công cụ
MiniMax-M1 được đào tạo cụ thể trên các môi trường kỹ thuật phần mềm hộp cát sử dụng RL quy mô lớn, cho phép nó tạo và gỡ lỗi mã với độ chính xác đáng kinh ngạc. Trong các chuẩn mực mã hóa như HumanEval và MBPP, mô hình đạt được tỷ lệ vượt qua tương đương hoặc vượt quá Qwen3-235B và DeepSeek-R1, đặc biệt là trong các cơ sở mã nhiều tệp và các tác vụ yêu cầu tham chiếu chéo các đoạn mã dài. Hơn nữa, các bản trình diễn ban đầu của MiniMaxAI cho thấy khả năng tích hợp của mô hình với các công cụ dành cho nhà phát triển, từ việc tạo các đường ống CI/CD đến các quy trình làm việc tự động ghi chép tài liệu.
Các nhà phát triển có thể truy cập MiniMax-M1 bằng cách nào?
Để thúc đẩy việc áp dụng rộng rãi, MiniMaxAI đã cung cấp miễn phí MiniMax-M1 dưới dạng mô hình trọng số mở. Các nhà phát triển có thể truy cập các điểm kiểm tra được đào tạo trước, trọng số mô hình và mã suy luận thông qua kho lưu trữ GitHub chính thức.
Bản phát hành open-weight trên GitHub
MiniMaxAI đã xuất bản các tệp mô hình MiniMax-M1 và các tập lệnh đi kèm theo giấy phép nguồn mở cho phép trên GitHub. Người dùng quan tâm có thể sao chép kho lưu trữ tại https://github.com/MiniMax-AI/MiniMax-M1, nơi lưu trữ các điểm kiểm tra cho cả hai biến thể ngân sách mã thông báo 40K và 80K, cũng như các ví dụ tích hợp cho các khuôn khổ ML phổ biến như PyTorch và TensorFlow.
Điểm cuối API và tích hợp đám mây
Ngoài việc triển khai cục bộ, MiniMaxAI đã hợp tác với các nhà cung cấp dịch vụ đám mây lớn để cung cấp các dịch vụ API được quản lý. Thông qua các quan hệ đối tác này, các nhà phát triển có thể gọi MiniMax-M1 qua các điểm cuối RESTful, với SDK có sẵn cho Python, JavaScript và Java. Các API bao gồm các tham số có thể định cấu hình cho độ dài ngữ cảnh, ngưỡng định tuyến chuyên gia và ngân sách mã thông báo, cho phép người dùng tùy chỉnh hiệu suất theo các trường hợp sử dụng của họ trong khi theo dõi mức tiêu thụ điện toán theo thời gian thực.
Làm thế nào để tích hợp và sử dụng MiniMax-M1 trong các ứng dụng thực tế?
Để tận dụng các khả năng của MiniMax-M1, bạn cần hiểu các mẫu API, các biện pháp tốt nhất cho lời nhắc ngữ cảnh dài và các chiến lược để phối hợp công cụ.
Ví dụ sử dụng API cơ bản
Một lệnh gọi API thông thường bao gồm việc gửi một tải trọng JSON chứa văn bản đầu vào và các ghi đè cấu hình tùy chọn. Ví dụ:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Phản hồi trả về JSON có cấu trúc với văn bản được tạo, số liệu thống kê sử dụng mã thông báo và nhật ký định tuyến, cho phép theo dõi chi tiết các kích hoạt của chuyên gia.
Sử dụng công cụ và MiniMax Agent
Bên cạnh mô hình cốt lõi, MiniMaxAI đã giới thiệu MiniMax Agent, một khuôn khổ tác nhân beta có thể gọi các công cụ bên ngoài—từ môi trường thực thi mã đến trình thu thập dữ liệu web—dưới lớp vỏ. Các nhà phát triển có thể khởi tạo một phiên tác nhân liên kết lý luận mô hình với lệnh gọi công cụ, ví dụ, để truy xuất dữ liệu thời gian thực, thực hiện tính toán hoặc cập nhật cơ sở dữ liệu. Mô hình tác nhân này đơn giản hóa quá trình phát triển ứng dụng đầu cuối, cho phép MiniMax-M1 hoạt động như một bộ điều phối trong các quy trình làm việc phức tạp.
Thực hành tốt nhất và cạm bẫy
- Kỹ thuật nhanh chóng cho các bối cảnh dài: Chia dữ liệu đầu vào thành các phân đoạn mạch lạc, nhúng các bản tóm tắt theo các khoảng thời gian hợp lý và sử dụng các chiến lược "tóm tắt sau đó lý giải" để duy trì trọng tâm của mô hình.
- Sự đánh đổi giữa tính toán và hiệu suất:Thử nghiệm với ngưỡng chuyên gia thấp hơn hoặc giảm ngân sách suy nghĩ (ví dụ: biến thể 40K) cho các ứng dụng nhạy cảm với độ trễ.
- Giám sát và quản lý:Sử dụng nhật ký định tuyến và số liệu thống kê mã thông báo để kiểm tra việc sử dụng chuyên gia và đảm bảo tuân thủ ngân sách chi phí, đặc biệt là trong môi trường sản xuất.
Bằng cách tuân theo các hướng dẫn này, các nhà phát triển có thể khai thác thế mạnh của MiniMax-M1 - khả năng xử lý ngữ cảnh rộng lớn và suy luận hiệu quả - đồng thời giảm thiểu rủi ro liên quan đến việc triển khai mô hình quy mô lớn.
Sử dụng MiniMax-M1 như thế nào?
Sau khi cài đặt, M1 có thể được gọi thông qua các tập lệnh Python đơn giản hoặc sổ ghi chép tương tác.
Một tập lệnh suy luận cơ bản trông như thế nào?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Mẫu này gọi biến thể ngân sách 40 k; hoán đổi thành "MiniMax-AI/MiniMax-M1-80k" mở khóa toàn bộ ngân sách lý luận 80k ().
Bạn xử lý các bối cảnh siêu dài như thế nào?
Đối với các đầu vào vượt quá kích thước bộ đệm thông thường, M1 hỗ trợ mã hóa luồng. Sử dụng stream=True cờ trong trình phân tích mã thông báo để đưa mã thông báo vào từng phần và tận dụng suy luận khởi động lại điểm kiểm tra để duy trì hiệu suất trên các chuỗi hàng triệu mã thông báo.
Bạn có thể tinh chỉnh hoặc điều chỉnh M1 như thế nào?
Trong khi các điểm kiểm tra cơ sở đủ cho hầu hết các tác vụ, các nhà nghiên cứu có thể áp dụng tinh chỉnh RL bằng cách sử dụng mã CISPO có trong kho lưu trữ. Bằng cách cung cấp các hàm phần thưởng tùy chỉnh—từ độ chính xác của mã đến độ trung thực về mặt ngữ nghĩa—các học viên có thể điều chỉnh M1 cho các quy trình làm việc cụ thể theo miền.
Kết luận
MiniMax-M1 nổi bật như một mô hình AI mang tính đột phá, mở rộng ranh giới của sự hiểu biết và lý luận ngôn ngữ ngữ cảnh dài. Với kiến trúc MoE lai, cơ chế chú ý chớp nhoáng và chế độ đào tạo được CISPO hỗ trợ, mô hình này mang lại hiệu suất cao cho các tác vụ từ phân tích pháp lý đến kỹ thuật phần mềm, đồng thời giảm đáng kể chi phí tính toán. Nhờ bản phát hành có trọng lượng mở và các dịch vụ API đám mây, MiniMax-M1 có thể tiếp cận được với nhiều nhà phát triển và tổ chức mong muốn xây dựng các ứng dụng hỗ trợ AI thế hệ tiếp theo. Khi cộng đồng AI tiếp tục khám phá tiềm năng của các mô hình ngữ cảnh lớn, những cải tiến của MiniMax-M1 đang sẵn sàng tác động đến nghiên cứu trong tương lai và phát triển sản phẩm trên toàn ngành.
Bắt đầu
CometAPI cung cấp giao diện REST thống nhất tổng hợp hàng trăm mô hình AI—bao gồm cả họ ChatGPT—dưới một điểm cuối nhất quán, với quản lý khóa API tích hợp, hạn ngạch sử dụng và bảng điều khiển thanh toán. Thay vì phải xử lý nhiều URL và thông tin xác thực của nhà cung cấp.
Để bắt đầu, hãy khám phá khả năng của các mô hình trong Sân chơi và tham khảo ý kiến Hướng dẫn API để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập vào CometAPI và lấy được khóa API.
API MiniMax‑M1 tích hợp mới nhất sẽ sớm xuất hiện trên CometAPI, vì vậy hãy theo dõi! Trong khi chúng tôi hoàn thiện việc tải lên Mô hình MiniMax‑M1, hãy khám phá các mô hình khác của chúng tôi trên Trang mô hình hoặc thử chúng trong sân chơi trí tuệ nhân tạo. Mô hình mới nhất của MiniMax trong CometAPI là Minimax ABAB7-API xem trước và API MiniMax Video-01 ,tham khảo:
