Claude Haiku 4.5 is a purpose-optimized, smaller-class language model from Anthropic, released in mid-October 2025. It’s positioned as a fast, low-cost option in the Claude lineup that preserves strong capability on tasks like coding, agent orchestration, and interactive “computer-use” workflows while enabling much higher throughput and lower unit cost for enterprise deployments.
Key features
- Speed & cost-efficiency: Haiku 4.5 is described as more than twice as fast as Sonnet 4 and about one-third the cost of Sonnet 4 (and much cheaper than Opus), making it attractive for scaled usage.
- Extended thinking: First Haiku model to support extended thinking (summarized / interleaved thought, configurable thinking budgets) for deeper multi-step reasoning while balancing latency.
- Tools & computer use: Full support for Claude tools (bash, code execution, text editor, web search, and computer-use automation). Designed for agentic workflows and sub-agent architectures.
- Large context window: 200k token context window (with 1M context options available on larger models as beta for other model classes).
Technical details
- Training data & cutoff: Haiku 4.5 was trained on a proprietary mix of public and licensed data with a training cutoff around February 2025.
- Extended-thinking (a hybrid reasoning mode) is supported so the model can trade latency for deeper reasoning when requested.
- Context window at release is 200,000 tokens, and the model is explicitly context-aware (it tracks how much of the window has been used).
- Performance / throughput: Early community reports and Anthropic testing cite very high OTPS (output tokens/sec) and anecdotal speeds around ~200+ tokens/sec in some internal/early tests —far faster than many comparable mid-tier models.
Benchmark performance
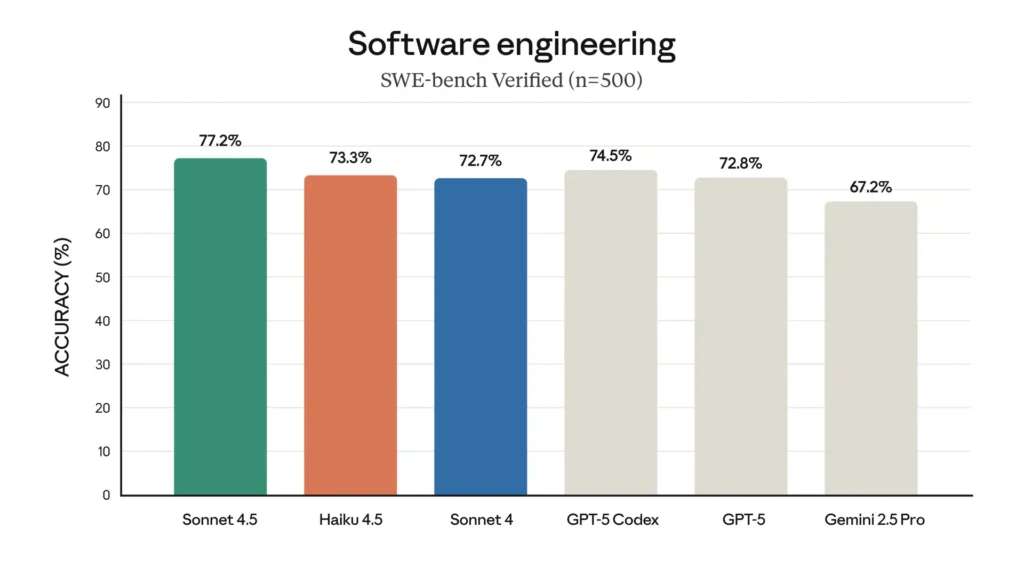
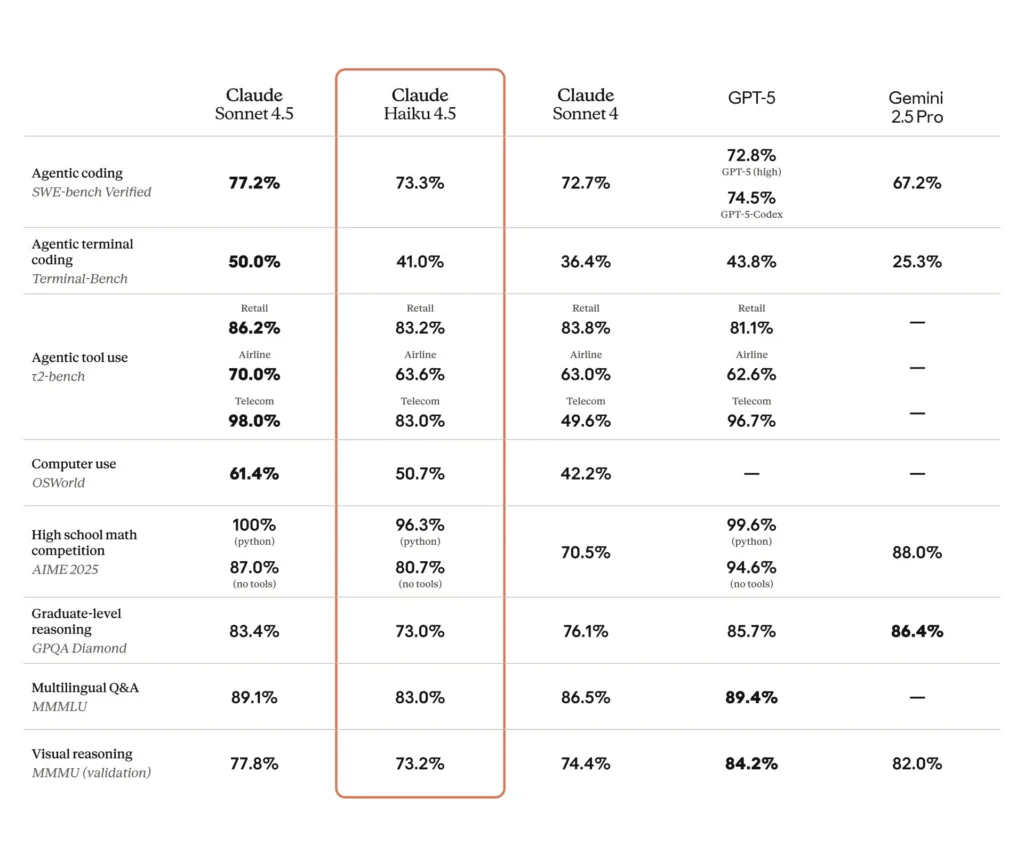
SWE-Bench (coding): Haiku 4.5 scored ~73.3% on SWE-Bench Verified — a result Anthropic highlights as placing Haiku 4.5 among the world’s best coding models for its class.
Terminal / command-line / tool tests: Anthropic reported ~41% on Terminal-Bench (command-line focused) and comparable results to Sonnet 4 and several competing mid-range frontier models on many tool-use benchmarks.
Instruction-following & slide text: internal Anthropic examples claim Haiku 4.5 outperformed previous models on some instruction-following tasks (e.g., slide text generation: 65% vs 44% for a prior premium model in their benchmark).
Real-world automation / agent tasks: third-party evaluations and early adopters report competitive success rates on automated UI/agent tasks (for example, OSWorld-style or agent benchmarks reporting ≈50% success on complex automation in some tests), showing usefulness for scaled workflows though with nontrivial failure modes.
Limitations & safety notes
- Not a frontier model: Anthropic explicitly classifies Haiku 4.5 as not frontier-advancing; it is optimized for efficiency rather than pushing the absolute state of the art. (Anthropic)
- Occasional sensitive-topic behavior: in some scientific / bio-safety related prompts Haiku 4.5 sometimes returns high-level information with caveats rather than strict refusals; Anthropic flags that as an area under ongoing improvement.
- Extended-thinking can change behavior (it sometimes increases asymmetry in responses).
Recommended use cases
- Agentic coding & multi-agent orchestration: fast sub-agents, iterative code refactor, autotests and patch generation. (Good fit.)
- Real-time, high-volume customer workflows: chat assistants, internal automation where cost-per-request matters. (Good fit.)
- Tool-enabled workflows & computer control: automating GUI/CLI tasks, document workflows and tool chains where low latency helps. (Good fit.)
- Not recommended (without controls): standalone roles that require frontier-level scientific sequence design or high-assurance biosecurity tasks. (Exercise caution.)